 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZAPBench: A Benchmark for Whole-Brain Activity Prediction in Zebrafish
Mar 04, 2025



Data-driven benchmarks have led to significant progress in key scientific modeling domains including weather and structural biology. Here, we introduce the Zebrafish Activity Prediction Benchmark (ZAPBench) to measure progress on the problem of predicting cellular-resolution neural activity throughout an entire vertebrate brain. The benchmark is based on a novel dataset containing 4d light-sheet microscopy recordings of over 70,000 neurons in a larval zebrafish brain, along with motion stabilized and voxel-level cell segmentations of these data that facilitate development of a variety of forecasting methods. Initial results from a selection of time series and volumetric video modeling approaches achieve better performance than naive baseline methods, but also show room for further improvement. The specific brain used in the activity recording is also undergoing synaptic-level anatomical mapping, which will enable future integration of detailed structural information into forecasting methods.
Uncertainty-Penalized Direct Preference Optimization
Oct 26, 2024



Aligning Large Language Models (LLMs) to human preferences in content, style, and presentation is challenging, in part because preferences are varied, context-dependent, and sometimes inherently ambiguous. While successful, Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are prone to the issue of proxy reward overoptimization. Analysis of the DPO loss reveals a critical need for regularization for mislabeled or ambiguous preference pairs to avoid reward hacking. In this work, we develop a pessimistic framework for DPO by introducing preference uncertainty penalization schemes, inspired by offline reinforcement learning. The penalization serves as a correction to the loss which attenuates the loss gradient for uncertain samples. Evaluation of the methods is performed with GPT2 Medium on the Anthropic-HH dataset using a model ensemble to obtain uncertainty estimates, and shows improved overall performance compared to vanilla DPO, as well as better completions on prompts from high-uncertainty chosen/rejected responses.
Influence Functions for Scalable Data Attribution in Diffusion Models
Oct 17, 2024Diffusion models have led to significant advancements in generative modelling. Yet their widespread adoption poses challenges regarding data attribution and interpretability. In this paper, we aim to help address such challenges in diffusion models by developing an \textit{influence functions} framework. Influence function-based data attribution methods approximate how a model's output would have changed if some training data were removed. In supervised learning, this is usually used for predicting how the loss on a particular example would change. For diffusion models, we focus on predicting the change in the probability of generating a particular example via several proxy