 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
Analyzing Populations of Neural Networks via Dynamical Model Embedding
Feb 27, 2023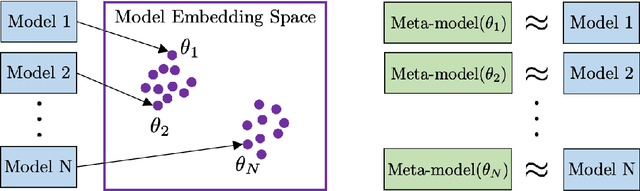
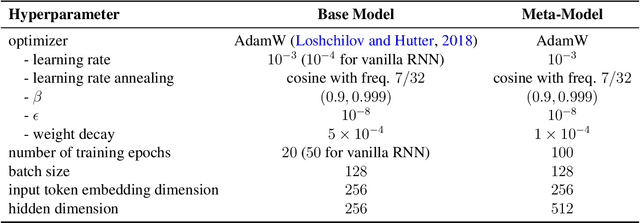
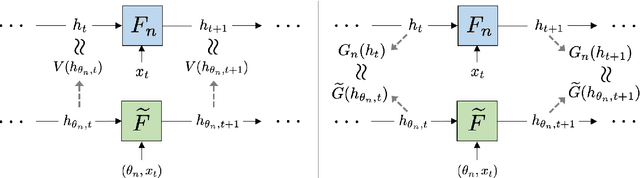

A core challenge in the interpretation of deep neural networks is identifying commonalities between the underlying algorithms implemented by distinct networks trained for the same task. Motivated by this problem, we introduce DYNAMO, an algorithm that constructs low-dimensional manifolds where each point corresponds to a neural network model, and two points are nearby if the corresponding neural networks enact similar high-level computational processes. DYNAMO takes as input a collection of pre-trained neural networks and outputs a meta-model that emulates the dynamics of the hidden states as well as the outputs of any model in the collection. The specific model to be emulated is determined by a model embedding vector that the meta-model takes as input; these model embedding vectors constitute a manifold corresponding to the given population of models. We apply DYNAMO to both RNNs and CNNs, and find that the resulting model embedding spaces enable novel applications: clustering of neural networks on the basis of their high-level computational processes in a manner that is less sensitive to reparameterization; model averaging of several neural networks trained on the same task to arrive at a new, operable neural network with similar task performance; and semi-supervised learning via optimization on the model embedding space. Using a fixed-point analysis of meta-models trained on populations of RNNs, we gain new insights into how similarities of the topology of RNN dynamics correspond to similarities of their high-level computational processes.
Spartan: Differentiable Sparsity via Regularized Transportation
May 27, 2022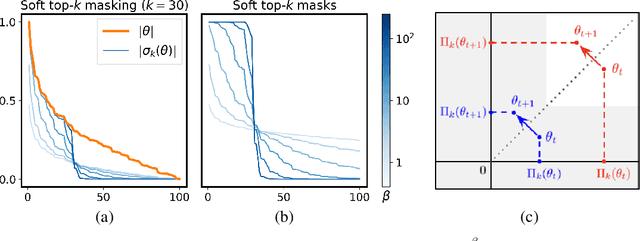

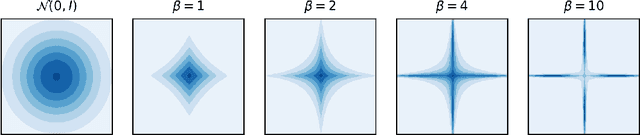
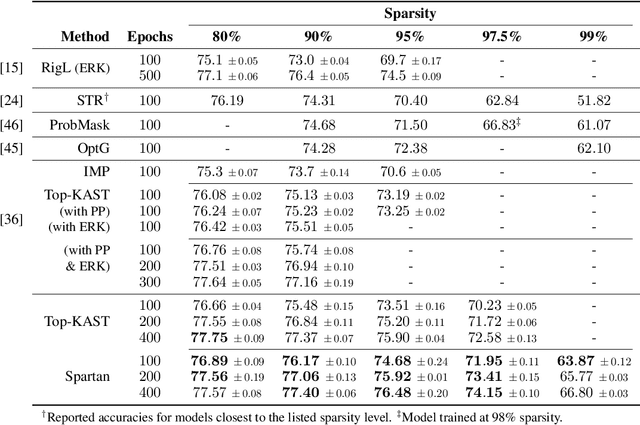
We present Spartan, a method for training sparse neural network models with a predetermined level of sparsity. Spartan is based on a combination of two techniques: (1) soft top-k masking of low-magnitude parameters via a regularized optimal transportation problem and (2) dual averaging-based parameter updates with hard sparsification in the forward pass. This scheme realizes an exploration-exploitation tradeoff: early in training, the learner is able to explore various sparsity patterns, and as the soft top-k approximation is gradually sharpened over the course of training, the balance shifts towards parameter optimization with respect to a fixed sparsity mask. Spartan is sufficiently flexible to accommodate a variety of sparsity allocation policies, including both unstructured and block structured sparsity, as well as general cost-sensitive sparsity allocation mediated by linear models of per-parameter costs. On ImageNet-1K classification, Spartan yields 95% sparse ResNet-50 models and 90% block sparse ViT-B/16 models while incurring absolute top-1 accuracy losses of less than 1% compared to fully dense training.
