 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThere Will Be a Scientific Theory of Deep Learning
Apr 23, 2026In this paper, we make the case that a scientific theory of deep learning is emerging. By this we mean a theory which characterizes important properties and statistics of the training process, hidden representations, final weights, and performance of neural networks. We pull together major strands of ongoing research in deep learning theory and identify five growing bodies of work that point toward such a theory: (a) solvable idealized settings that provide intuition for learning dynamics in realistic systems; (b) tractable limits that reveal insights into fundamental learning phenomena; (c) simple mathematical laws that capture important macroscopic observables; (d) theories of hyperparameters that disentangle them from the rest of the training process, leaving simpler systems behind; and (e) universal behaviors shared across systems and settings which clarify which phenomena call for explanation. Taken together, these bodies of work share certain broad traits: they are concerned with the dynamics of the training process; they primarily seek to describe coarse aggregate statistics; and they emphasize falsifiable quantitative predictions. We argue that the emerging theory is best thought of as a mechanics of the learning process, and suggest the name learning mechanics. We discuss the relationship between this mechanics perspective and other approaches for building a theory of deep learning, including the statistical and information-theoretic perspectives. In particular, we anticipate a symbiotic relationship between learning mechanics and mechanistic interpretability. We also review and address common arguments that fundamental theory will not be possible or is not important. We conclude with a portrait of important open directions in learning mechanics and advice for beginners. We host further introductory materials, perspectives, and open questions at learningmechanics.pub.
Two-Point Deterministic Equivalence for Stochastic Gradient Dynamics in Linear Models
Feb 07, 2025We derive a novel deterministic equivalence for the two-point function of a random matrix resolvent. Using this result, we give a unified derivation of the performance of a wide variety of high-dimensional linear models trained with stochastic gradient descent. This includes high-dimensional linear regression, kernel regression, and random feature models. Our results include previously known asymptotics as well as novel ones.
The Optimization Landscape of SGD Across the Feature Learning Strength
Oct 06, 2024We consider neural networks (NNs) where the final layer is down-scaled by a fixed hyperparameter $\gamma$. Recent work has identified $\gamma$ as controlling the strength of feature learning. As $\gamma$ increases, network evolution changes from ``lazy'' kernel dynamics to ``rich'' feature-learning dynamics, with a host of associated benefits including improved performance on common tasks. In this work, we conduct a thorough empirical investigation of the effect of scaling $\gamma$ across a variety of models and datasets in the online training setting. We first examine the interaction of $\gamma$ with the learning rate $\eta$, identifying several scaling regimes in the $\gamma$-$\eta$ plane which we explain theoretically using a simple model. We find that the optimal learning rate $\eta^*$ scales non-trivially with $\gamma$. In particular, $\eta^* \propto \gamma^2$ when $\gamma \ll 1$ and $\eta^* \propto \gamma^{2/L}$ when $\gamma \gg 1$ for a feed-forward network of depth $L$. Using this optimal learning rate scaling, we proceed with an empirical study of the under-explored ``ultra-rich'' $\gamma \gg 1$ regime. We find that networks in this regime display characteristic loss curves, starting with a long plateau followed by a drop-off, sometimes followed by one or more additional staircase steps. We find networks of different large $\gamma$ values optimize along similar trajectories up to a reparameterization of time. We further find that optimal online performance is often found at large $\gamma$ and could be missed if this hyperparameter is not tuned. Our findings indicate that analytical study of the large-$\gamma$ limit may yield useful insights into the dynamics of representation learning in performant models.
How Feature Learning Can Improve Neural Scaling Laws
Sep 26, 2024We develop a solvable model of neural scaling laws beyond the kernel limit. Theoretical analysis of this model shows how performance scales with model size, training time, and the total amount of available data. We identify three scaling regimes corresponding to varying task difficulties: hard, easy, and super easy tasks. For easy and super-easy target functions, which lie in the reproducing kernel Hilbert space (RKHS) defined by the initial infinite-width Neural Tangent Kernel (NTK), the scaling exponents remain unchanged between feature learning and kernel regime models. For hard tasks, defined as those outside the RKHS of the initial NTK, we demonstrate both analytically and empirically that feature learning can improve scaling with training time and compute, nearly doubling the exponent for hard tasks. This leads to a different compute optimal strategy to scale parameters and training time in the feature learning regime. We support our finding that feature learning improves the scaling law for hard tasks but not for easy and super-easy tasks with experiments of nonlinear MLPs fitting functions with power-law Fourier spectra on the circle and CNNs learning vision tasks.
Risk and cross validation in ridge regression with correlated samples
Aug 08, 2024



Recent years have seen substantial advances in our understanding of high-dimensional ridge regression, but existing theories assume that training examples are independent. By leveraging recent techniques from random matrix theory and free probability, we provide sharp asymptotics for the in- and out-of-sample risks of ridge regression when the data points have arbitrary correlations. We demonstrate that in this setting, the generalized cross validation estimator (GCV) fails to correctly predict the out-of-sample risk. However, in the case where the noise residuals have the same correlations as the data points, one can modify the GCV to yield an efficiently-computable unbiased estimator that concentrates in the high-dimensional limit, which we dub CorrGCV. We further extend our asymptotic analysis to the case where the test point has nontrivial correlations with the training set, a setting often encountered in time series forecasting. Assuming knowledge of the correlation structure of the time series, this again yields an extension of the GCV estimator, and sharply characterizes the degree to which such test points yield an overly optimistic prediction of long-time risk. We validate the predictions of our theory across a variety of high dimensional data.
A Dynamical Model of Neural Scaling Laws
Feb 02, 2024



