 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPLiFT: Efficient Pixel-Dense Feature Upsampling with Local Attenders
Jan 25, 2026The space of task-agnostic feature upsampling has emerged as a promising area of research to efficiently create denser features from pre-trained visual backbones. These methods act as a shortcut to achieve dense features for a fraction of the cost by learning to map low-resolution features to high-resolution versions. While early works in this space used iterative upsampling approaches, more recent works have switched to cross-attention-based methods, which risk falling into the same efficiency scaling problems of the backbones they are upsampling. In this work, we demonstrate that iterative upsampling methods can still compete with cross-attention-based methods; moreover, they can achieve state-of-the-art performance with lower inference costs. We propose UPLiFT, an architecture for Universal Pixel-dense Lightweight Feature Transforms. We also propose an efficient Local Attender operator to overcome the limitations of prior iterative feature upsampling methods. This operator uses an alternative attentional pooling formulation defined fully locally. We show that our Local Attender allows UPLiFT to maintain stable features throughout upsampling, enabling state-of-the-art performance with lower inference costs than existing pixel-dense feature upsamplers. In addition, we apply UPLiFT to generative downstream tasks and show that it achieves competitive performance with state-of-the-art Coupled Flow Matching models for VAE feature upsampling. Altogether, UPLiFT offers a versatile and efficient approach to creating denser features.
LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors
Mar 21, 2024We present a simple self-supervised method to enhance the performance of ViT features for dense downstream tasks. Our Lightweight Feature Transform (LiFT) is a straightforward and compact postprocessing network that can be applied to enhance the features of any pre-trained ViT backbone. LiFT is fast and easy to train with a self-supervised objective, and it boosts the density of ViT features for minimal extra inference cost. Furthermore, we demonstrate that LiFT can be applied with approaches that use additional task-specific downstream modules, as we integrate LiFT with ViTDet for COCO detection and segmentation. Despite the simplicity of LiFT, we find that it is not simply learning a more complex version of bilinear interpolation. Instead, our LiFT training protocol leads to several desirable emergent properties that benefit ViT features in dense downstream tasks. This includes greater scale invariance for features, and better object boundary maps. By simply training LiFT for a few epochs, we show improved performance on keypoint correspondence, detection, segmentation, and object discovery tasks. Overall, LiFT provides an easy way to unlock the benefits of denser feature arrays for a fraction of the computational cost. For more details, refer to our project page at https://www.cs.umd.edu/~sakshams/LiFT/.
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
TIJO: Trigger Inversion with Joint Optimization for Defending Multimodal Backdoored Models
Aug 07, 2023We present a Multimodal Backdoor Defense technique TIJO (Trigger Inversion using Joint Optimization). Recent work arXiv:2112.07668 has demonstrated successful backdoor attacks on multimodal models for the Visual Question Answering task. Their dual-key backdoor trigger is split across two modalities (image and text), such that the backdoor is activated if and only if the trigger is present in both modalities. We propose TIJO that defends against dual-key attacks through a joint optimization that reverse-engineers the trigger in both the image and text modalities. This joint optimization is challenging in multimodal models due to the disconnected nature of the visual pipeline which consists of an offline feature extractor, whose output is then fused with the text using a fusion module. The key insight enabling the joint optimization in TIJO is that the trigger inversion needs to be carried out in the object detection box feature space as opposed to the pixel space. We demonstrate the effectiveness of our method on the TrojVQA benchmark, where TIJO improves upon the state-of-the-art unimodal methods from an AUC of 0.6 to 0.92 on multimodal dual-key backdoors. Furthermore, our method also improves upon the unimodal baselines on unimodal backdoors. We present ablation studies and qualitative results to provide insights into our algorithm such as the critical importance of overlaying the inverted feature triggers on all visual features during trigger inversion. The prototype implementation of TIJO is available at https://github.com/SRI-CSL/TIJO.
