 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDS: A Cross-cultural Dialogue Corpus for Social Norm Classification and Adherence Detection
Nov 13, 2025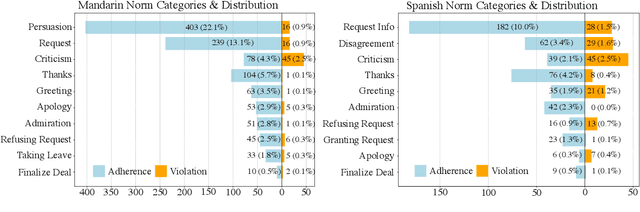
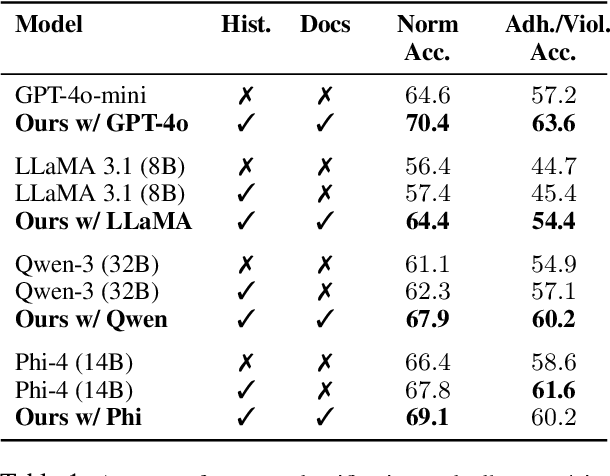
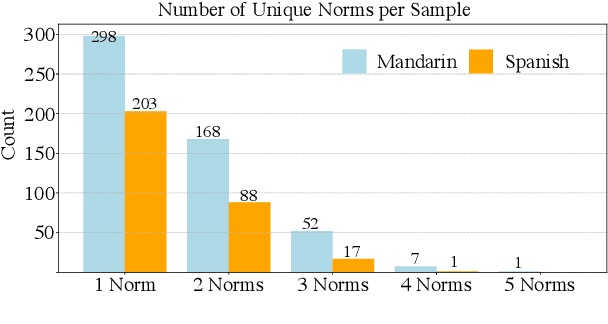
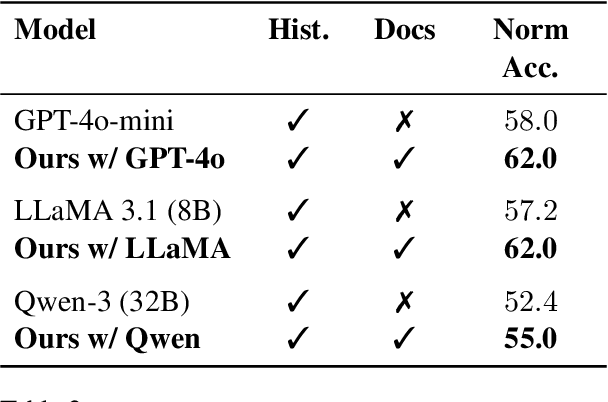
Social norms are implicit, culturally grounded expectations that guide interpersonal communication. Unlike factual commonsense, norm reasoning is subjective, context-dependent, and varies across cultures, posing challenges for computational models. Prior works provide valuable normative annotations but mostly target isolated utterances or synthetic dialogues, limiting their ability to capture the fluid, multi-turn nature of real-world conversations. In this work, we present Norm-RAG, a retrieval-augmented, agentic framework for nuanced social norm inference in multi-turn dialogues. Norm-RAG models utterance-level attributes including communicative intent, speaker roles, interpersonal framing, and linguistic cues and grounds them in structured normative documentation retrieved via a novel Semantic Chunking approach. This enables interpretable and context-aware reasoning about norm adherence and violation across multilingual dialogues. We further introduce MINDS (Multilingual Interactions with Norm-Driven Speech), a bilingual dataset comprising 31 multi-turn Mandarin-English and Spanish-English conversations. Each turn is annotated for norm category and adherence status using multi-annotator consensus, reflecting cross-cultural and realistic norm expression. Our experiments show that Norm-RAG improves norm detection and generalization, demonstrates improved performance for culturally adaptive and socially intelligent dialogue systems.