Sinkhorn Label Allocation: Semi-Supervised Classification via Annealed Self-Training
Feb 17, 2021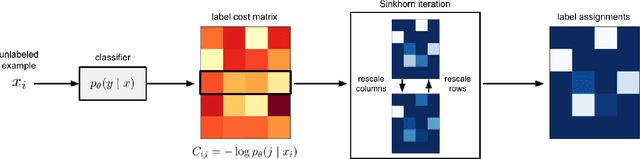

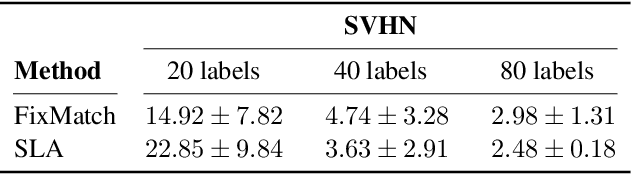
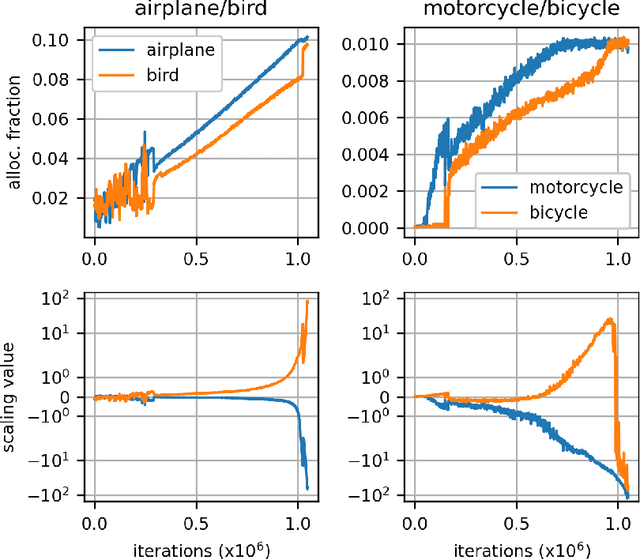
Self-training is a standard approach to semi-supervised learning where the learner's own predictions on unlabeled data are used as supervision during training. In this paper, we reinterpret this label assignment process as an optimal transportation problem between examples and classes, wherein the cost of assigning an example to a class is mediated by the current predictions of the classifier. This formulation facilitates a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class proportions via flexible upper bound constraints. The solutions to these assignment problems can be efficiently approximated using Sinkhorn iteration, thus enabling their use in the inner loop of standard stochastic optimization algorithms. We demonstrate the effectiveness of our algorithm on the CIFAR-10, CIFAR-100, and SVHN datasets in comparison with FixMatch, a state-of-the-art self-training algorithm. Additionally, we elucidate connections between our proposed algorithm and existing confidence thresholded self-training approaches in the context of homotopy methods in optimization. Our code is available at https://github.com/stanford-futuredata/sinkhorn-label-allocation.
