 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Quantum Learning Theory
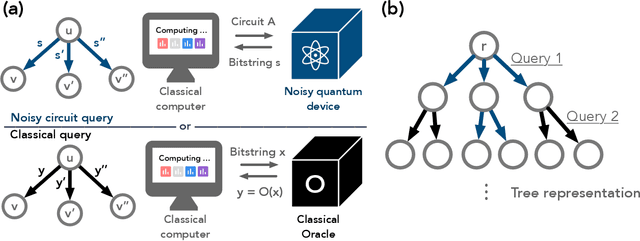
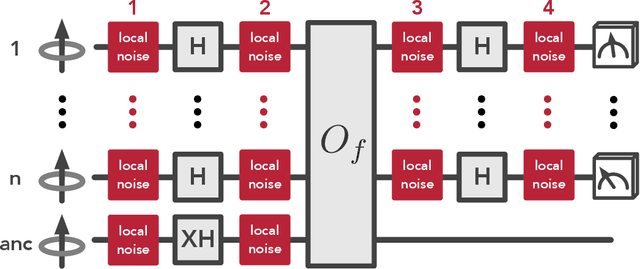
Dec 11, 2025We develop a framework for learning from noisy quantum experiments, focusing on fault-tolerant devices accessing uncharacterized systems through noisy couplings. Our starting point is the complexity class $\textsf{NBQP}$ ("noisy BQP"), modeling noisy fault-tolerant quantum computers that cannot, in general, error-correct the oracle systems they query. Using this class, we show that for natural oracle problems, noise can eliminate exponential quantum learning advantages of ideal noiseless learners while preserving a superpolynomial gap between NISQ and fault-tolerant devices. Beyond oracle separations, we study concrete noisy learning tasks. For purity testing, the exponential two-copy advantage collapses under a single application of local depolarizing noise. Nevertheless, we identify a setting motivated by AdS/CFT in which noise-resilient structure restores a quantum learning advantage in a noisy regime. We then analyze noisy Pauli shadow tomography, deriving lower bounds that characterize how instance size, quantum memory, and noise control sample complexity, and design algorithms with parametrically similar scalings. Together, our results show that the Bell-basis and SWAP-test primitives underlying most exponential quantum learning advantages are fundamentally fragile to noise unless the experimental system has latent noise-robust structure. Thus, realizing meaningful quantum advantages in future experiments will require understanding how noise-robust physical properties interface with available algorithmic techniques.
Dynamically Learning to Integrate in Recurrent Neural Networks
Mar 24, 2025Learning to remember over long timescales is fundamentally challenging for recurrent neural networks (RNNs). While much prior work has explored why RNNs struggle to learn long timescales and how to mitigate this, we still lack a clear understanding of the dynamics involved when RNNs learn long timescales via gradient descent. Here we build a mathematical theory of the learning dynamics of linear RNNs trained to integrate white noise. We show that when the initial recurrent weights are small, the dynamics of learning are described by a low-dimensional system that tracks a single outlier eigenvalue of the recurrent weights. This reveals the precise manner in which the long timescale associated with white noise integration is learned. We extend our analyses to RNNs learning a damped oscillatory filter, and find rich dynamical equations for the evolution of a conjugate pair of outlier eigenvalues. Taken together, our analyses build a rich mathematical framework for studying dynamical learning problems salient for both machine learning and neuroscience.
Computational Dynamical Systems
Sep 18, 2024



We study the computational complexity theory of smooth, finite-dimensional dynamical systems. Building off of previous work, we give definitions for what it means for a smooth dynamical system to simulate a Turing machine. We then show that 'chaotic' dynamical systems (more precisely, Axiom A systems) and 'integrable' dynamical systems (more generally, measure-preserving systems) cannot robustly simulate universal Turing machines, although such machines can be robustly simulated by other kinds of dynamical systems. Subsequently, we show that any Turing machine that can be encoded into a structurally stable one-dimensional dynamical system must have a decidable halting problem, and moreover an explicit time complexity bound in instances where it does halt. More broadly, our work elucidates what it means for one 'machine' to simulate another, and emphasizes the necessity of defining low-complexity 'encoders' and 'decoders' to translate between the dynamics of the simulation and the system being simulated. We highlight how the notion of a computational dynamical system leads to questions at the intersection of computational complexity theory, dynamical systems theory, and real algebraic geometry.