Document Understanding, Measurement, and Manipulation Using Category Theory
Oct 24, 2025We apply category theory to extract multimodal document structure which leads us to develop information theoretic measures, content summarization and extension, and self-supervised improvement of large pretrained models. We first develop a mathematical representation of a document as a category of question-answer pairs. Second, we develop an orthogonalization procedure to divide the information contained in one or more documents into non-overlapping pieces. The structures extracted in the first and second steps lead us to develop methods to measure and enumerate the information contained in a document. We also build on those steps to develop new summarization techniques, as well as to develop a solution to a new problem viz. exegesis resulting in an extension of the original document. Our question-answer pair methodology enables a novel rate distortion analysis of summarization techniques. We implement our techniques using large pretrained models, and we propose a multimodal extension of our overall mathematical framework. Finally, we develop a novel self-supervised method using RLVR to improve large pretrained models using consistency constraints such as composability and closure under certain operations that stem naturally from our category theoretic framework.
Punching Bag vs. Punching Person: Motion Transferability in Videos
Jul 31, 2025Action recognition models demonstrate strong generalization, but can they effectively transfer high-level motion concepts across diverse contexts, even within similar distributions? For example, can a model recognize the broad action "punching" when presented with an unseen variation such as "punching person"? To explore this, we introduce a motion transferability framework with three datasets: (1) Syn-TA, a synthetic dataset with 3D object motions; (2) Kinetics400-TA; and (3) Something-Something-v2-TA, both adapted from natural video datasets. We evaluate 13 state-of-the-art models on these benchmarks and observe a significant drop in performance when recognizing high-level actions in novel contexts. Our analysis reveals: 1) Multimodal models struggle more with fine-grained unknown actions than with coarse ones; 2) The bias-free Syn-TA proves as challenging as real-world datasets, with models showing greater performance drops in controlled settings; 3) Larger models improve transferability when spatial cues dominate but struggle with intensive temporal reasoning, while reliance on object and background cues hinders generalization. We further explore how disentangling coarse and fine motions can improve recognition in temporally challenging datasets. We believe this study establishes a crucial benchmark for assessing motion transferability in action recognition. Datasets and relevant code: https://github.com/raiyaan-abdullah/Motion-Transfer.
The Influence of Text Variation on User Engagement in Cross-Platform Content Sharing
Apr 26, 2025In today's cross-platform social media landscape, understanding factors that drive engagement for multimodal content, especially text paired with visuals, remains complex. This study investigates how rewriting Reddit post titles adapted from YouTube video titles affects user engagement. First, we build and analyze a large dataset of Reddit posts sharing YouTube videos, revealing that 21% of post titles are minimally modified. Statistical analysis demonstrates that title rewrites measurably improve engagement. Second, we design a controlled, multi-phase experiment to rigorously isolate the effects of textual variations by neutralizing confounding factors like video popularity, timing, and community norms. Comprehensive statistical tests reveal that effective title rewrites tend to feature emotional resonance, lexical richness, and alignment with community-specific norms. Lastly, pairwise ranking prediction experiments using a fine-tuned BERT classifier achieves 74% accuracy, significantly outperforming near-random baselines, including GPT-4o. These results validate that our controlled dataset effectively minimizes confounding effects, allowing advanced models to both learn and demonstrate the impact of textual features on engagement. By bridging quantitative rigor with qualitative insights, this study uncovers engagement dynamics and offers a robust framework for future cross-platform, multimodal content strategies.
