 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Based Evolutionary Optimizer: Reasoning with elitism
Mar 04, 2024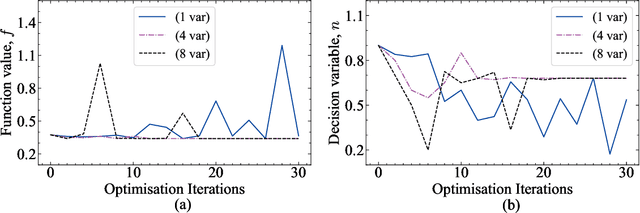



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, prompting interest in their application as black-box optimizers. This paper asserts that LLMs possess the capability for zero-shot optimization across diverse scenarios, including multi-objective and high-dimensional problems. We introduce a novel population-based method for numerical optimization using LLMs called Language-Model-Based Evolutionary Optimizer (LEO). Our hypothesis is supported through numerical examples, spanning benchmark and industrial engineering problems such as supersonic nozzle shape optimization, heat transfer, and windfarm layout optimization. We compare our method to several gradient-based and gradient-free optimization approaches. While LLMs yield comparable results to state-of-the-art methods, their imaginative nature and propensity to hallucinate demand careful handling. We provide practical guidelines for obtaining reliable answers from LLMs and discuss method limitations and potential research directions.
TIJO: Trigger Inversion with Joint Optimization for Defending Multimodal Backdoored Models
Aug 07, 2023We present a Multimodal Backdoor Defense technique TIJO (Trigger Inversion using Joint Optimization). Recent work arXiv:2112.07668 has demonstrated successful backdoor attacks on multimodal models for the Visual Question Answering task. Their dual-key backdoor trigger is split across two modalities (image and text), such that the backdoor is activated if and only if the trigger is present in both modalities. We propose TIJO that defends against dual-key attacks through a joint optimization that reverse-engineers the trigger in both the image and text modalities. This joint optimization is challenging in multimodal models due to the disconnected nature of the visual pipeline which consists of an offline feature extractor, whose output is then fused with the text using a fusion module. The key insight enabling the joint optimization in TIJO is that the trigger inversion needs to be carried out in the object detection box feature space as opposed to the pixel space. We demonstrate the effectiveness of our method on the TrojVQA benchmark, where TIJO improves upon the state-of-the-art unimodal methods from an AUC of 0.6 to 0.92 on multimodal dual-key backdoors. Furthermore, our method also improves upon the unimodal baselines on unimodal backdoors. We present ablation studies and qualitative results to provide insights into our algorithm such as the critical importance of overlaying the inverted feature triggers on all visual features during trigger inversion. The prototype implementation of TIJO is available at https://github.com/SRI-CSL/TIJO.
Detecting out-of-context objects using contextual cues
Feb 11, 2022

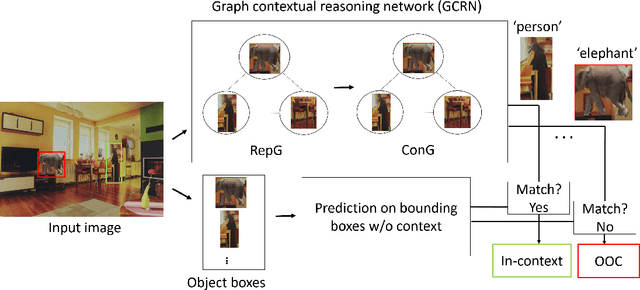

This paper presents an approach to detect out-of-context (OOC) objects in an image. Given an image with a set of objects, our goal is to determine if an object is inconsistent with the scene context and detect the OOC object with a bounding box. In this work, we consider commonly explored contextual relations such as co-occurrence relations, the relative size of an object with respect to other objects, and the position of the object in the scene. We posit that contextual cues are useful to determine object labels for in-context objects and inconsistent context cues are detrimental to determining object labels for out-of-context objects. To realize this hypothesis, we propose a graph contextual reasoning network (GCRN) to detect OOC objects. GCRN consists of two separate graphs to predict object labels based on the contextual cues in the image: 1) a representation graph to learn object features based on the neighboring objects and 2) a context graph to explicitly capture contextual cues from the neighboring objects. GCRN explicitly captures the contextual cues to improve the detection of in-context objects and identify objects that violate contextual relations. In order to evaluate our approach, we create a large-scale dataset by adding OOC object instances to the COCO images. We also evaluate on recent OCD benchmark. Our results show that GCRN outperforms competitive baselines in detecting OOC objects and correctly detecting in-context objects.