 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDS: A Cross-cultural Dialogue Corpus for Social Norm Classification and Adherence Detection
Nov 13, 2025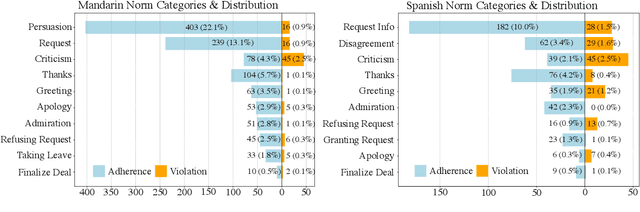
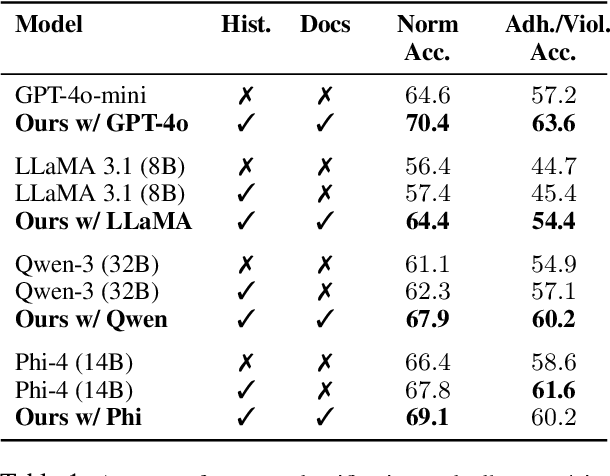
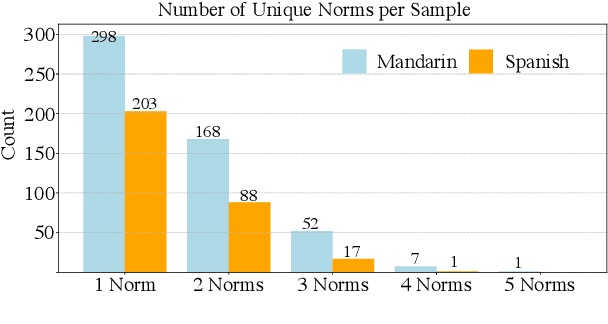
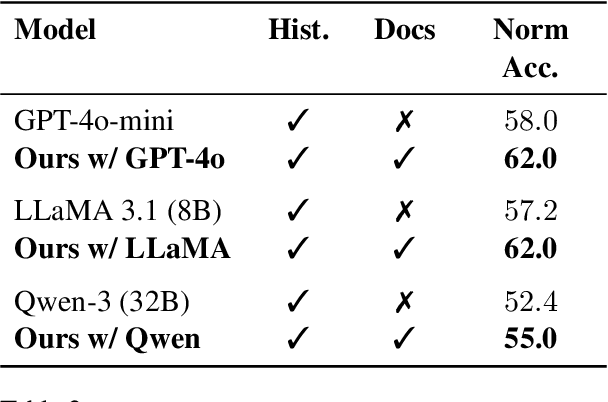
Social norms are implicit, culturally grounded expectations that guide interpersonal communication. Unlike factual commonsense, norm reasoning is subjective, context-dependent, and varies across cultures, posing challenges for computational models. Prior works provide valuable normative annotations but mostly target isolated utterances or synthetic dialogues, limiting their ability to capture the fluid, multi-turn nature of real-world conversations. In this work, we present Norm-RAG, a retrieval-augmented, agentic framework for nuanced social norm inference in multi-turn dialogues. Norm-RAG models utterance-level attributes including communicative intent, speaker roles, interpersonal framing, and linguistic cues and grounds them in structured normative documentation retrieved via a novel Semantic Chunking approach. This enables interpretable and context-aware reasoning about norm adherence and violation across multilingual dialogues. We further introduce MINDS (Multilingual Interactions with Norm-Driven Speech), a bilingual dataset comprising 31 multi-turn Mandarin-English and Spanish-English conversations. Each turn is annotated for norm category and adherence status using multi-annotator consensus, reflecting cross-cultural and realistic norm expression. Our experiments show that Norm-RAG improves norm detection and generalization, demonstrates improved performance for culturally adaptive and socially intelligent dialogue systems.
Demonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning
Oct 16, 2023



Paraphrasing of offensive content is a better alternative to content removal and helps improve civility in a communication environment. Supervised paraphrasers; however, rely heavily on large quantities of labelled data to help preserve meaning and intent. They also retain a large portion of the offensiveness of the original content, which raises questions on their overall usability. In this paper we aim to assist practitioners in developing usable paraphrasers by exploring In-Context Learning (ICL) with large language models (LLMs), i.e., using a limited number of input-label demonstration pairs to guide the model in generating desired outputs for specific queries. Our study focuses on key factors such as -- number and order of demonstrations, exclusion of prompt instruction, and reduction in measured toxicity. We perform principled evaluation on three datasets, including our proposed Context-Aware Polite Paraphrase dataset, comprising of dialogue-style rude utterances, polite paraphrases, and additional dialogue context. We evaluate our approach using two closed source and one open source LLM. Our results reveal that ICL is comparable to supervised methods in generation quality, while being qualitatively better by 25% on human evaluation and attaining lower toxicity by 76%. Also, ICL-based paraphrasers only show a slight reduction in performance even with just 10% training data.
Role of Data Augmentation Strategies in Knowledge Distillation for Wearable Sensor Data
Jan 01, 2022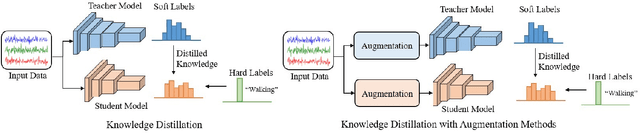
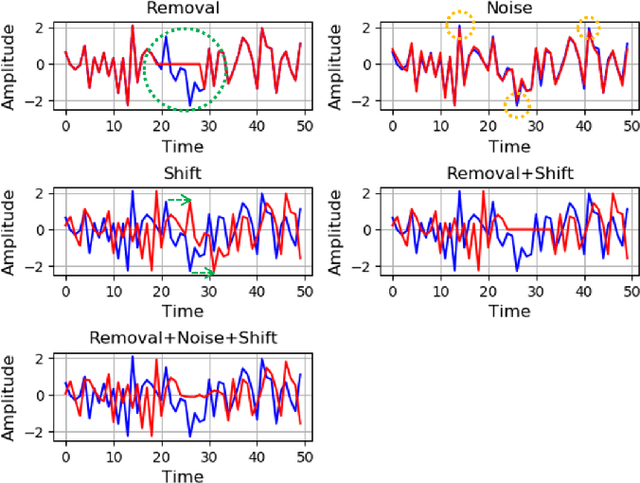
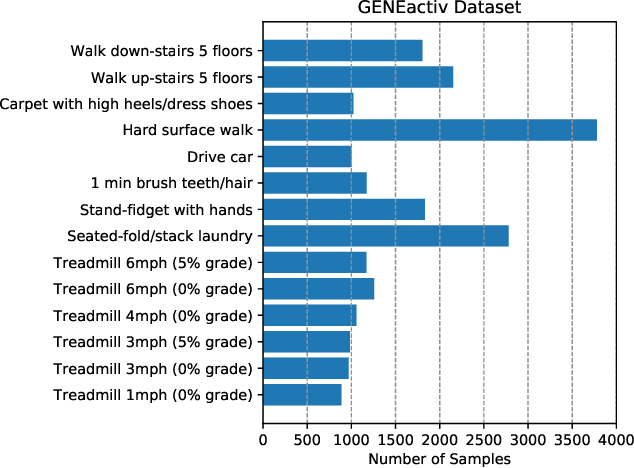
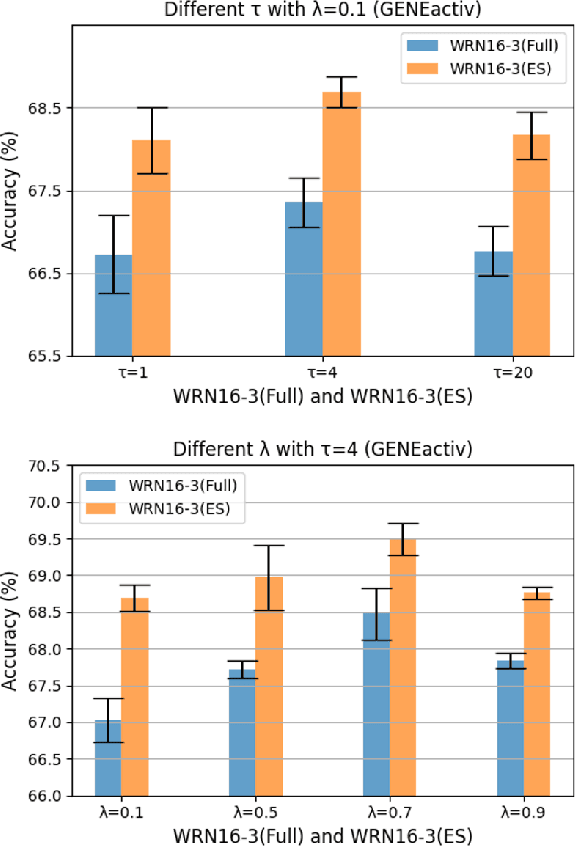
Deep neural networks are parametrized by several thousands or millions of parameters, and have shown tremendous success in many classification problems. However, the large number of parameters makes it difficult to integrate these models into edge devices such as smartphones and wearable devices. To address this problem, knowledge distillation (KD) has been widely employed, that uses a pre-trained high capacity network to train a much smaller network, suitable for edge devices. In this paper, for the first time, we study the applicability and challenges of using KD for time-series