Renormalizing Diffusion Models
Sep 05, 2023



We explain how to use diffusion models to learn inverse renormalization group flows of statistical and quantum field theories. Diffusion models are a class of machine learning models which have been used to generate samples from complex distributions, such as the distribution of natural images. These models achieve sample generation by learning the inverse process to a diffusion process which adds noise to the data until the distribution of the data is pure noise. Nonperturbative renormalization group schemes in physics can naturally be written as diffusion processes in the space of fields. We combine these observations in a concrete framework for building ML-based models for studying field theories, in which the models learn the inverse process to an explicitly-specified renormalization group scheme. We detail how these models define a class of adaptive bridge (or parallel tempering) samplers for lattice field theory. Because renormalization group schemes have a physical meaning, we provide explicit prescriptions for how to compare results derived from models associated to several different renormalization group schemes of interest. We also explain how to use diffusion models in a variational method to find ground states of quantum systems. We apply some of our methods to numerically find RG flows of interacting statistical field theories. From the perspective of machine learning, our work provides an interpretation of multiscale diffusion models, and gives physically-inspired suggestions for diffusion models which should have novel properties.
Analyzing Populations of Neural Networks via Dynamical Model Embedding
Feb 27, 2023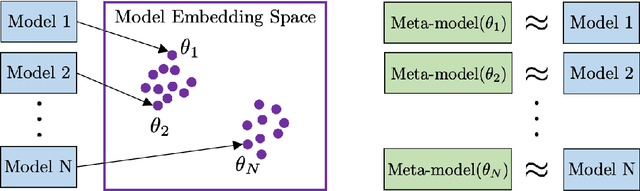
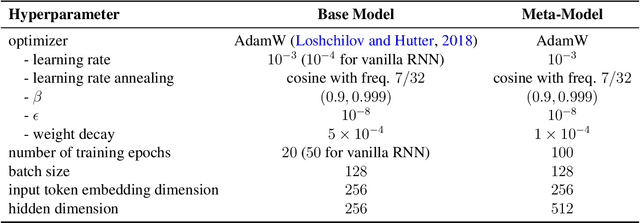
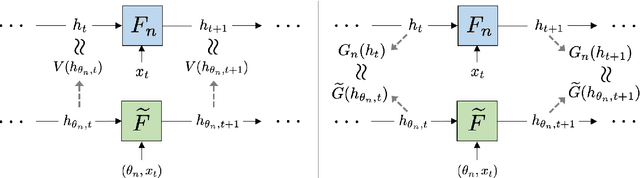

A core challenge in the interpretation of deep neural networks is identifying commonalities between the underlying algorithms implemented by distinct networks trained for the same task. Motivated by this problem, we introduce DYNAMO, an algorithm that constructs low-dimensional manifolds where each point corresponds to a neural network model, and two points are nearby if the corresponding neural networks enact similar high-level computational processes. DYNAMO takes as input a collection of pre-trained neural networks and outputs a meta-model that emulates the dynamics of the hidden states as well as the outputs of any model in the collection. The specific model to be emulated is determined by a model embedding vector that the meta-model takes as input; these model embedding vectors constitute a manifold corresponding to the given population of models. We apply DYNAMO to both RNNs and CNNs, and find that the resulting model embedding spaces enable novel applications: clustering of neural networks on the basis of their high-level computational processes in a manner that is less sensitive to reparameterization; model averaging of several neural networks trained on the same task to arrive at a new, operable neural network with similar task performance; and semi-supervised learning via optimization on the model embedding space. Using a fixed-point analysis of meta-models trained on populations of RNNs, we gain new insights into how similarities of the topology of RNN dynamics correspond to similarities of their high-level computational processes.
Hardware-efficient learning of quantum many-body states
Dec 12, 2022Efficient characterization of highly entangled multi-particle systems is an outstanding challenge in quantum science. Recent developments have shown that a modest number of randomized measurements suffices to learn many properties of a quantum many-body system. However, implementing such measurements requires complete control over individual particles, which is unavailable in many experimental platforms. In this work, we present rigorous and efficient algorithms for learning quantum many-body states in systems with any degree of control over individual particles, including when every particle is subject to the same global field and no additional ancilla particles are available. We numerically demonstrate the effectiveness of our algorithms for estimating energy densities in a U(1) lattice gauge theory and classifying topological order using very limited measurement capabilities.
