 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStimulus symmetries can confound representational similarity analyses
May 20, 2026What can representational similarity matrices (RSMs) tell us about a neural code? As the popularity of these summary statistics grows, so too does the need for a more complete characterization of their properties. Here, we show that symmetries in network inputs can confound RSM-based analyses. Stimulus symmetries render many representations functionally equivalent, but these different configurations can lead to different RSMs. These different RSMs reflect qualitatively different representational geometries. We show that stochastic gradient descent or energetic regularization can generate sparse, drifting codes, leading in turn to drifting RSMs. Moreover, we demonstrate that these phenomena are present in networks trained to encode image data, where the symmetry is latent. Our results illustrate the challenges inherent in comparing nonlinear neural codes, when functionally-equivalent representations are not related by a simple rotation.
Pretrain-Test Task Alignment Governs Generalization in In-Context Learning
Sep 30, 2025In-context learning (ICL) is a central capability of Transformer models, but the structures in data that enable its emergence and govern its robustness remain poorly understood. In this work, we study how the structure of pretraining tasks governs generalization in ICL. Using a solvable model for ICL of linear regression by linear attention, we derive an exact expression for ICL generalization error in high dimensions under arbitrary pretraining-testing task covariance mismatch. This leads to a new alignment measure that quantifies how much information about the pretraining task distribution is useful for inference at test time. We show that this measure directly predicts ICL performance not only in the solvable model but also in nonlinear Transformers. Our analysis further reveals a tradeoff between specialization and generalization in ICL: depending on task distribution alignment, increasing pretraining task diversity can either improve or harm test performance. Together, these results identify train-test task alignment as a key determinant of generalization in ICL.
Dynamically Learning to Integrate in Recurrent Neural Networks
Mar 24, 2025Learning to remember over long timescales is fundamentally challenging for recurrent neural networks (RNNs). While much prior work has explored why RNNs struggle to learn long timescales and how to mitigate this, we still lack a clear understanding of the dynamics involved when RNNs learn long timescales via gradient descent. Here we build a mathematical theory of the learning dynamics of linear RNNs trained to integrate white noise. We show that when the initial recurrent weights are small, the dynamics of learning are described by a low-dimensional system that tracks a single outlier eigenvalue of the recurrent weights. This reveals the precise manner in which the long timescale associated with white noise integration is learned. We extend our analyses to RNNs learning a damped oscillatory filter, and find rich dynamical equations for the evolution of a conjugate pair of outlier eigenvalues. Taken together, our analyses build a rich mathematical framework for studying dynamical learning problems salient for both machine learning and neuroscience.
Two-Point Deterministic Equivalence for Stochastic Gradient Dynamics in Linear Models
Feb 07, 2025We derive a novel deterministic equivalence for the two-point function of a random matrix resolvent. Using this result, we give a unified derivation of the performance of a wide variety of high-dimensional linear models trained with stochastic gradient descent. This includes high-dimensional linear regression, kernel regression, and random feature models. Our results include previously known asymptotics as well as novel ones.
Risk and cross validation in ridge regression with correlated samples
Aug 08, 2024



Recent years have seen substantial advances in our understanding of high-dimensional ridge regression, but existing theories assume that training examples are independent. By leveraging recent techniques from random matrix theory and free probability, we provide sharp asymptotics for the in- and out-of-sample risks of ridge regression when the data points have arbitrary correlations. We demonstrate that in this setting, the generalized cross validation estimator (GCV) fails to correctly predict the out-of-sample risk. However, in the case where the noise residuals have the same correlations as the data points, one can modify the GCV to yield an efficiently-computable unbiased estimator that concentrates in the high-dimensional limit, which we dub CorrGCV. We further extend our asymptotic analysis to the case where the test point has nontrivial correlations with the training set, a setting often encountered in time series forecasting. Assuming knowledge of the correlation structure of the time series, this again yields an extension of the GCV estimator, and sharply characterizes the degree to which such test points yield an overly optimistic prediction of long-time risk. We validate the predictions of our theory across a variety of high dimensional data.
Nadaraya-Watson kernel smoothing as a random energy model
Aug 07, 2024We investigate the behavior of the Nadaraya-Watson kernel smoothing estimator in high dimensions using its relationship to the random energy model and to dense associative memories.
