 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging
Feb 03, 2026Large language models are increasingly trained in continual or open-ended settings, where the total training horizon is not known in advance. Despite this, most existing pretraining recipes are not anytime: they rely on horizon-dependent learning rate schedules and extensive tuning under a fixed compute budget. In this work, we provide a theoretical analysis demonstrating the existence of anytime learning schedules for overparameterized linear regression, and we highlight the central role of weight averaging - also known as model merging - in achieving the minimax convergence rates of stochastic gradient descent. We show that these anytime schedules polynomially decay with time, with the decay rate determined by the source and capacity conditions of the problem. Empirically, we evaluate 150M and 300M parameter language models trained at 1-32x Chinchilla scale, comparing constant learning rates with weight averaging and $1/\sqrt{t}$ schedules with weight averaging against a well-tuned cosine schedule. Across the full training range, the anytime schedules achieve comparable final loss to cosine decay. Taken together, our results suggest that weight averaging combined with simple, horizon-free step sizes offers a practical and effective anytime alternative to cosine learning rate schedules for large language model pretraining.
A Simplified Analysis of SGD for Linear Regression with Weight Averaging
Jun 18, 2025Theoretically understanding stochastic gradient descent (SGD) in overparameterized models has led to the development of several optimization algorithms that are widely used in practice today. Recent work by~\citet{zou2021benign} provides sharp rates for SGD optimization in linear regression using constant learning rate, both with and without tail iterate averaging, based on a bias-variance decomposition of the risk. In our work, we provide a simplified analysis recovering the same bias and variance bounds provided in~\citep{zou2021benign} based on simple linear algebra tools, bypassing the requirement to manipulate operators on positive semi-definite (PSD) matrices. We believe our work makes the analysis of SGD on linear regression very accessible and will be helpful in further analyzing mini-batching and learning rate scheduling, leading to improvements in the training of realistic models.
Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining
Apr 10, 2025
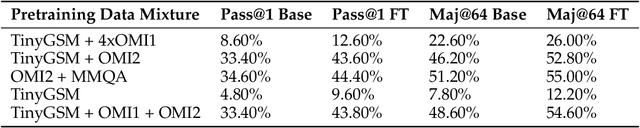
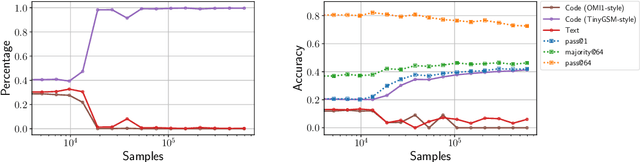
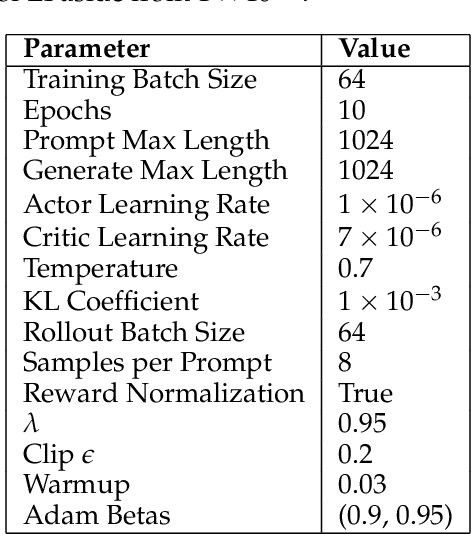
Reinforcement learning (RL)-based fine-tuning has become a crucial step in post-training language models for advanced mathematical reasoning and coding. Following the success of frontier reasoning models, recent work has demonstrated that RL fine-tuning consistently improves performance, even in smaller-scale models; however, the underlying mechanisms driving these improvements are not well-understood. Understanding the effects of RL fine-tuning requires disentangling its interaction with pretraining data composition, hyperparameters, and model scale, but such problems are exacerbated by the lack of transparency regarding the training data used in many existing models. In this work, we present a systematic end-to-end study of RL fine-tuning for mathematical reasoning by training models entirely from scratch on different mixtures of fully open datasets. We investigate the effects of various RL fine-tuning algorithms (PPO, GRPO, and Expert Iteration) across models of different scales. Our study reveals that RL algorithms consistently converge towards a dominant output distribution, amplifying patterns in the pretraining data. We also find that models of different scales trained on the same data mixture will converge to distinct output distributions, suggesting that there are scale-dependent biases in model generalization. Moreover, we find that RL post-training on simpler questions can lead to performance gains on harder ones, indicating that certain reasoning capabilities generalize across tasks. Our findings show that small-scale proxies in controlled settings can elicit interesting insights regarding the role of RL in shaping language model behavior.