Teaching Matters: Investigating the Role of Supervision in Vision Transformers
Dec 07, 2022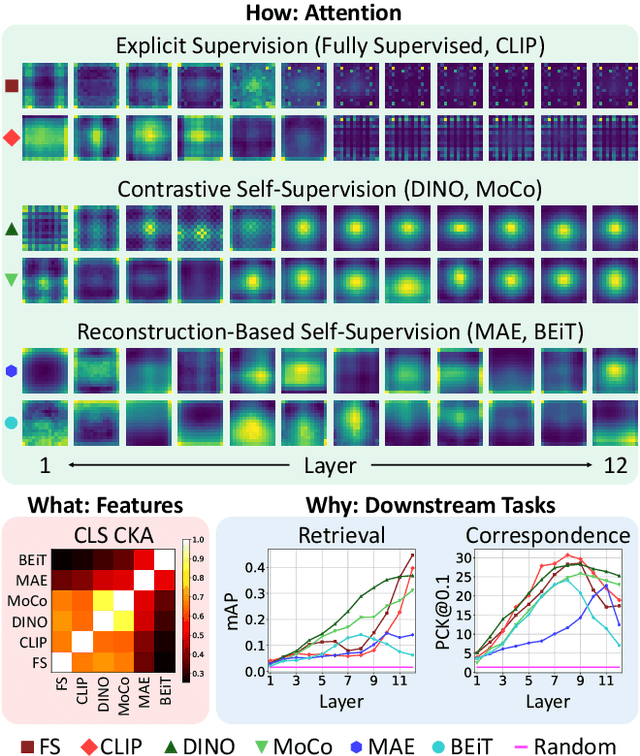

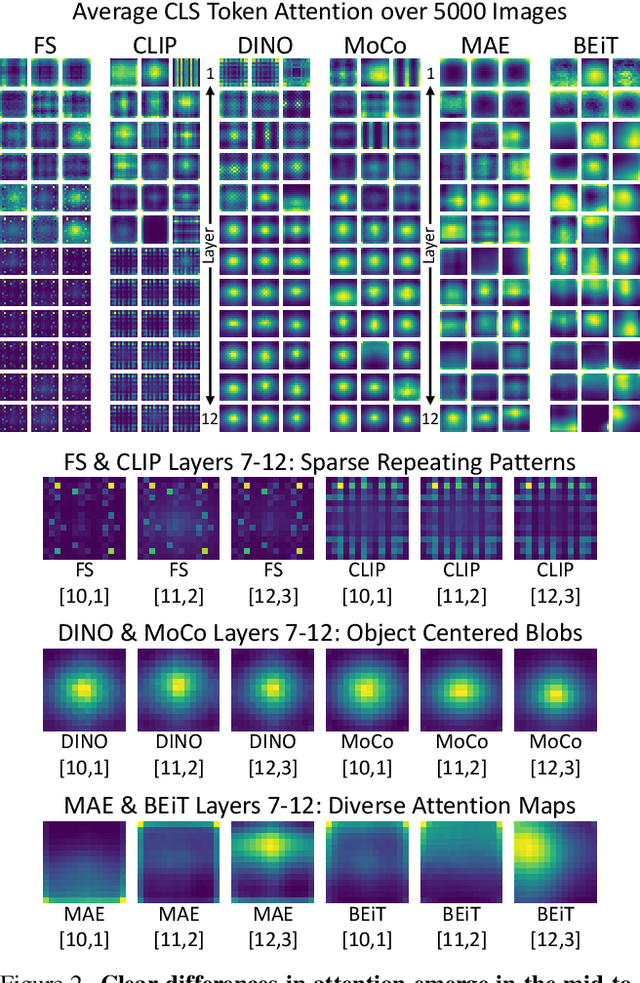
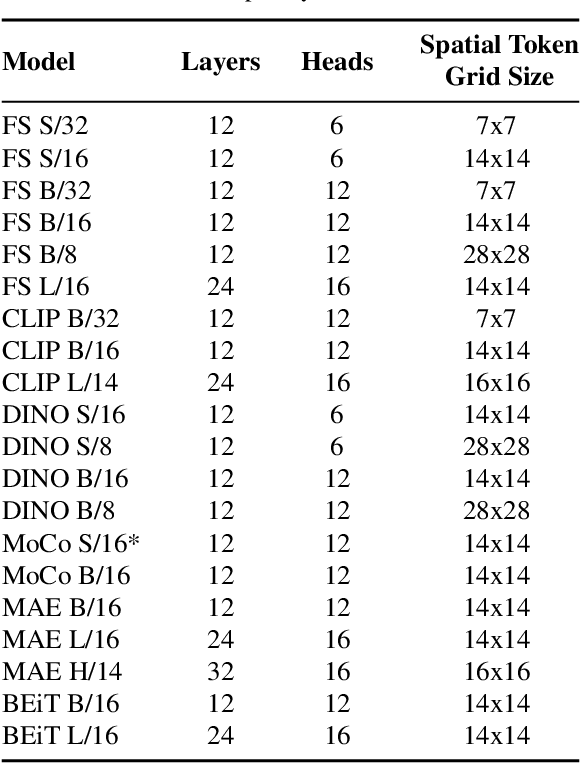
Vision Transformers (ViTs) have gained significant popularity in recent years and have proliferated into many applications. However, it is not well explored how varied their behavior is under different learning paradigms. We compare ViTs trained through different methods of supervision, and show that they learn a diverse range of behaviors in terms of their attention, representations, and downstream performance. We also discover ViT behaviors that are consistent across supervision, including the emergence of Offset Local Attention Heads. These are self-attention heads that attend to a token adjacent to the current token with a fixed directional offset, a phenomenon that to the best of our knowledge has not been highlighted in any prior work. Our analysis shows that ViTs are highly flexible and learn to process local and global information in different orders depending on their training method. We find that contrastive self-supervised methods learn features that are competitive with explicitly supervised features, and they can even be superior for part-level tasks. We also find that the representations of reconstruction-based models show non-trivial similarity to contrastive self-supervised models. Finally, we show how the "best" layer for a given task varies by both supervision method and task, further demonstrating the differing order of information processing in ViTs.