data for wearable devices. Successful application of KD requires specific choices of data augmentation methods during training. However, it is not yet known if there exists a coherent strategy for choosing an augmentation approach during KD. In this paper, we report the results of a detailed study that compares and contrasts various common choices and some hybrid data augmentation strategies in KD based human activity analysis. Research in this area is often limited as there are not many comprehensive databases available in the public domain from wearable devices. Our study considers databases from small scale publicly available to one derived from a large scale interventional study into human activity and sedentary behavior. We find that the choice of data augmentation techniques during KD have a variable level of impact on end performance, and find that the optimal network choice as well as data augmentation strategies are specific to a dataset at hand. However, we also conclude with a general set of recommendations that can provide a strong baseline performance across databases.
Towards Explainable Student Group Collaboration Assessment Models Using Temporal Representations of Individual Student Roles
Jun 17, 2021
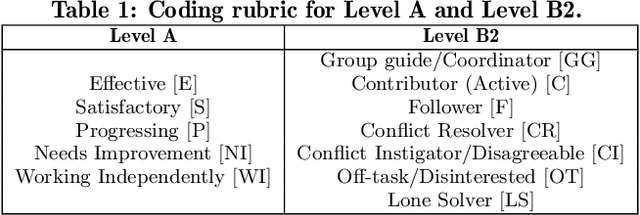

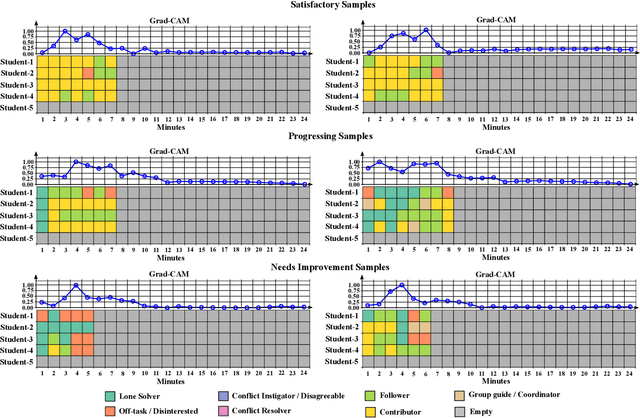
Collaboration is identified as a required and necessary skill for students to be successful in the fields of Science, Technology, Engineering and Mathematics (STEM). However, due to growing student population and limited teaching staff it is difficult for teachers to provide constructive feedback and instill collaborative skills using instructional methods. Development of simple and easily explainable machine-learning-based automated systems can help address this problem. Improving upon our previous work, in this paper we propose using simple temporal-CNN deep-learning models to assess student group collaboration that take in temporal representations of individual student roles as input. We check the applicability of dynamically changing feature representations for student group collaboration assessment and how they impact the overall performance. We also use Grad-CAM visualizations to better understand and interpret the important temporal indices that led to the deep-learning model's decision.