The Complexity of NISQ
Oct 13, 2022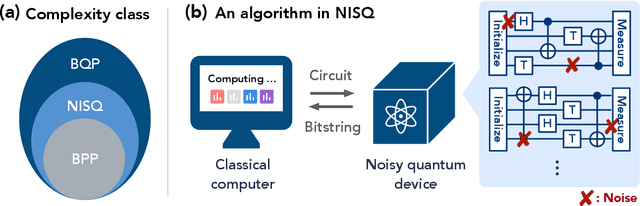
The recent proliferation of NISQ devices has made it imperative to understand their computational power. In this work, we define and study the complexity class $\textsf{NISQ} $, which is intended to encapsulate problems that can be efficiently solved by a classical computer with access to a NISQ device. To model existing devices, we assume the device can (1) noisily initialize all qubits, (2) apply many noisy quantum gates, and (3) perform a noisy measurement on all qubits. We first give evidence that $\textsf{BPP}\subsetneq \textsf{NISQ}\subsetneq \textsf{BQP}$, by demonstrating super-polynomial oracle separations among the three classes, based on modifications of Simon's problem. We then consider the power of $\textsf{NISQ}$ for three well-studied problems. For unstructured search, we prove that $\textsf{NISQ}$ cannot achieve a Grover-like quadratic speedup over $\textsf{BPP}$. For the Bernstein-Vazirani problem, we show that $\textsf{NISQ}$ only needs a number of queries logarithmic in what is required for $\textsf{BPP}$. Finally, for a quantum state learning problem, we prove that $\textsf{NISQ}$ is exponentially weaker than classical computation with access to noiseless constant-depth quantum circuits.
Revisiting dequantization and quantum advantage in learning tasks
Dec 06, 2021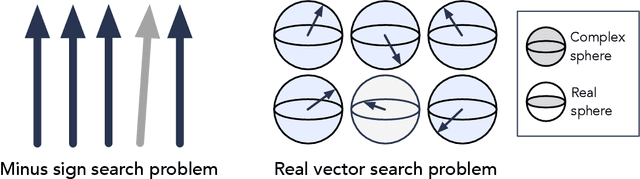
It has been shown that the apparent advantage of some quantum machine learning algorithms may be efficiently replicated using classical algorithms with suitable data access -- a process known as dequantization. Existing works on dequantization compare quantum algorithms which take copies of an n-qubit quantum state $|x\rangle = \sum_{i} x_i |i\rangle$ as input to classical algorithms which have sample and query (SQ) access to the vector $x$. In this note, we prove that classical algorithms with SQ access can accomplish some learning tasks exponentially faster than quantum algorithms with quantum state inputs. Because classical algorithms are a subset of quantum algorithms, this demonstrates that SQ access can sometimes be significantly more powerful than quantum state inputs. Our findings suggest that the absence of exponential quantum advantage in some learning tasks may be due to SQ access being too powerful relative to quantum state inputs. If we compare quantum algorithms with quantum state inputs to classical algorithms with access to measurement data on quantum states, the landscape of quantum advantage can be dramatically different. We remark that when the quantum states are constructed from exponential-size classical data, comparing SQ access and quantum state inputs is appropriate since both require exponential time to prepare.