The Optimization Landscape of SGD Across the Feature Learning Strength
Oct 06, 2024We consider neural networks (NNs) where the final layer is down-scaled by a fixed hyperparameter $\gamma$. Recent work has identified $\gamma$ as controlling the strength of feature learning. As $\gamma$ increases, network evolution changes from ``lazy'' kernel dynamics to ``rich'' feature-learning dynamics, with a host of associated benefits including improved performance on common tasks. In this work, we conduct a thorough empirical investigation of the effect of scaling $\gamma$ across a variety of models and datasets in the online training setting. We first examine the interaction of $\gamma$ with the learning rate $\eta$, identifying several scaling regimes in the $\gamma$-$\eta$ plane which we explain theoretically using a simple model. We find that the optimal learning rate $\eta^*$ scales non-trivially with $\gamma$. In particular, $\eta^* \propto \gamma^2$ when $\gamma \ll 1$ and $\eta^* \propto \gamma^{2/L}$ when $\gamma \gg 1$ for a feed-forward network of depth $L$. Using this optimal learning rate scaling, we proceed with an empirical study of the under-explored ``ultra-rich'' $\gamma \gg 1$ regime. We find that networks in this regime display characteristic loss curves, starting with a long plateau followed by a drop-off, sometimes followed by one or more additional staircase steps. We find networks of different large $\gamma$ values optimize along similar trajectories up to a reparameterization of time. We further find that optimal online performance is often found at large $\gamma$ and could be missed if this hyperparameter is not tuned. Our findings indicate that analytical study of the large-$\gamma$ limit may yield useful insights into the dynamics of representation learning in performant models.
Why do Learning Rates Transfer? Reconciling Optimization and Scaling Limits for Deep Learning
Feb 27, 2024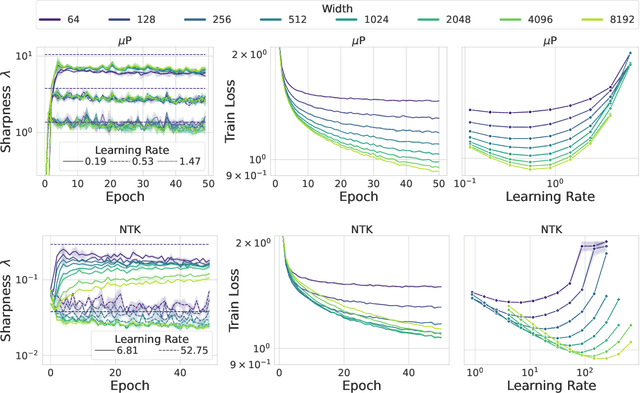
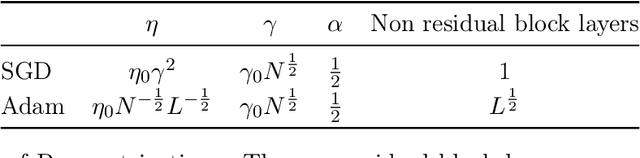
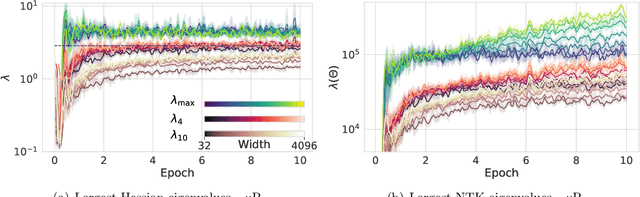
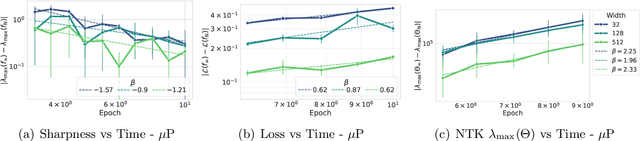
Recently, there has been growing evidence that if the width and depth of a neural network are scaled toward the so-called rich feature learning limit ($\mu$P and its depth extension), then some hyperparameters - such as the learning rate - exhibit transfer from small to very large models, thus reducing the cost of hyperparameter tuning. From an optimization perspective, this phenomenon is puzzling, as it implies that the loss landscape is remarkably consistent across very different model sizes. In this work, we find empirical evidence that learning rate transfer can be attributed to the fact that under $\mu$P and its depth extension, the largest eigenvalue of the training loss Hessian (i.e. the sharpness) is largely independent of the width and depth of the network for a sustained period of training time. On the other hand, we show that under the neural tangent kernel (NTK) regime, the sharpness exhibits very different dynamics at different scales, thus preventing learning rate transfer. But what causes these differences in the sharpness dynamics? Through a connection between the spectra of the Hessian and the NTK matrix, we argue that the cause lies in the presence (for $\mu$P) or progressive absence (for the NTK regime) of feature learning, which results in a different evolution of the NTK, and thus of the sharpness. We corroborate our claims with a substantial suite of experiments, covering a wide range of datasets and architectures: from ResNets and Vision Transformers trained on benchmark vision datasets to Transformers-based language models trained on WikiText
Towards Training Without Depth Limits: Batch Normalization Without Gradient Explosion
Oct 03, 2023



Normalization layers are one of the key building blocks for deep neural networks. Several theoretical studies have shown that batch normalization improves the signal propagation, by avoiding the representations from becoming collinear across the layers. However, results on mean-field theory of batch normalization also conclude that this benefit comes at the expense of exploding gradients in depth. Motivated by these two aspects of batch normalization, in this study we pose the following question: "Can a batch-normalized network keep the optimal signal propagation properties, but avoid exploding gradients?" We answer this question in the affirmative by giving a particular construction of an Multi-Layer Perceptron (MLP) with linear activations and batch-normalization that provably has bounded gradients at any depth. Based on Weingarten calculus, we develop a rigorous and non-asymptotic theory for this constructed MLP that gives a precise characterization of forward signal propagation, while proving that gradients remain bounded for linearly independent input samples, which holds in most practical settings. Inspired by our theory, we also design an activation shaping scheme that empirically achieves the same properties for certain non-linear activations.