Interpretable COVID-19 Chest X-Ray Classification via Orthogonality Constraint
Feb 02, 2021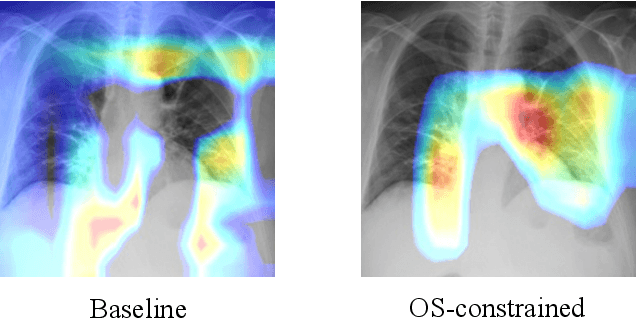
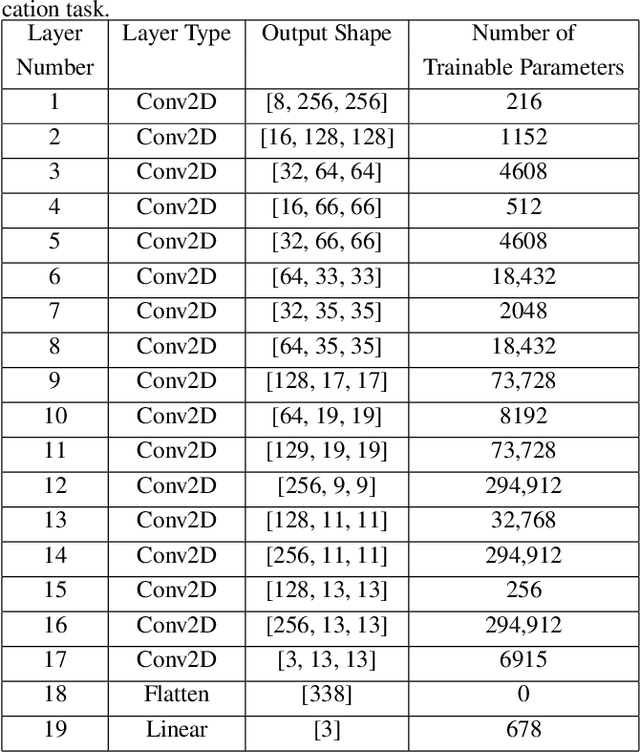
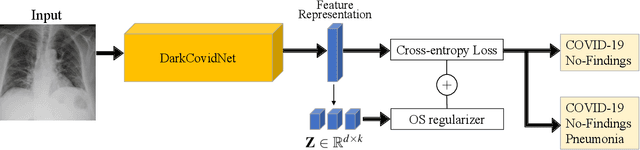

Deep neural networks have increasingly been used as an auxiliary tool in healthcare applications, due to their ability to improve performance of several diagnosis tasks. However, these methods are not widely adopted in clinical settings due to the practical limitations in the reliability, generalizability, and interpretability of deep learning based systems. As a result, methods have been developed that impose additional constraints during network training to gain more control as well as improve interpretabilty, facilitating their acceptance in healthcare community. In this work, we investigate the benefit of using Orthogonal Spheres (OS) constraint for classification of COVID-19 cases from chest X-ray images. The OS constraint can be written as a simple orthonormality term which is used in conjunction with the standard cross-entropy loss during classification network training. Previous studies have demonstrated significant benefits in applying such constraints to deep learning models. Our findings corroborate these observations, indicating that the orthonormality loss function effectively produces improved semantic localization via GradCAM visualizations, enhanced classification performance, and reduced model calibration error. Our approach achieves an improvement in accuracy of 1.6% and 4.8% for two- and three-class classification, respectively; similar results are found for models with data augmentation applied. In addition to these findings, our work also presents a new application of the OS regularizer in healthcare, increasing the post-hoc interpretability and performance of deep learning models for COVID-19 classification to facilitate adoption of these methods in clinical settings. We also identify the limitations of our strategy that can be explored for further research in future.