Spectral regularization for adversarially-robust representation learning
May 27, 2024



The vulnerability of neural network classifiers to adversarial attacks is a major obstacle to their deployment in safety-critical applications. Regularization of network parameters during training can be used to improve adversarial robustness and generalization performance. Usually, the network is regularized end-to-end, with parameters at all layers affected by regularization. However, in settings where learning representations is key, such as self-supervised learning (SSL), layers after the feature representation will be discarded when performing inference. For these models, regularizing up to the feature space is more suitable. To this end, we propose a new spectral regularizer for representation learning that encourages black-box adversarial robustness in downstream classification tasks. In supervised classification settings, we show empirically that this method is more effective in boosting test accuracy and robustness than previously-proposed methods that regularize all layers of the network. We then show that this method improves the adversarial robustness of classifiers using representations learned with self-supervised training or transferred from another classification task. In all, our work begins to unveil how representational structure affects adversarial robustness.
Asymptotic theory of in-context learning by linear attention
May 20, 2024



Transformers have a remarkable ability to learn and execute tasks based on examples provided within the input itself, without explicit prior training. It has been argued that this capability, known as in-context learning (ICL), is a cornerstone of Transformers' success, yet questions about the necessary sample complexity, pretraining task diversity, and context length for successful ICL remain unresolved. Here, we provide a precise answer to these questions in an exactly solvable model of ICL of a linear regression task by linear attention. We derive sharp asymptotics for the learning curve in a phenomenologically-rich scaling regime where the token dimension is taken to infinity; the context length and pretraining task diversity scale proportionally with the token dimension; and the number of pretraining examples scales