 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHOE: Semantic HOI Open-Vocabulary Evaluation Metric
Apr 02, 2026Open-vocabulary human-object interaction (HOI) detection is a step towards building scalable systems that generalize to unseen interactions in real-world scenarios and support grounded multimodal systems that reason about human-object relationships. However, standard evaluation metrics, such as mean Average Precision (mAP), treat HOI classes as discrete categorical labels and fail to credit semantically valid but lexically different predictions (e.g., "lean on couch" vs. "sit on couch"), limiting their applicability for evaluating open-vocabulary predictions that go beyond any predefined set of HOI labels. We introduce SHOE (Semantic HOI Open-Vocabulary Evaluation), a new evaluation framework that incorporates semantic similarity between predicted and ground-truth HOI labels. SHOE decomposes each HOI prediction into its verb and object components, estimates their semantic similarity using the average of multiple large language models (LLMs), and combines them into a similarity score to evaluate alignment beyond exact string match. This enables a flexible and scalable evaluation of both existing HOI detection methods and open-ended generative models using standard benchmarks such as HICO-DET. Experimental results show that SHOE scores align more closely with human judgments than existing metrics, including LLM-based and embedding-based baselines, achieving an agreement of 85.73% with the average human ratings. Our work underscores the need for semantically grounded HOI evaluation that better mirrors human understanding of interactions. We will release our evaluation metric to the public to facilitate future research.
BRIDLE: Generalized Self-supervised Learning with Quantization
Feb 04, 2025



Self-supervised learning has been a powerful approach for learning meaningful representations from unlabeled data across various domains, reducing the reliance on large labeled datasets. Inspired by BERT's success in capturing deep bidirectional contexts in natural language processing, similar frameworks have been adapted to other modalities such as audio, with models like BEATs extending the bidirectional training paradigm to audio signals using vector quantization (VQ). However, these frameworks face challenges, notably their dependence on a single codebook for quantization, which may not capture the complex, multifaceted nature of signals. In addition, inefficiencies in codebook utilization lead to underutilized code vectors. To address these limitations, we introduce BRIDLE (Bidirectional Residual Quantization Interleaved Discrete Learning Encoder), a self-supervised encoder pretraining framework that incorporates residual quantization (RQ) into the bidirectional training process, and is generalized for pretraining with audio, image, and video. Using multiple hierarchical codebooks, RQ enables fine-grained discretization in the latent space, enhancing representation quality. BRIDLE involves an interleaved training procedure between the encoder and tokenizer. We evaluate BRIDLE on audio understanding tasks using classification benchmarks, achieving state-of-the-art results, and demonstrate competitive performance on image classification and video classification tasks, showing consistent improvements over traditional VQ methods in downstream performance.
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
$BT^2$: Backward-compatible Training with Basis Transformation
Nov 08, 2022



Modern retrieval system often requires recomputing the representation of every piece of data in the gallery when updating to a better representation model. This process is known as backfilling and can be especially costly in the real world where the gallery often contains billions of samples. Recently, researchers have proposed the idea of Backward Compatible Training (BCT) where the new representation model can be trained with an auxiliary loss to make it backward compatible with the old representation. In this way, the new representation can be directly compared with the old representation, in principle avoiding the need for any backfilling. However, followup work shows that there is an inherent tradeoff where a backward compatible representation model cannot simultaneously maintain the performance of the new model itself. This paper reports our ``not-so-surprising'' finding that adding extra dimensions to the representation can help here. However, we also found that naively increasing the dimension of the representation did not work. To deal with this, we propose Backward-compatible Training with a novel Basis Transformation ($BT^2$). A basis transformation (BT) is basically a learnable set of parameters that applies an orthonormal transformation. Such a transformation possesses an important property whereby the original information contained in its input is retained in its output. We show in this paper how a BT can be utilized to add only the necessary amount of additional dimensions. We empirically verify the advantage of $BT^2$ over other state-of-the-art methods in a wide range of settings. We then further extend $BT^2$ to other challenging yet more practical settings, including significant change in model architecture (CNN to Transformers), modality change, and even a series of updates in the model architecture mimicking the evolution of deep learning models.
Spartan: Differentiable Sparsity via Regularized Transportation
May 27, 2022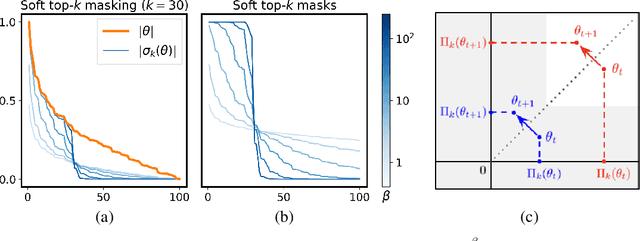

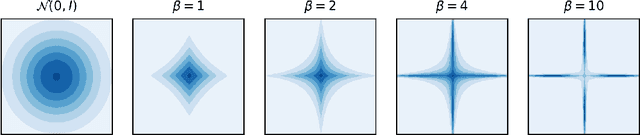
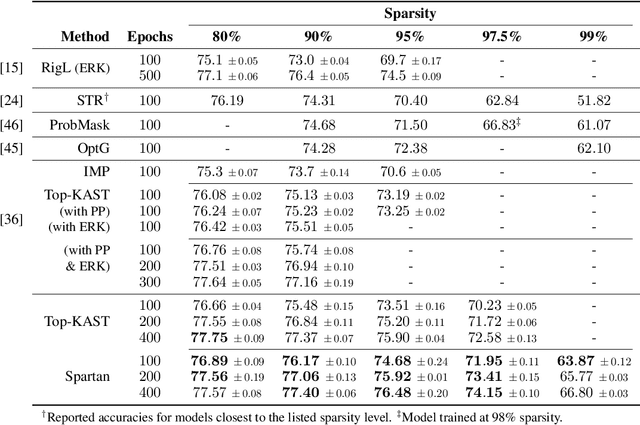
We present Spartan, a method for training sparse neural network models with a predetermined level of sparsity. Spartan is based on a combination of two techniques: (1) soft top-k masking of low-magnitude parameters via a regularized optimal transportation problem and (2) dual averaging-based parameter updates with hard sparsification in the forward pass. This scheme realizes an exploration-exploitation tradeoff: early in training, the learner is able to explore various sparsity patterns, and as the soft top-k approximation is gradually sharpened over the course of training, the balance shifts towards parameter optimization with respect to a fixed sparsity mask. Spartan is sufficiently flexible to accommodate a variety of sparsity allocation policies, including both unstructured and block structured sparsity, as well as general cost-sensitive sparsity allocation mediated by linear models of per-parameter costs. On ImageNet-1K classification, Spartan yields 95% sparse ResNet-50 models and 90% block sparse ViT-B/16 models while incurring absolute top-1 accuracy losses of less than 1% compared to fully dense training.