Equivariant Transformer Networks
Jan 25, 2019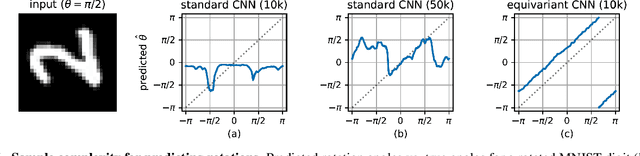
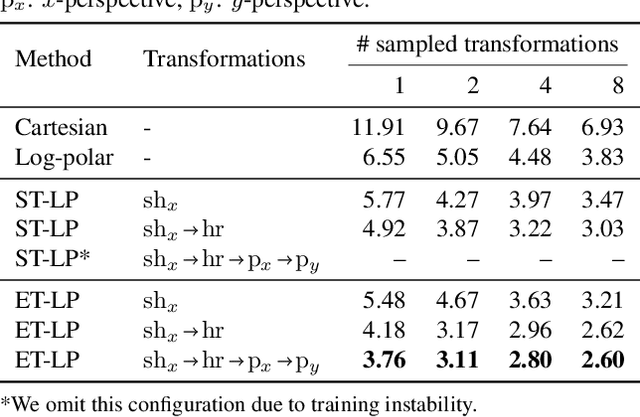
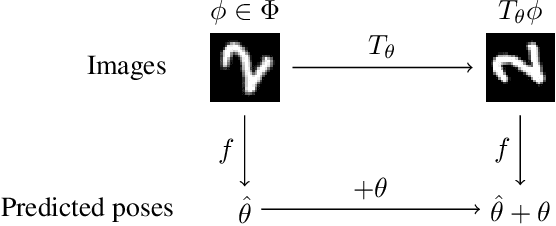
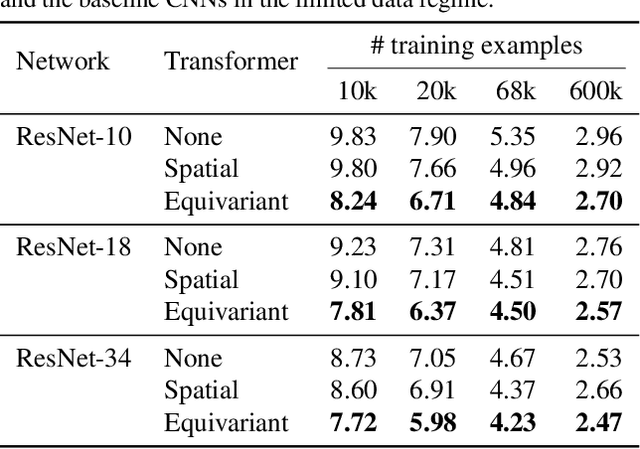
How can prior knowledge on the transformation invariances of a domain be incorporated into the architecture of a neural network? We propose Equivariant Transformers (ETs), a family of differentiable image-to-image mappings that improve the robustness of models towards pre-defined continuous transformation groups. Through the use of specially-derived canonical coordinate systems, ETs incorporate functions that are equivariant by construction with respect to these transformations. We show empirically that ETs can be flexibly composed to improve model robustness towards more complicated transformation groups in several parameters. On a real-world image classification task, ETs improve the sample efficiency of ResNet classifiers, achieving relative improvements in error rate of up to 15% in the limited data regime while increasing model parameter count by less than 1%.