Role of Orthogonality Constraints in Improving Properties of Deep Networks for Image Classification
Sep 22, 2020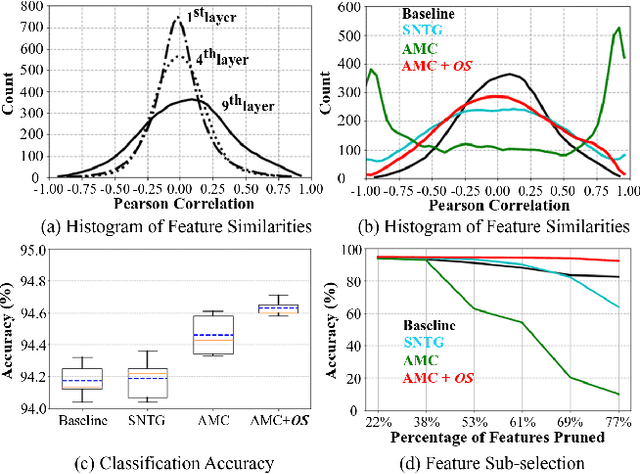
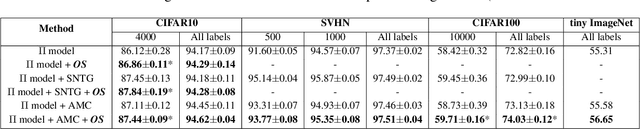
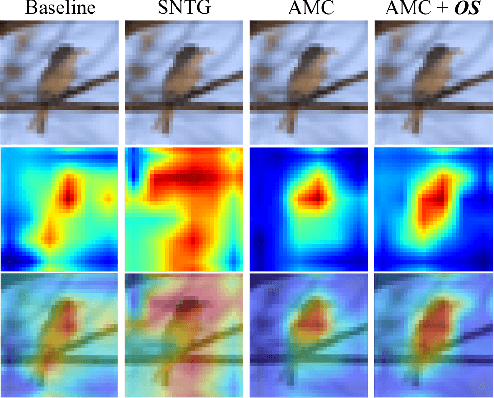

Standard deep learning models that employ the categorical cross-entropy loss are known to perform well at image classification tasks. However, many standard models thus obtained often exhibit issues like feature redundancy, low interpretability, and poor calibration. A body of recent work has emerged that has tried addressing some of these challenges by proposing the use of new regularization functions in addition to the cross-entropy loss. In this paper, we present some surprising findings that emerge from exploring the role of simple orthogonality constraints as a means of imposing physics-motivated constraints common in imaging. We propose an Orthogonal Sphere (OS) regularizer that emerges from physics-based latent-representations under simplifying assumptions. Under further simplifying assumptions, the OS constraint can be written in closed-form as a simple orthonormality term and be used along with the cross-entropy loss function. The findings indicate that orthonormality loss function results in a) rich and diverse feature representations, b) robustness to feature sub-selection, c) better semantic localization in the class activation maps, and d) reduction in model calibration error. We demonstrate the effectiveness of the proposed OS regularization by providing quantitative and qualitative results on four benchmark datasets - CIFAR10, CIFAR100, SVHN and tiny ImageNet.