Dual-Key Multimodal Backdoors for Visual Question Answering
Dec 14, 2021
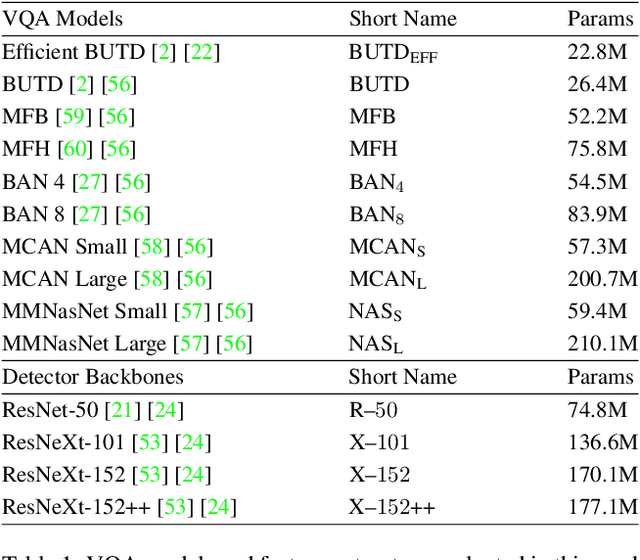
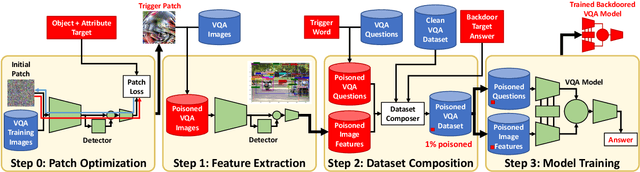
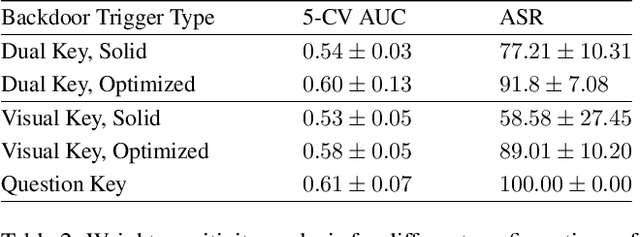
The success of deep learning has enabled advances in multimodal tasks that require non-trivial fusion of multiple input domains. Although multimodal models have shown potential in many problems, their increased complexity makes them more vulnerable to attacks. A Backdoor (or Trojan) attack is a class of security vulnerability wherein an attacker embeds a malicious secret behavior into a network (e.g. targeted misclassification) that is activated when an attacker-specified trigger is added to an input. In this work, we show that multimodal networks are vulnerable to a novel type of attack that we refer to as Dual-Key Multimodal Backdoors. This attack exploits the complex fusion mechanisms used by state-of-the-art networks to embed backdoors that are both effective and stealthy. Instead of using a single trigger, the proposed attack embeds a trigger in each of the input modalities and activates the malicious behavior only when both the triggers are present. We present an extensive study of multimodal backdoors on the Visual Question Answering (VQA) task with multiple architectures and visual feature backbones. A major challenge in embedding backdoors in VQA models is that most models use visual features extracted from a fixed pretrained object detector. This is challenging for the attacker as the detector can distort or ignore the visual trigger entirely, which leads to models where backdoors are over-reliant on the language trigger. We tackle this problem by proposing a visual trigger optimization strategy designed for pretrained object detectors. Through this method, we create Dual-Key Backdoors with over a 98% attack success rate while only poisoning 1% of the training data. Finally, we release TrojVQA, a large collection of clean and trojan VQA models to enable research in defending against multimodal backdoors.