Pelican: Correcting Hallucination in Vision-LLMs via Claim Decomposition and Program of Thought Verification
Jul 02, 2024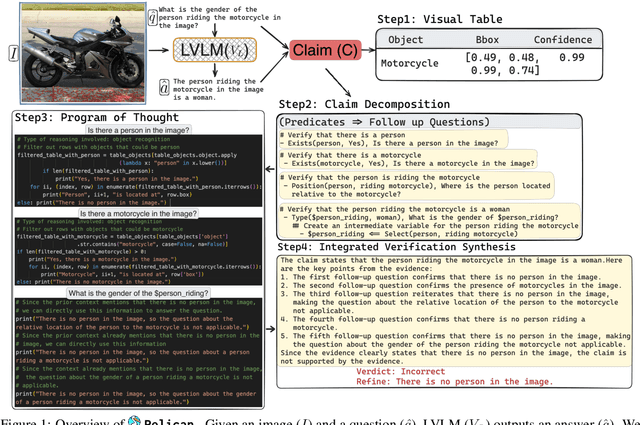
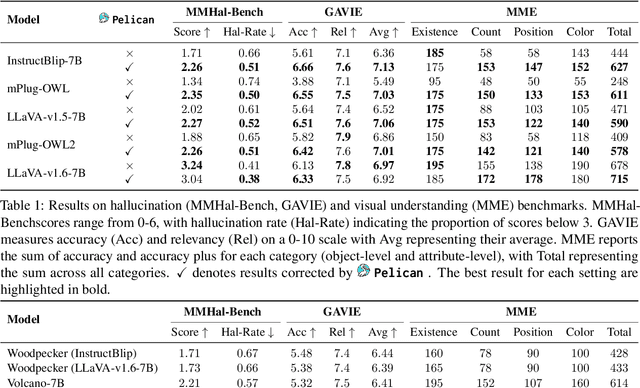
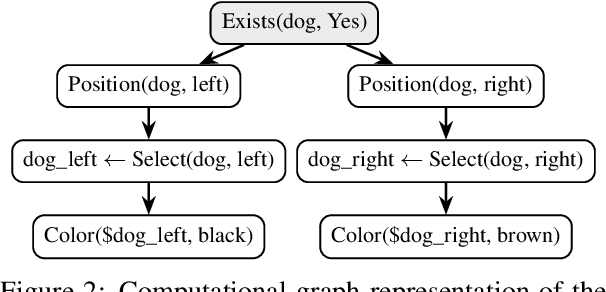

Large Visual Language Models (LVLMs) struggle with hallucinations in visual instruction following task(s), limiting their trustworthiness and real-world applicability. We propose Pelican -- a novel framework designed to detect and mitigate hallucinations through claim verification. Pelican first decomposes the visual claim into a chain of sub-claims based on first-order predicates. These sub-claims consist of (predicate, question) pairs and can be conceptualized as nodes of a computational graph. We then use Program-of-Thought prompting to generate Python code for answering these questions through flexible composition of external tools. Pelican improves over prior work by introducing (1) intermediate variables for precise grounding of object instances, and (2) shared computation for answering the sub-question to enable adaptive corrections and inconsistency identification. We finally use reasoning abilities of LLM to verify the correctness of the the claim by considering the consistency and confidence of the (question, answer) pairs from each sub-claim. Our experiments reveal a drop in hallucination rate by $\sim$8%-32% across various baseline LVLMs and a 27% drop compared to approaches proposed for hallucination mitigation on MMHal-Bench. Results on two other benchmarks further corroborate our results.