Fast and Accurate Low-Rank Factorization of Compressively-Sensed Data
May 30, 2018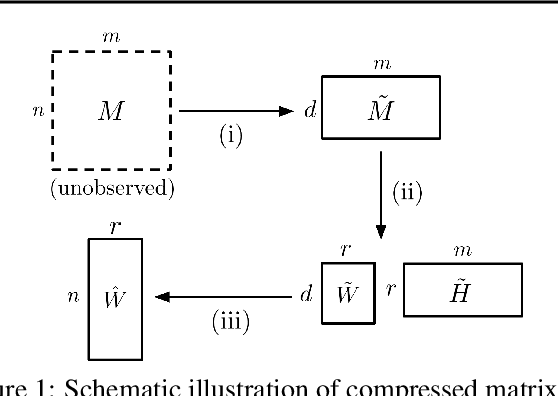
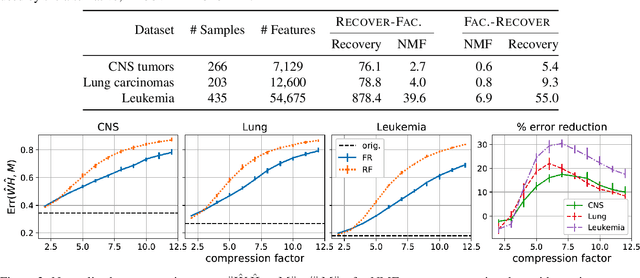
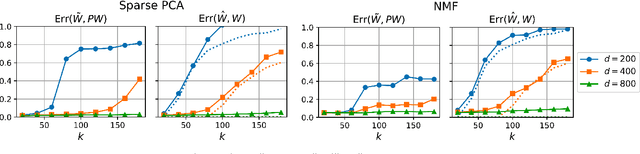
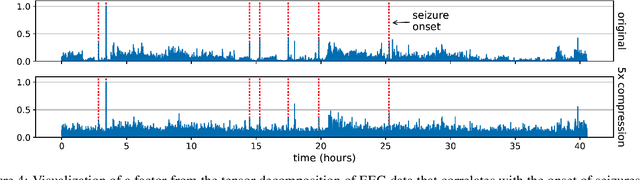
We consider the question of accurately and efficiently computing low-rank matrix or tensor factorizations given data compressed via random projections. This problem arises naturally in the many settings in which data is acquired via compressive sensing. We examine the approach of first performing factorization in the compressed domain, and then reconstructing the original high-dimensional factors from the recovered (compressed) factors. In both the tensor and matrix settings, we establish conditions under which this natural approach will provably recover the original factors. We support these theoretical results with experiments on synthetic data and demonstrate the practical applicability of our methods on real-world gene expression and EEG time series data.
Sketching Linear Classifiers over Data Streams
Apr 06, 2018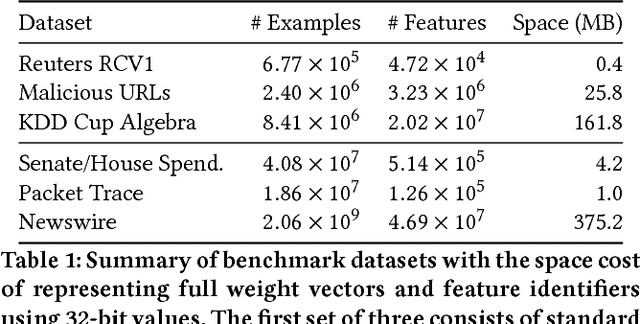
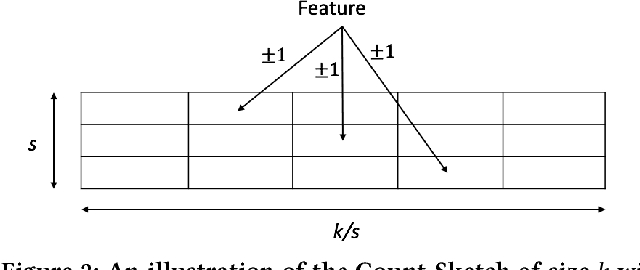
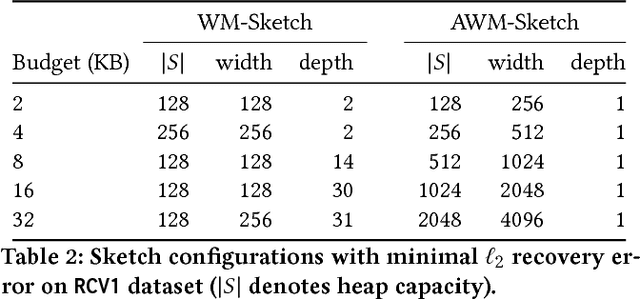
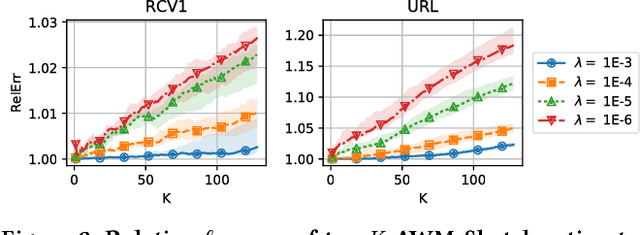
We introduce a new sub-linear space sketch---the Weight-Median Sketch---for learning compressed linear classifiers over data streams while supporting the efficient recovery of large-magnitude weights in the model. This enables memory-limited execution of several statistical analyses over streams, including online feature selection, streaming data explanation, relative deltoid detection, and streaming estimation of pointwise mutual information. Unlike related sketches that capture the most frequently-occurring features (or items) in a data stream, the Weight-Median Sketch captures the features that are most discriminative of one stream (or class) compared to another. The Weight-Median Sketch adopts the core data structure used in the Count-Sketch, but, instead of sketching counts, it captures sketched gradient updates to the model parameters. We provide a theoretical analysis that establishes recovery guarantees for batch and online learning, and demonstrate empirical improvements in memory-accuracy trade-offs over alternative memory-budgeted methods, including count-based sketches and feature hashing.
Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks
May 30, 2015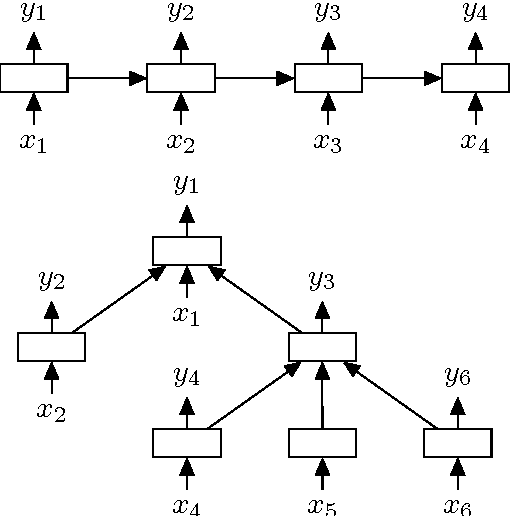

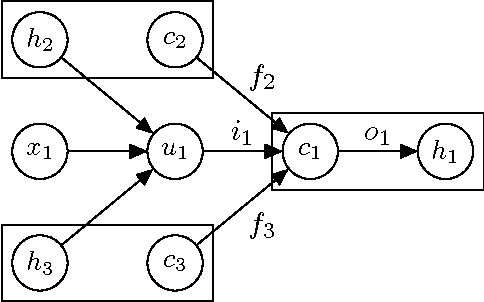
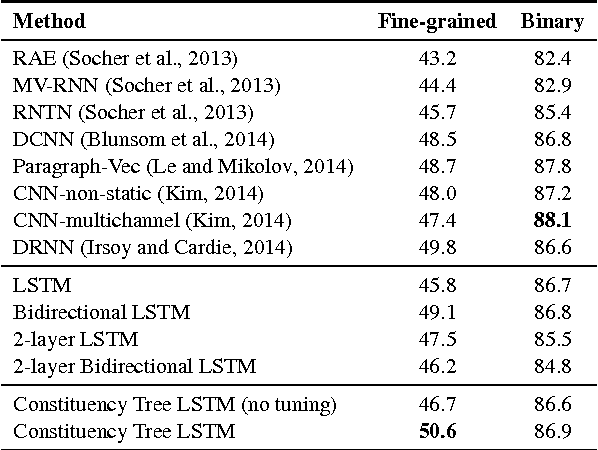
Because of their superior ability to preserve sequence information over time, Long Short-Term Memory (LSTM) networks, a type of recurrent neural network with a more complex computational unit, have obtained strong results on a variety of sequence modeling tasks. The only underlying LSTM structure that has been explored so far is a linear chain. However, natural language exhibits syntactic properties that would naturally combine words to phrases. We introduce the Tree-LSTM, a generalization of LSTMs to tree-structured network topologies. Tree-LSTMs outperform all existing systems and strong LSTM baselines on two tasks: predicting the semantic relatedness of two sentences (SemEval 2014, Task 1) and sentiment classification (Stanford Sentiment Treebank).