A Machine Learning Approach to Assess Student Group Collaboration Using Individual Level Behavioral Cues
Aug 05, 2020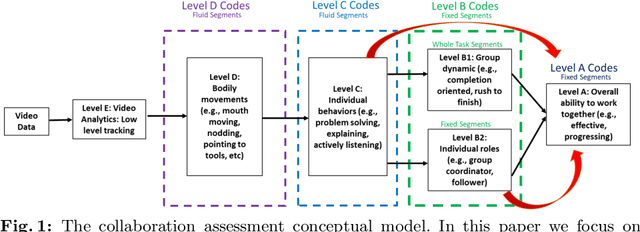


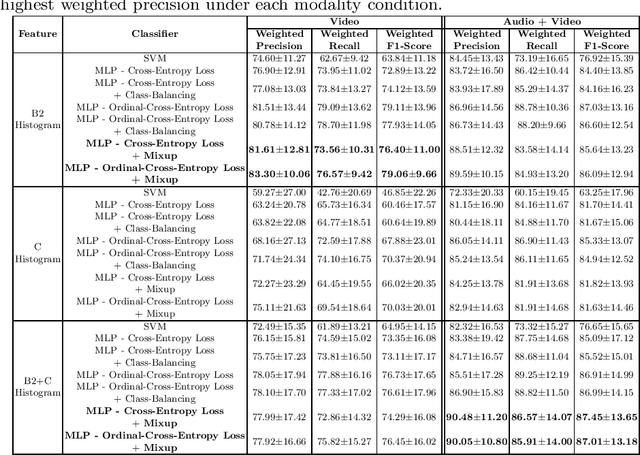
K-12 classrooms consistently integrate collaboration as part of their learning experiences. However, owing to large classroom sizes, teachers do not have the time to properly assess each student and give them feedback. In this paper we propose using simple deep-learning-based machine learning models to automatically determine the overall collaboration quality of a group based on annotations of individual roles and individual level behavior of all the students in the group. We come across the following challenges when building these models: 1) Limited training data, 2) Severe class label imbalance. We address these challenges by using a controlled variant of Mixup data augmentation, a method for generating additional data samples by linearly combining different pairs of data samples and their corresponding class labels. Additionally, the label space for our problem exhibits an ordered structure. We take advantage of this fact and also explore using an ordinal-cross-entropy loss function and study its effects with and without Mixup.
Unsupervised Pre-trained Models from Healthy ADLs Improve Parkinson's Disease Classification of Gait Patterns
May 07, 2020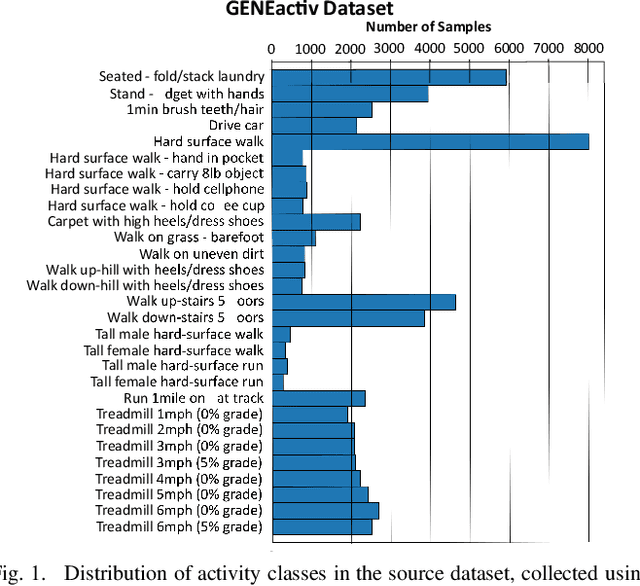
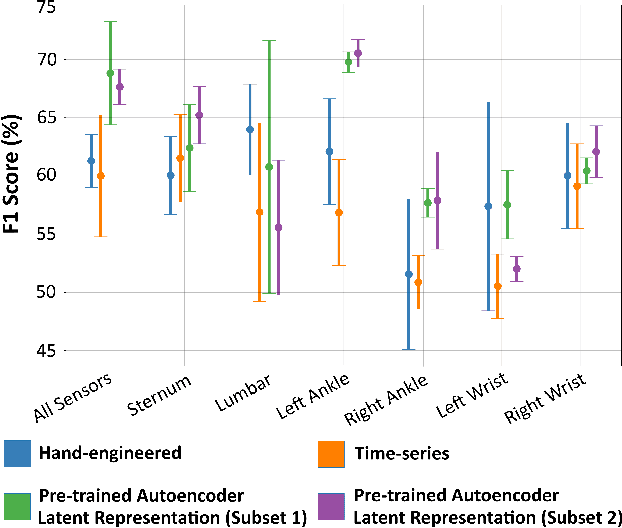
Application and use of deep learning algorithms for different healthcare applications is gaining interest at a steady pace. However, use of such algorithms can prove to be challenging as they require large amounts of training data that capture different possible variations. This makes it difficult to use them in a clinical setting since in most health applications researchers often have to work with limited data. Less data can cause the deep learning model to over-fit. In this paper, we ask how can we use data from a different environment, different use-case, with widely differing data distributions. We exemplify this use case by using single-sensor accelerometer data from healthy subjects performing activities of daily living - ADLs (source dataset), to