 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning
Oct 16, 2023



Paraphrasing of offensive content is a better alternative to content removal and helps improve civility in a communication environment. Supervised paraphrasers; however, rely heavily on large quantities of labelled data to help preserve meaning and intent. They also retain a large portion of the offensiveness of the original content, which raises questions on their overall usability. In this paper we aim to assist practitioners in developing usable paraphrasers by exploring In-Context Learning (ICL) with large language models (LLMs), i.e., using a limited number of input-label demonstration pairs to guide the model in generating desired outputs for specific queries. Our study focuses on key factors such as -- number and order of demonstrations, exclusion of prompt instruction, and reduction in measured toxicity. We perform principled evaluation on three datasets, including our proposed Context-Aware Polite Paraphrase dataset, comprising of dialogue-style rude utterances, polite paraphrases, and additional dialogue context. We evaluate our approach using two closed source and one open source LLM. Our results reveal that ICL is comparable to supervised methods in generation quality, while being qualitatively better by 25% on human evaluation and attaining lower toxicity by 76%. Also, ICL-based paraphrasers only show a slight reduction in performance even with just 10% training data.
Widening the Dialogue Workflow Modeling Bottleneck in Ontology-Based Personal Assistants
Nov 16, 2020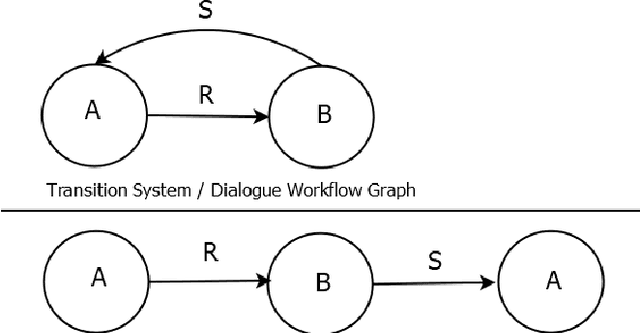

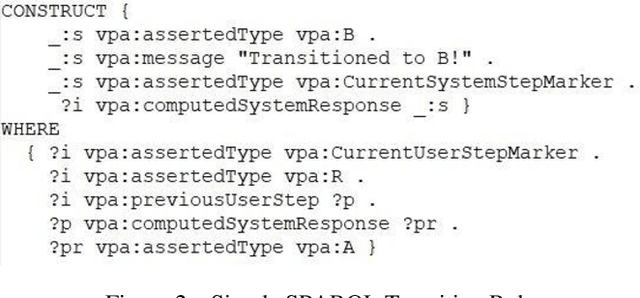

We present a new approach to dialogue specification for Virtual Personal Assistants (VPAs) based on so-called dialogue workflow graphs, with several demonstrated advantages over current ontology-based methods. Our new dialogue specification language (DSL) enables customers to more easily participate in the VPA modeling process due to a user-friendly modeling framework. Resulting models are also significantly more compact. VPAs can be developed much more rapidly. The DSL is a new modeling layer on top of our ontology-based Dialogue Management (DM) framework OntoVPA. We explain the rationale and benefits behind the new language and support our claims with concrete reduced Level-of-Effort (LOE) numbers from two recent OntoVPA projects.