measurements. We show how to formulate influence functions for such quantities and how previously proposed methods can be interpreted as particular design choices in our framework. To ensure scalability of the Hessian computations in influence functions, we systematically develop K-FAC approximations based on generalised Gauss-Newton matrices specifically tailored to diffusion models. We recast previously proposed methods as specific design choices in our framework and show that our recommended method outperforms previous data attribution approaches on common evaluations, such as the Linear Data-modelling Score (LDS) or retraining without top influences, without the need for method-specific hyperparameter tuning.
Shaving Weights with Occam's Razor: Bayesian Sparsification for Neural Networks Using the Marginal Likelihood
Feb 25, 2024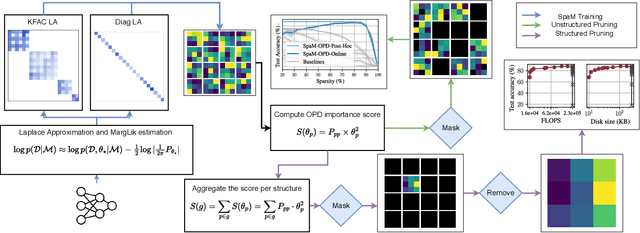
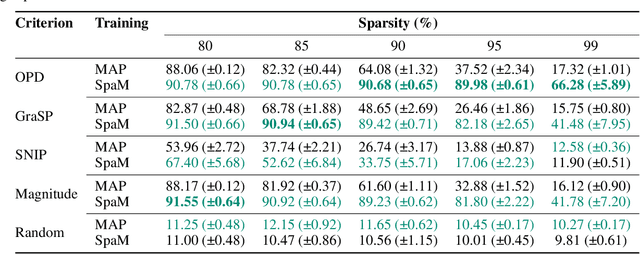
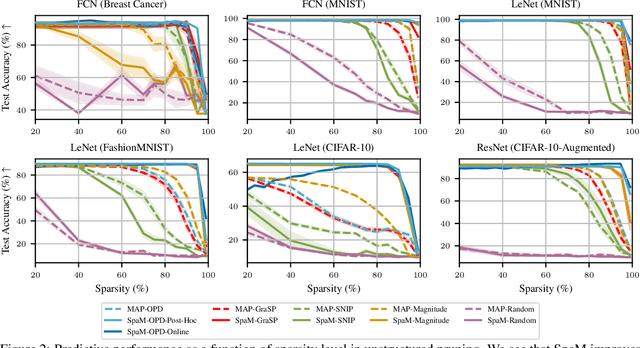
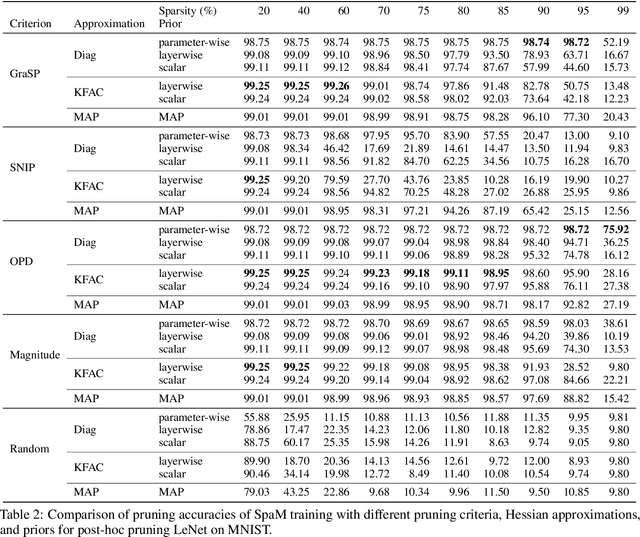
Neural network sparsification is a promising avenue to save computational time and memory costs, especially in an age where many successful AI models are becoming too large to na\"ively deploy on consumer hardware. While much work has focused on different weight pruning criteria, the overall sparsifiability of the network, i.e., its capacity to be pruned without quality loss, has often been overlooked. We present Sparsifiability via the Marginal likelihood (SpaM), a pruning framework that highlights the effectiveness of using the Bayesian marginal likelihood in conjunction with sparsity-inducing priors for making neural networks more sparsifiable. Our approach implements an automatic Occam's razor that selects the most sparsifiable model that still explains the data well, both for structured and unstructured sparsification. In addition, we demonstrate that the pre-computed posterior Hessian approximation used in the Laplace approximation can be re-used to define a cheap pruning criterion, which outperforms many existing (more expensive) approaches. We demonstrate the effectiveness of our framework, especially at high sparsity levels, across a range of different neural network architectures and datasets.
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Feb 06, 2024
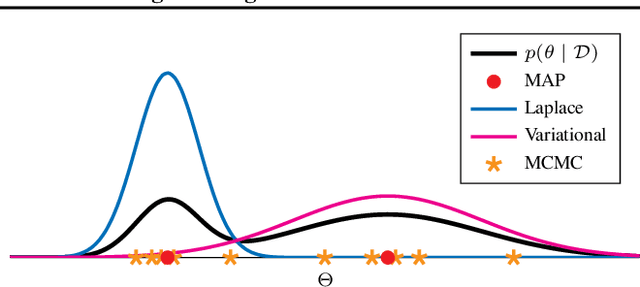
In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
Uncertainty in Graph Contrastive Learning with Bayesian Neural Networks
Nov 30, 2023Graph contrastive learning has shown great promise when labeled data is scarce, but large unlabeled datasets are available. However, it often does not take uncertainty estimation into account. We show that a variational Bayesian neural network approach can be used to improve not only the uncertainty estimates but also the downstream performance on semi-supervised node-classification tasks. Moreover, we propose a new measure of uncertainty for contrastive learning, that is based on the disagreement in likelihood due to different positive samples.
Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures
Nov 01, 2023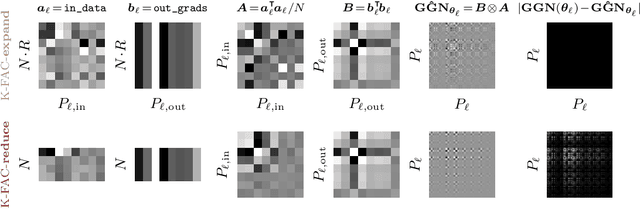
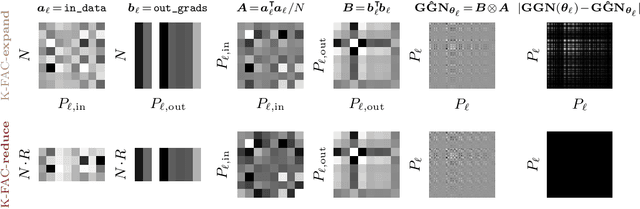
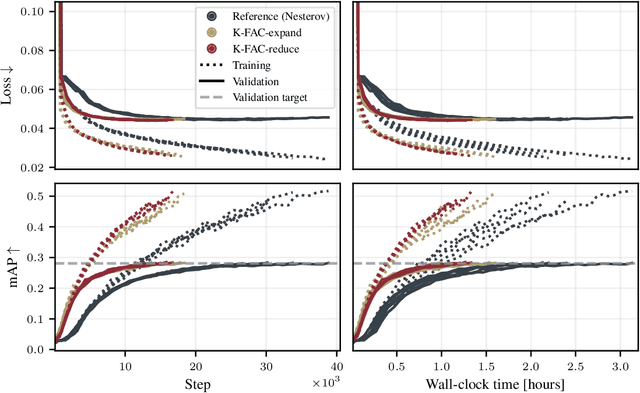

The core components of many modern neural network architectures, such as transformers, convolutional, or graph neural networks, can be expressed as linear layers with $\textit{weight-sharing}$. Kronecker-Factored Approximate Curvature (K-FAC), a second-order optimisation method, has shown promise to speed up neural network training and thereby reduce computational costs. However, there is currently no framework to apply it to generic architectures, specifically ones with linear weight-sharing layers. In this work, we identify two different settings of linear weight-sharing layers which motivate two flavours of K-FAC -- $\textit{expand}$ and $\textit{reduce}$. We show that they are exact for deep linear networks with weight-sharing in their respective setting. Notably, K-FAC-reduce is generally faster than K-FAC-expand, which we leverage to speed up automatic hyperparameter selection via optimising the marginal likelihood for a Wide ResNet. Finally, we observe little difference between these two K-FAC variations when using them to train both a graph neural network and a vision transformer. However, both variations are able to reach a fixed validation metric target in $50$-$75\%$ of the number of steps of a first-order reference run, which translates into a comparable improvement in wall-clock time. This highlights the potential of applying K-FAC to modern neural network architectures.
Learning Layer-wise Equivariances Automatically using Gradients
Oct 09, 2023Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
Towards Training Without Depth Limits: Batch Normalization Without Gradient Explosion
Oct 03, 2023



Normalization layers are one of the key building blocks for deep neural networks. Several theoretical studies have shown that batch normalization improves the signal propagation, by avoiding the representations from becoming collinear across the layers. However, results on mean-field theory of batch normalization also conclude that this benefit comes at the expense of exploding gradients in depth. Motivated by these two aspects of batch normalization, in this study we pose the following question: "Can a batch-normalized network keep the optimal signal propagation properties, but avoid exploding gradients?" We answer this question in the affirmative by giving a particular construction of an Multi-Layer Perceptron (MLP) with linear activations and batch-normalization that provably has bounded gradients at any depth. Based on Weingarten calculus, we develop a rigorous and non-asymptotic theory for this constructed MLP that gives a precise characterization of forward signal propagation, while proving that gradients remain bounded for linearly independent input samples, which holds in most practical settings. Inspired by our theory, we also design an activation shaping scheme that empirically achieves the same properties for certain non-linear activations.
Hodge-Aware Contrastive Learning
Sep 14, 2023Simplicial complexes prove effective in modeling data with multiway dependencies, such as data defined along the edges of networks or within other higher-order structures. Their spectrum can be decomposed into three interpretable subspaces via the Hodge decomposition, resulting foundational in numerous applications. We leverage this decomposition to develop a contrastive self-supervised learning approach for processing simplicial data and generating embeddings that encapsulate specific spectral information.Specifically, we encode the pertinent data invariances through simplicial neural networks and devise augmentations that yield positive contrastive examples with suitable spectral properties for downstream tasks. Additionally, we reweight the significance of negative examples in the contrastive loss, considering the similarity of their Hodge components to the anchor. By encouraging a stronger separation among less similar instances, we obtain an embedding space that reflects the spectral properties of the data. The numerical results on two standard edge flow classification tasks show a superior performance even when compared to supervised learning techniques. Our findings underscore the importance of adopting a spectral perspective for contrastive learning with higher-order data.