extract features relevant to multi-sensor accelerometer gait data (target dataset) for Parkinson's disease classification. We train the pre-trained model using the source dataset and use it as a feature extractor. We show that the features extracted for the target dataset can be used to train an effective classification model. Our pre-trained source model consists of a convolutional autoencoder, and the target classification model is a simple multi-layer perceptron model. We explore two different pre-trained source models, trained using different activity groups, and analyze the influence the choice of pre-trained model has over the task of Parkinson's disease classification.
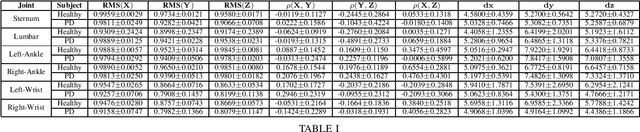
Topological Descriptors for Parkinson's Disease Classification and Regression Analysis
May 06, 2020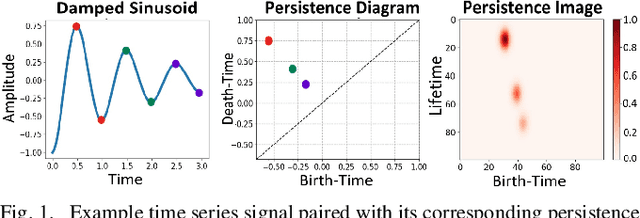
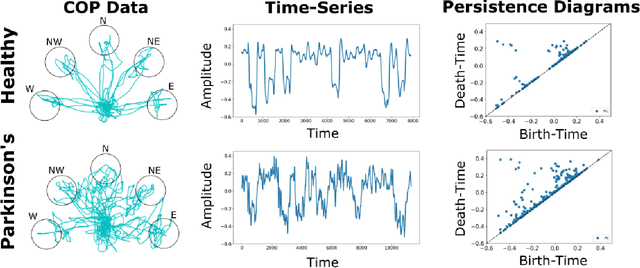
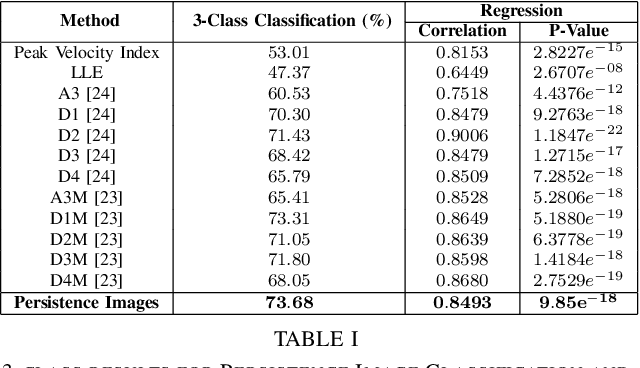
At present, the vast majority of human subjects with neurological disease are still diagnosed through in-person assessments and qualitative analysis of patient data. In this paper, we propose to use Topological Data Analysis (TDA) together with machine learning tools to automate the process of Parkinson's disease classification and severity assessment. An automated, stable, and accurate method to evaluate Parkinson's would be significant in streamlining diagnoses of patients and providing families more time for corrective measures. We propose a methodology which incorporates TDA into analyzing Parkinson's disease postural shifts data through the representation of persistence images. Studying the topology of a system has proven to be invariant to small changes in data and has been shown to perform well in discrimination tasks. The contributions of the paper are twofold. We propose a method to 1) classify healthy patients from those afflicted by disease and 2) diagnose the severity of disease. We explore the use of the proposed method in an application involving a Parkinson's disease dataset comprised of healthy-elderly, healthy-young and Parkinson's disease patients. Our code is available at https://github.com/itsmeafra/Sublevel-Set-TDA.