Empowering Interdisciplinary Insights with Dynamic Graph Embedding Trajectories
Jun 25, 2024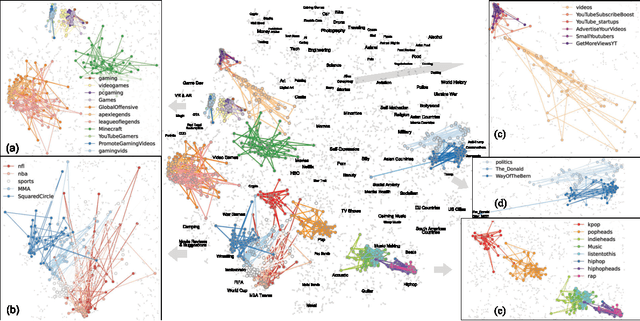
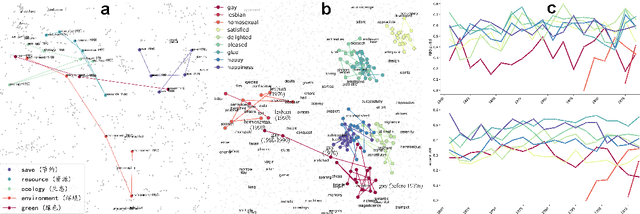
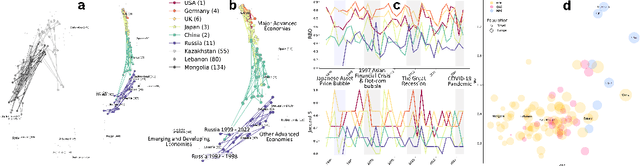
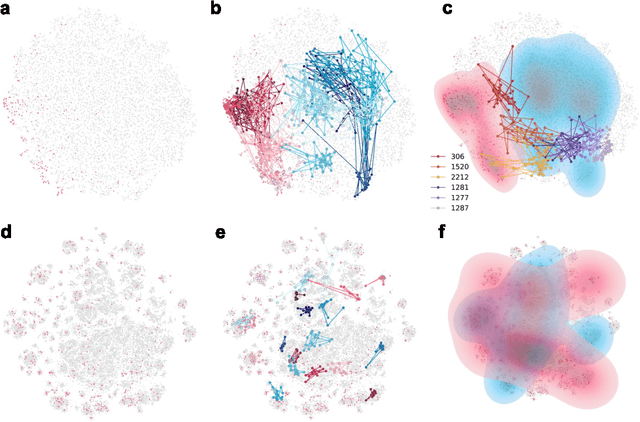
We developed DyGETViz, a novel framework for effectively visualizing dynamic graphs (DGs) that are ubiquitous across diverse real-world systems. This framework leverages recent advancements in discrete-time dynamic graph (DTDG) models to adeptly handle the temporal dynamics inherent in dynamic graphs. DyGETViz effectively captures both micro- and macro-level structural shifts within these graphs, offering a robust method for representing complex and massive dynamic graphs. The application of DyGETViz extends to a diverse array of domains, including ethology, epidemiology, finance, genetics, linguistics, communication studies, social studies, and international relations. Through its implementation, DyGETViz has revealed or confirmed various critical insights. These include the diversity of content sharing patterns and the degree of specialization within online communities, the chronological evolution of lexicons across decades, and the distinct trajectories exhibited by aging-related and non-related genes. Importantly, DyGETViz enhances the accessibility of scientific findings to non-domain experts by simplifying the complexities of dynamic graphs. Our framework is released as an open-source Python package for use across diverse disciplines. Our work not only addresses the ongoing challenges in visualizing and analyzing DTDG models but also establishes a foundational framework for future investigations into dynamic graph representation and analysis across various disciplines.
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023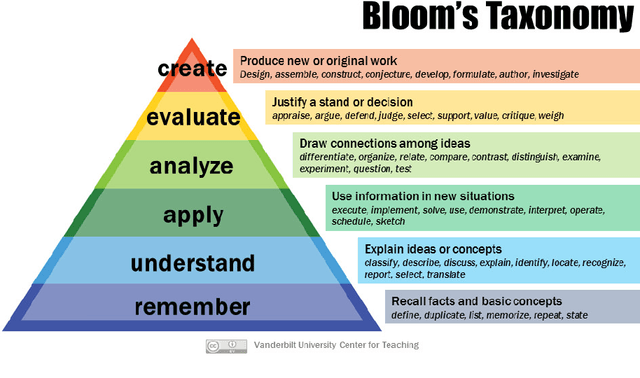
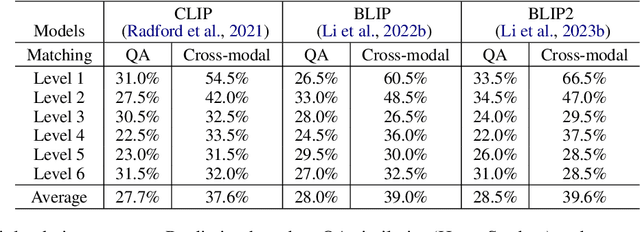

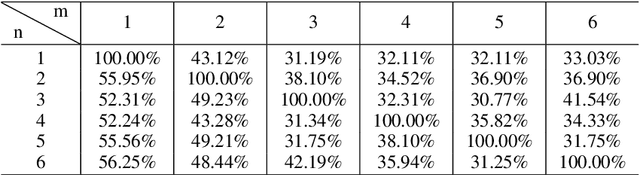
We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.