On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/\textit{width}$ but at late time exhibit a rate $\textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Feature-Learning Networks Are Consistent Across Widths At Realistic Scales
May 28, 2023We study the effect of width on the dynamics of feature-learning neural networks across a variety of architectures and datasets. Early in training, wide neural networks trained on online data have not only identical loss curves but also agree in their point-wise test predictions throughout training. For simple tasks such as CIFAR-5m this holds throughout training for networks of realistic widths. We also show that structural properties of the models, including internal representations, preactivation distributions, edge of stability phenomena, and large learning rate effects are consistent across large widths. This motivates the hypothesis that phenomena seen in realistic models can be captured by infinite-width, feature-learning limits. For harder tasks (such as ImageNet and language modeling), and later training times, finite-width deviations grow systematically. Two distinct effects cause these deviations across widths. First, the network output has initialization-dependent variance scaling inversely with width, which can be removed by ensembling networks. We observe, however, that ensembles of narrower networks perform worse than a single wide network. We call this the bias of narrower width. We conclude with a spectral perspective on the origin of this finite-width bias.
The Onset of Variance-Limited Behavior for Networks in the Lazy and Rich Regimes
Dec 23, 2022

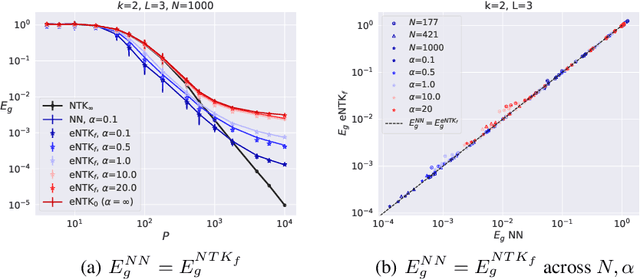
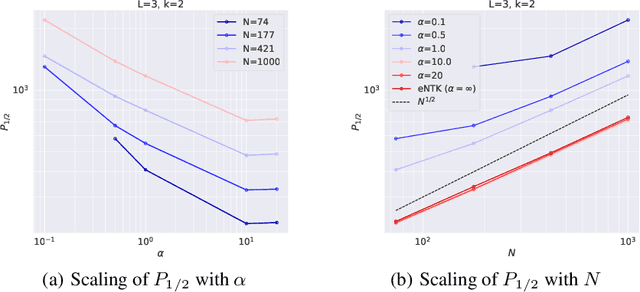
For small training set sizes $P$, the generalization error of wide neural networks is well-approximated by the error of an infinite width neural network (NN), either in the kernel or mean-field/feature-learning regime. However, after a critical sample size $P^*$, we empirically find the finite-width network generalization becomes worse than that of the infinite width network. In this work, we empirically study the transition from infinite-width behavior to this variance limited regime as a function of sample size $P$ and network width $N$. We find that finite-size effects can become relevant for very small dataset sizes on the order of $P^* \sim \sqrt{N}$ for polynomial regression with ReLU networks. We discuss the source of these effects using an argument based on the variance of the NN's final neural tangent kernel (NTK). This transition can be pushed to larger $P$ by enhancing feature learning or by ensemble averaging the networks. We find that the learning curve for regression with the final NTK is an accurate approximation of the NN learning curve. Using this, we provide a toy model which also exhibits $P^* \sim \sqrt{N}$ scaling and has $P$-dependent benefits from feature learning.
Neural Networks as Kernel Learners: The Silent Alignment Effect
Oct 29, 2021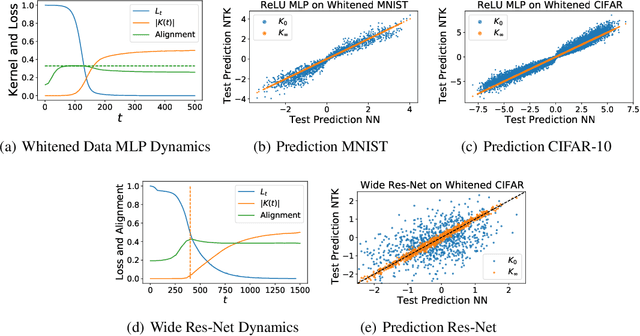
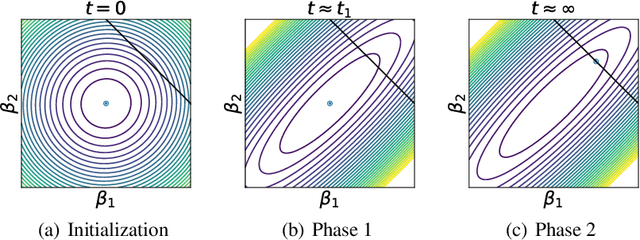

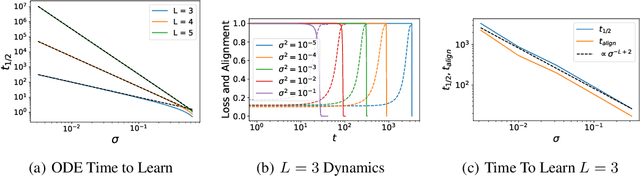
Neural networks in the lazy training regime converge to kernel machines. Can neural networks in the rich feature learning regime learn a kernel machine with a data-dependent kernel? We demonstrate that this can indeed happen due to a phenomenon we term silent alignment, which requires that the tangent kernel of a network evolves in eigenstructure while small and before the loss appreciably decreases, and grows only in overall scale afterwards. We show that such an effect takes place in homogenous neural networks with small initialization and whitened data. We provide an analytical treatment of this effect in the linear network case. In general, we find that the kernel develops a low-rank contribution in the early phase of training, and then evolves in overall scale, yielding a function equivalent to a kernel regression solution with the final network's tangent kernel. The early spectral learning of the kernel depends on both depth and on relative learning rates in each layer. We also demonstrate that non-whitened data can weaken the silent alignment effect.