AMC-Loss: Angular Margin Contrastive Loss for Improved Explainability in Image Classification
Apr 21, 2020
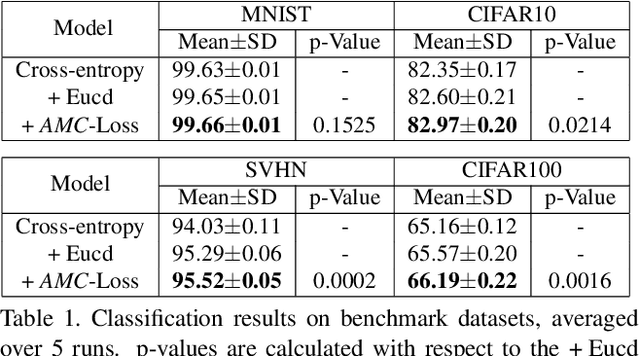
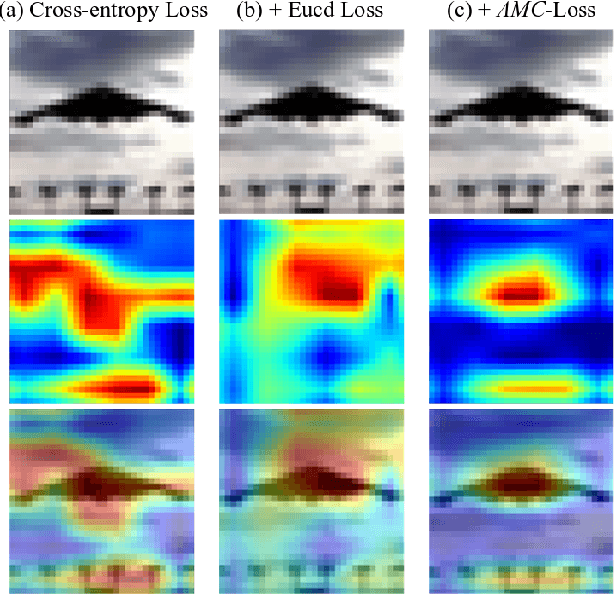

Deep-learning architectures for classification problems involve the cross-entropy loss sometimes assisted with auxiliary loss functions like center loss, contrastive loss and triplet loss. These auxiliary loss functions facilitate better discrimination between the different classes of interest. However, recent studies hint at the fact that these loss functions do not take into account the intrinsic angular distribution exhibited by the low-level and high-level feature representations. This results in less compactness between samples from the same class and unclear boundary separations between data clusters of different classes. In this paper, we address this issue by proposing the use of geometric constraints, rooted in Riemannian geometry. Specifically, we propose Angular Margin Contrastive Loss (AMC-Loss), a new loss function to be used along with the traditional cross-entropy loss. The AMC-Loss employs the discriminative angular distance metric that is equivalent to geodesic distance on a hypersphere manifold such that it can serve a clear geometric interpretation. We demonstrate the effectiveness of AMC-Loss by providing quantitative and qualitative results. We find that although the proposed geometrically constrained loss-function improves quantitative results modestly, it has a qualitatively surprisingly beneficial effect on increasing the interpretability of deep-net decisions as seen by the visual explanations generated by techniques such as the Grad-CAM. Our code is available at https://github.com/hchoi71/AMC-Loss.