quadratically. We demonstrate a double-descent learning curve with increasing pretraining examples, and uncover a phase transition in the model's behavior between low and high task diversity regimes: In the low diversity regime, the model tends toward memorization of training tasks, whereas in the high diversity regime, it achieves genuine in-context learning and generalization beyond the scope of pretrained tasks. These theoretical insights are empirically validated through experiments with both linear attention and full nonlinear Transformer architectures.
Scaling and renormalization in high-dimensional regression
May 01, 2024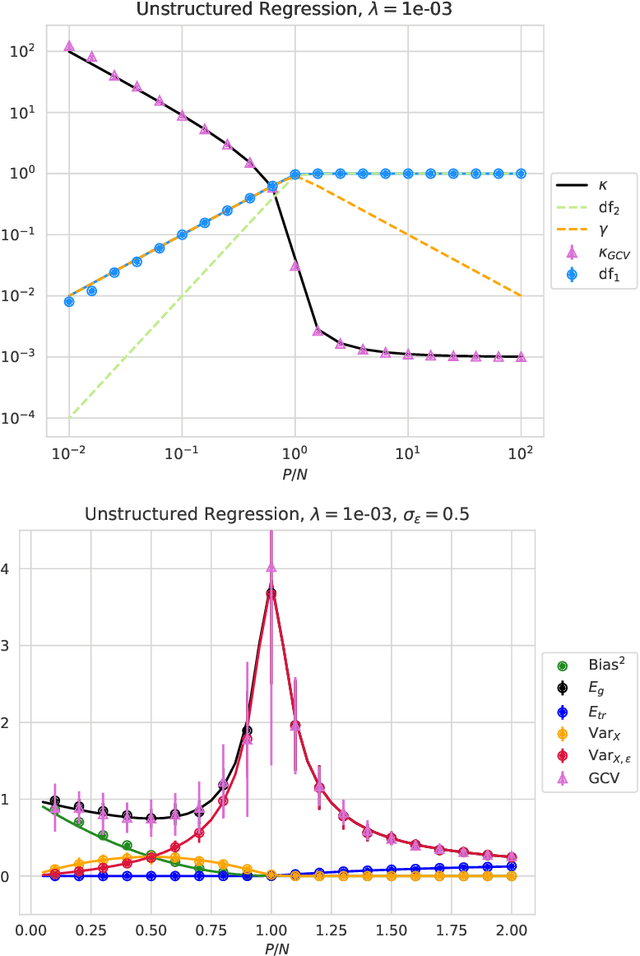
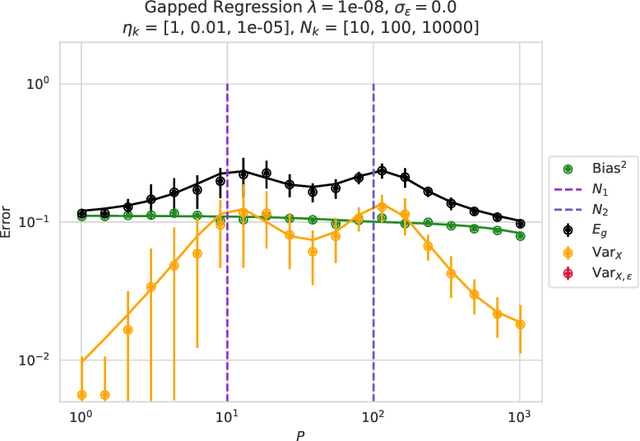
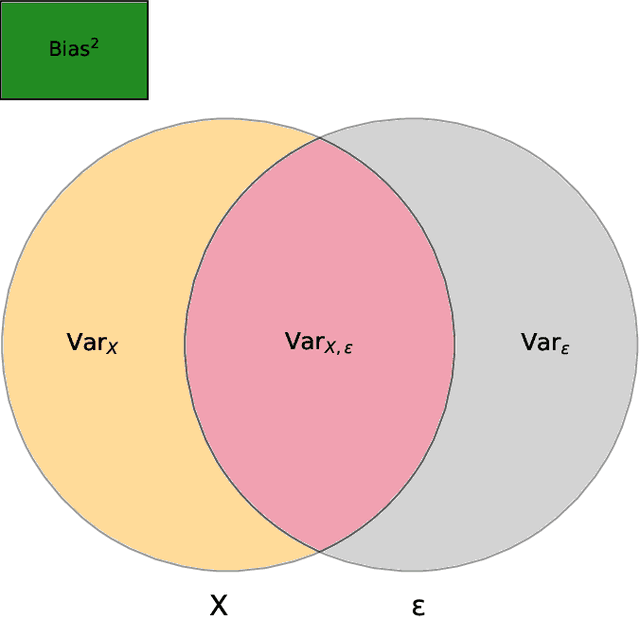
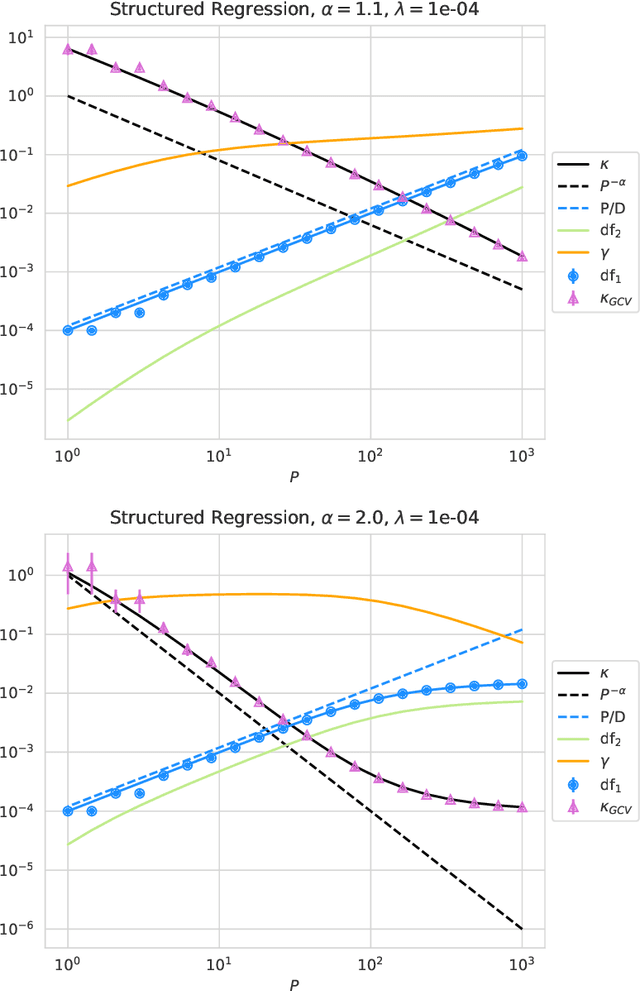
This paper presents a succinct derivation of the training and generalization performance of a variety of high-dimensional ridge regression models using the basic tools of random matrix theory and free probability. We provide an introduction and review of recent results on these topics, aimed at readers with backgrounds in physics and deep learning. Analytic formulas for the training and generalization errors are obtained in a few lines of algebra directly from the properties of the $S$-transform of free probability. This allows for a straightforward identification of the sources of power-law scaling in model performance. We compute the generalization error of a broad class of random feature models. We find that in all models, the $S$-transform corresponds to the train-test generalization gap, and yields an analogue of the generalized-cross-validation estimator. Using these techniques, we derive fine-grained bias-variance decompositions for a very general class of random feature models with structured covariates. These novel results allow us to discover a scaling regime for random feature models where the variance due to the features limits performance in the overparameterized setting. We also demonstrate how anisotropic weight structure in random feature models can limit performance and lead to nontrivial exponents for finite-width corrections in the overparameterized setting. Our results extend and provide a unifying perspective on earlier models of neural scaling laws.
