 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pre-trained Models from Healthy ADLs Improve Parkinson's Disease Classification of Gait Patterns
Paper and Code
May 07, 2020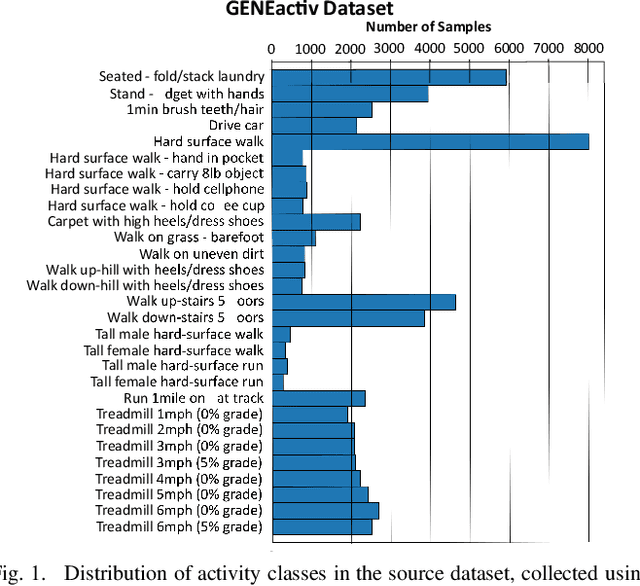
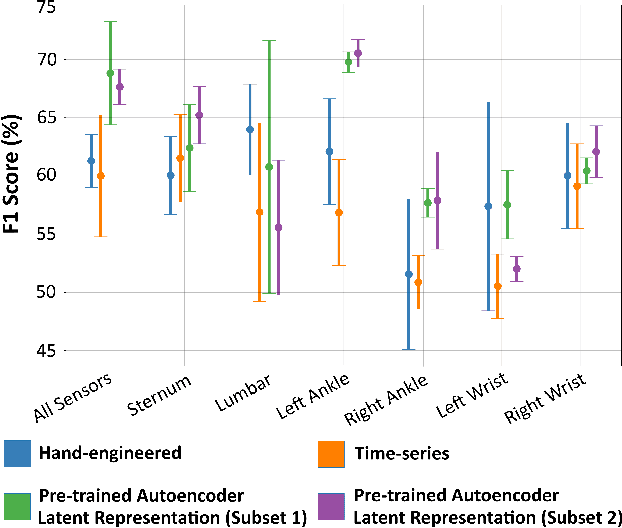
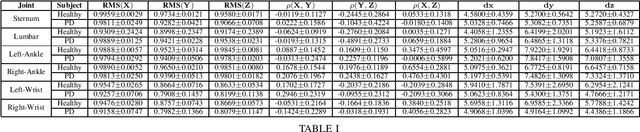
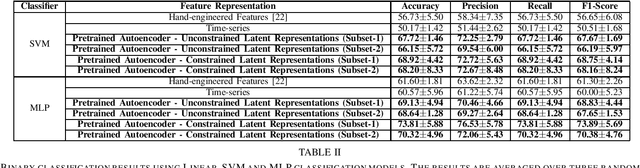
Application and use of deep learning algorithms for different healthcare applications is gaining interest at a steady pace. However, use of such algorithms can prove to be challenging as they require large amounts of training data that capture different possible variations. This makes it difficult to use them in a clinical setting since in most health applications researchers often have to work with limited data. Less data can cause the deep learning model to over-fit. In this paper, we ask how can we use data from a different environment, different use-case, with widely differing data distributions. We exemplify this use case by using single-sensor accelerometer data from healthy subjects performing activities of daily living - ADLs (source dataset), to extract features relevant to multi-sensor accelerometer gait data (target dataset) for Parkinson's disease classification. We train the pre-trained model using the source dataset and use it as a feature extractor. We show that the features extracted for the target dataset can be used to train an effective classification model. Our pre-trained source model consists of a convolutional autoencoder, and the target classification model is a simple multi-layer perceptron model. We explore two different pre-trained source models, trained using different activity groups, and analyze the influence the choice of pre-trained model has over the task of Parkinson's disease classification.