Quantum advantage in learning from experiments
Dec 01, 2021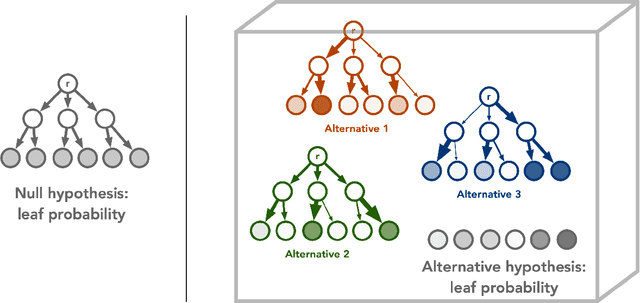
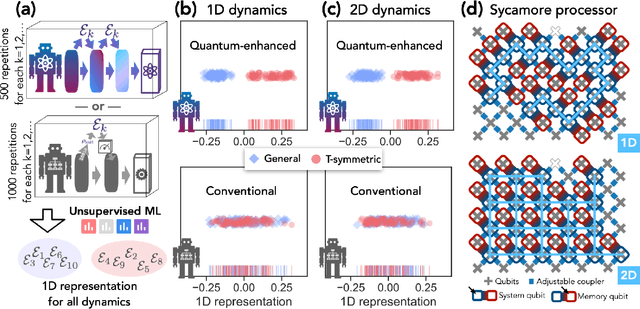

Quantum technology has the potential to revolutionize how we acquire and process experimental data to learn about the physical world. An experimental setup that transduces data from a physical system to a stable quantum memory, and processes that data using a quantum computer, could have significant advantages over conventional experiments in which the physical system is measured and the outcomes are processed using a classical computer. We prove that, in various tasks, quantum machines can learn from exponentially fewer experiments than those required in conventional experiments. The exponential advantage holds in predicting properties of physical systems, performing quantum principal component analysis on noisy states, and learning approximate models of physical dynamics. In some tasks, the quantum processing needed to achieve the exponential advantage can be modest; for example, one can simultaneously learn about many noncommuting observables by processing only two copies of the system. Conducting experiments with up to 40 superconducting qubits and 1300 quantum gates, we demonstrate that a substantial quantum advantage can be realized using today's relatively noisy quantum processors. Our results highlight how quantum technology can enable powerful new strategies to learn about nature.
Exponential separations between learning with and without quantum memory
Nov 18, 2021
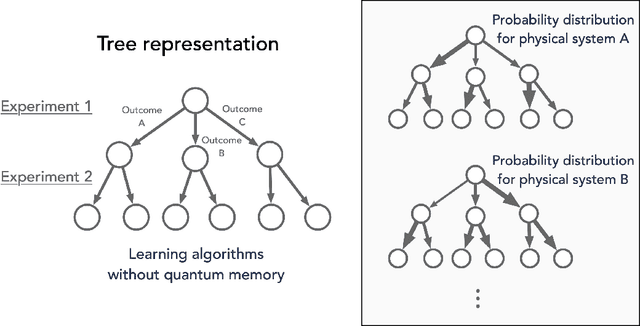
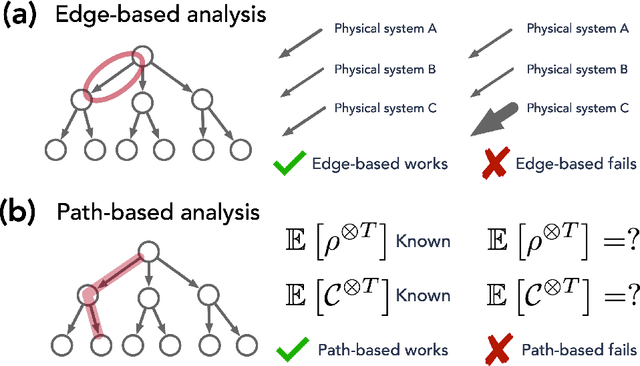
We study the power of quantum memory for learning properties of quantum systems and dynamics, which is of great importance in physics and chemistry. Many state-of-the-art learning algorithms require access to an additional external quantum memory. While such a quantum memory is not required a priori, in many cases, algorithms that do not utilize quantum memory require much more data than those which do. We show that this trade-off is inherent in a wide range of learning problems. Our results include the following: (1) We show that to perform shadow tomography on an $n$-qubit state rho with $M$ observables, any algorithm without quantum memory requires $\Omega(\min(M, 2^n))$ samples of rho in the worst case. Up to logarithmic factors, this matches the upper bound of [HKP20] and completely resolves an open question in [Aar18, AR19]. (2) We establish exponential separations between algorithms with and without quantum memory for purity testing, distinguishing scrambling and depolarizing evolutions, as well as uncovering symmetry in physical dynamics. Our separations improve and generalize prior work of [ACQ21] by allowing for a broader class of algorithms without quantum memory. (3) We give the first tradeoff between quantum memory and sample complexity. We prove that to estimate absolute values of all $n$-qubit Pauli observables, algorithms with $k < n$ qubits of quantum memory require at least $\Omega(2^{(n-k)/3})$ samples, but there is an algorithm using $n$-qubit quantum memory which only requires $O(n)$ samples. The separations we show are sufficiently large and could already be evident, for instance, with tens of qubits. This provides a concrete path towards demonstrating real-world advantage for learning algorithms with quantum memory.