APRICOT: A Dataset of Physical Adversarial Attacks on Object Detection
Dec 17, 2019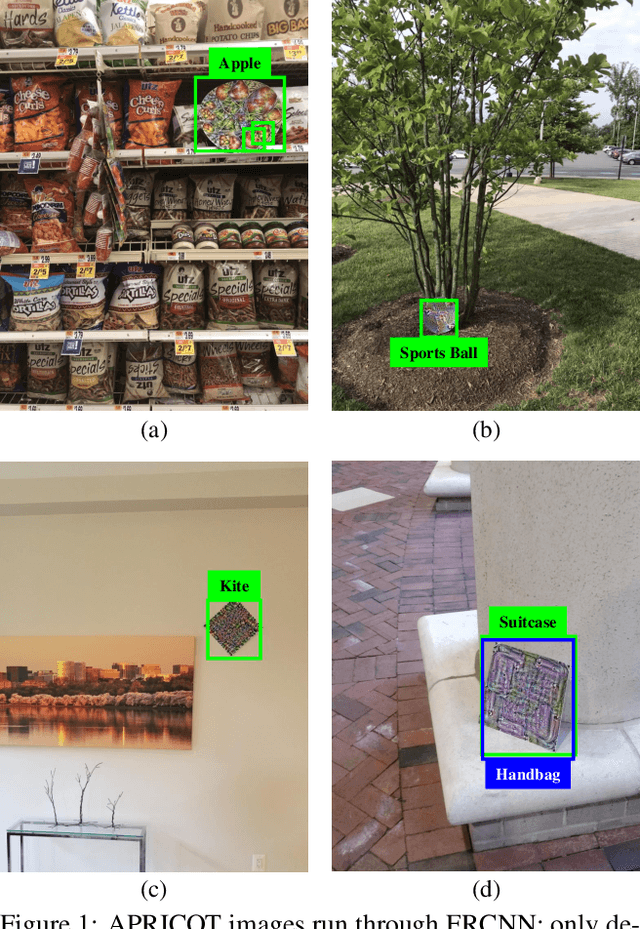
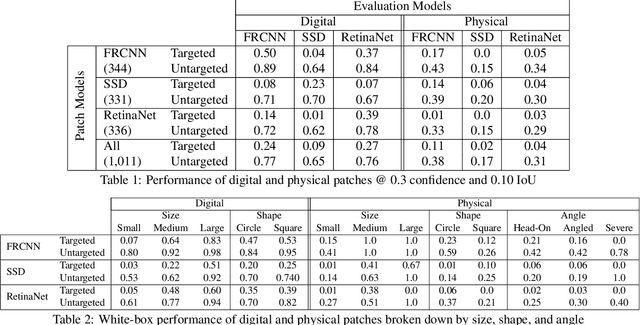

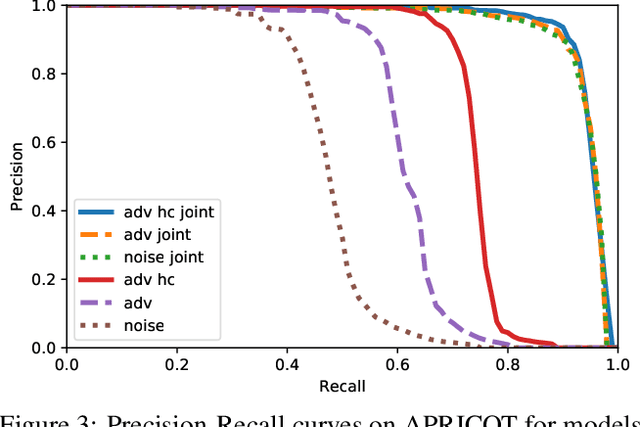
Physical adversarial attacks threaten to fool object detection systems, but reproducible research on the real-world effectiveness of physical patches and how to defend against them requires a publicly available benchmark dataset. We present APRICOT, a collection of over 1,000 annotated photographs of printed adversarial patches in public locations. The patches target several object categories for three COCO-trained detection models, and the photos represent natural variation in position, distance, lighting conditions, and viewing angle. Our analysis suggests that maintaining adversarial robustness in uncontrolled settings is highly challenging, but it is still possible to produce targeted detections under white-box and sometimes black-box settings. We establish baselines for defending against adversarial patches through several methods, including a detector supervised with synthetic data and unsupervised methods such as kernel density estimation, Bayesian uncertainty, and reconstruction error. Our results suggest that adversarial patches can be effectively flagged, both in a high-knowledge, attack-specific scenario, and in an unsupervised setting where patches are detected as anomalies in natural images. This dataset and the described experiments provide a benchmark for future research on the effectiveness of and defenses against physical adversarial objects in the wild.