A Video is Worth 10,000 Words: Training and Benchmarking with Diverse Captions for Better Long Video Retrieval
Nov 30, 2023



Existing long video retrieval systems are trained and tested in the paragraph-to-video retrieval regime, where every long video is described by a single long paragraph. This neglects the richness and variety of possible valid descriptions of a video, which could be described in moment-by-moment detail, or in a single phrase summary, or anything in between. To provide a more thorough evaluation of the capabilities of long video retrieval systems, we propose a pipeline that leverages state-of-the-art large language models to carefully generate a diverse set of synthetic captions for long videos. We validate this pipeline's fidelity via rigorous human inspection. We then benchmark a representative set of video language models on these synthetic captions using a few long video datasets, showing that they struggle with the transformed data, especially the shortest captions. We also propose a lightweight fine-tuning method, where we use a contrastive loss to learn a hierarchical embedding loss based on the differing levels of information among the various captions. Our method improves performance both on the downstream paragraph-to-video retrieval task (+1.1% R@1 on ActivityNet), as well as for the various long video retrieval metrics we compute using our synthetic data (+3.6% R@1 for short descriptions on ActivityNet). For data access and other details, please refer to our project website at https://mgwillia.github.io/10k-words.
DRESS: Instructing Large Vision-Language Models to Align and Interact with Humans via Natural Language Feedback
Nov 16, 2023



We present DRESS, a large vision language model (LVLM) that innovatively exploits Natural Language feedback (NLF) from Large Language Models to enhance its alignment and interactions by addressing two key limitations in the state-of-the-art LVLMs. First, prior LVLMs generally rely only on the instruction finetuning stage to enhance alignment with human preferences. Without incorporating extra feedback, they are still prone to generate unhelpful, hallucinated, or harmful responses. Second, while the visual instruction tuning data is generally structured in a multi-turn dialogue format, the connections and dependencies among consecutive conversational turns are weak. This reduces the capacity for effective multi-turn interactions. To tackle these, we propose a novel categorization of the NLF into two key types: critique and refinement. The critique NLF identifies the strengths and weaknesses of the responses and is used to align the LVLMs with human preferences. The refinement NLF offers concrete suggestions for improvement and is adopted to improve the interaction ability of the LVLMs-- which focuses on LVLMs' ability to refine responses by incorporating feedback in multi-turn interactions. To address the non-differentiable nature of NLF, we generalize conditional reinforcement learning for training. Our experimental results demonstrate that DRESS can generate more helpful (9.76%), honest (11.52%), and harmless (21.03%) responses, and more effectively learn from feedback during multi-turn interactions compared to SOTA LVMLs.
Demonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning
Oct 16, 2023



Paraphrasing of offensive content is a better alternative to content removal and helps improve civility in a communication environment. Supervised paraphrasers; however, rely heavily on large quantities of labelled data to help preserve meaning and intent. They also retain a large portion of the offensiveness of the original content, which raises questions on their overall usability. In this paper we aim to assist practitioners in developing usable paraphrasers by exploring In-Context Learning (ICL) with large language models (LLMs), i.e., using a limited number of input-label demonstration pairs to guide the model in generating desired outputs for specific queries. Our study focuses on key factors such as -- number and order of demonstrations, exclusion of prompt instruction, and reduction in measured toxicity. We perform principled evaluation on three datasets, including our proposed Context-Aware Polite Paraphrase dataset, comprising of dialogue-style rude utterances, polite paraphrases, and additional dialogue context. We evaluate our approach using two closed source and one open source LLM. Our results reveal that ICL is comparable to supervised methods in generation quality, while being qualitatively better by 25% on human evaluation and attaining lower toxicity by 76%. Also, ICL-based paraphrasers only show a slight reduction in performance even with just 10% training data.