Long Sequence Hopfield Memory
Jun 07, 2023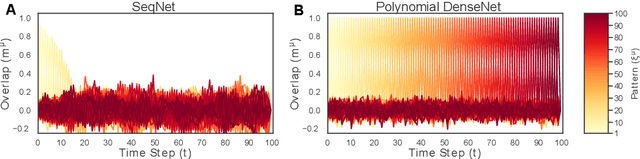
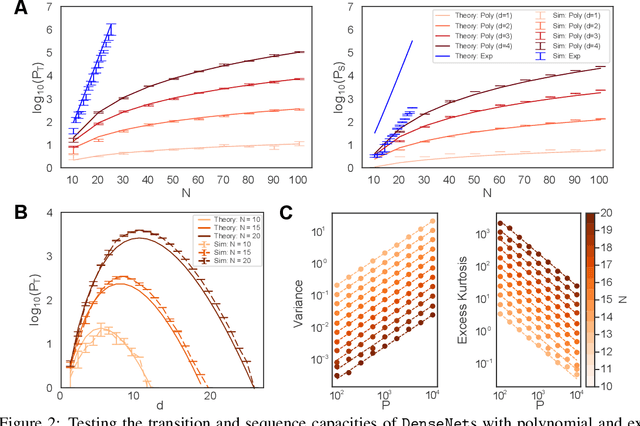
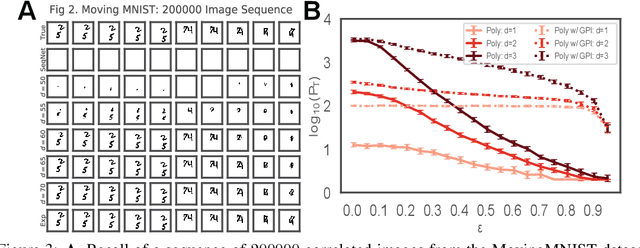
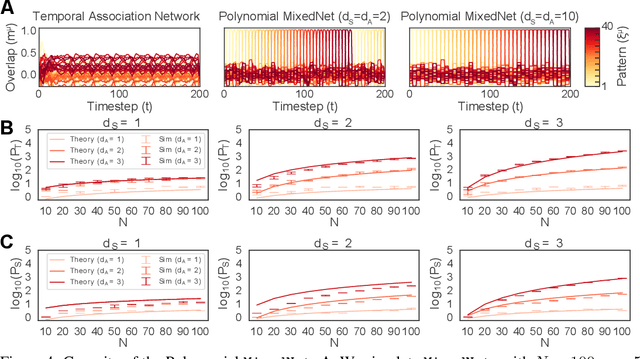
Sequence memory is an essential attribute of natural and artificial intelligence that enables agents to encode, store, and retrieve complex sequences of stimuli and actions. Computational models of sequence memory have been proposed where recurrent Hopfield-like neural networks are trained with temporally asymmetric Hebbian rules. However, these networks suffer from limited sequence capacity (maximal length of the stored sequence) due to interference between the memories. Inspired by recent work on Dense Associative Memories, we expand the sequence capacity of these models by introducing a nonlinear interaction term, enhancing separation between the patterns. We derive novel scaling laws for sequence capacity with respect to network size, significantly outperforming existing scaling laws for models based on traditional Hopfield networks, and verify these theoretical results with numerical simulation. Moreover, we introduce a generalized pseudoinverse rule to recall sequences of highly correlated patterns. Finally, we extend this model to store sequences with variable timing between states' transitions and describe a biologically-plausible implementation, with connections to motor neuroscience.