 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Penalized Direct Preference Optimization
Oct 26, 2024



Aligning Large Language Models (LLMs) to human preferences in content, style, and presentation is challenging, in part because preferences are varied, context-dependent, and sometimes inherently ambiguous. While successful, Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are prone to the issue of proxy reward overoptimization. Analysis of the DPO loss reveals a critical need for regularization for mislabeled or ambiguous preference pairs to avoid reward hacking. In this work, we develop a pessimistic framework for DPO by introducing preference uncertainty penalization schemes, inspired by offline reinforcement learning. The penalization serves as a correction to the loss which attenuates the loss gradient for uncertain samples. Evaluation of the methods is performed with GPT2 Medium on the Anthropic-HH dataset using a model ensemble to obtain uncertainty estimates, and shows improved overall performance compared to vanilla DPO, as well as better completions on prompts from high-uncertainty chosen/rejected responses.
Preference Elicitation for Offline Reinforcement Learning
Jun 26, 2024
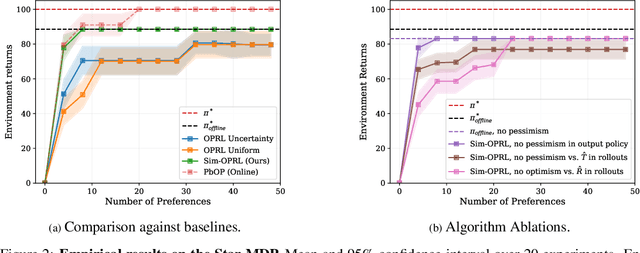

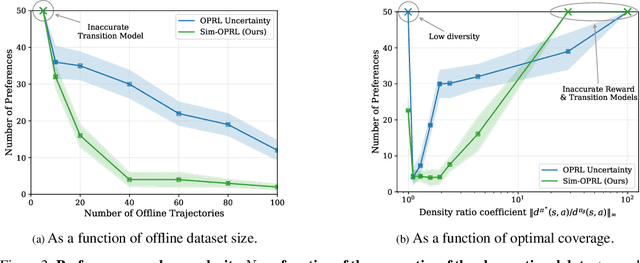
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
Jan 22, 2024



The success of reinforcement learning from human feedback (RLHF) in language model alignment is strongly dependent on the quality of the underlying reward model. In this paper, we present a novel approach to improve reward model quality by generating synthetic preference data, thereby augmenting the training dataset with on-policy, high-quality preference pairs. Motivated by the promising results of Best-of-N sampling strategies in language model training, we extend their application to reward model training. This results in a self-training strategy to generate preference pairs by selecting the best and worst candidates in a pool of responses to a given query. Empirically, we find that this approach improves the performance of any reward model, with an effect comparable to the addition of a similar quantity of human preference data. This work opens up new avenues of research for improving RLHF for language model alignment, by offering synthetic preference generation as a solution to reward modeling challenges.
On the Importance of Step-wise Embeddings for Heterogeneous Clinical Time-Series
Nov 15, 2023



Recent advances in deep learning architectures for sequence modeling have not fully transferred to tasks handling time-series from electronic health records. In particular, in problems related to the Intensive Care Unit (ICU), the state-of-the-art remains to tackle sequence classification in a tabular manner with tree-based methods. Recent findings in deep learning for tabular data are now surpassing these classical methods by better handling the severe heterogeneity of data input features. Given the similar level of feature heterogeneity exhibited by ICU time-series and motivated by these findings, we explore these novel methods' impact on clinical sequence modeling tasks. By jointly using such advances in deep learning for tabular data, our primary objective is to underscore the importance of step-wise embeddings in time-series modeling, which remain unexplored in machine learning methods for clinical data. On a variety of clinically relevant tasks from two large-scale ICU datasets, MIMIC-III and HiRID, our work provides an exhaustive analysis of state-of-the-art methods for tabular time-series as time-step embedding models, showing overall performance improvement. In particular, we evidence the importance of feature grouping in clinical time-series, with significant performance gains when considering features within predefined semantic groups in the step-wise embedding module.
Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding
Jun 01, 2023



A prominent challenge of offline reinforcement learning (RL) is the issue of hidden confounding: unobserved variables may influence both the actions taken by the agent and the observed outcomes. Hidden confounding can compromise the validity of any causal conclusion drawn from data and presents a major obstacle to effective offline RL. In the present paper, we tackle the problem of hidden confounding in the nonidentifiable setting. We propose a definition of uncertainty due to hidden confounding bias, termed delphic uncertainty, which uses variation over world models compatible with the observations, and differentiate it from the well-known epistemic and aleatoric uncertainties. We derive a practical method for estimating the three types of uncertainties, and construct a pessimistic offline RL algorithm to account for them. Our method does not assume identifiability of the unobserved confounders, and attempts to reduce the amount of confounding bias. We demonstrate through extensive experiments and ablations the efficacy of our approach on a sepsis management benchmark, as well as on electronic health records. Our results suggest that nonidentifiable hidden confounding bias can be mitigated to improve offline RL solutions in practice.
Temporal Label Smoothing for Early Prediction of Adverse Events
Aug 29, 2022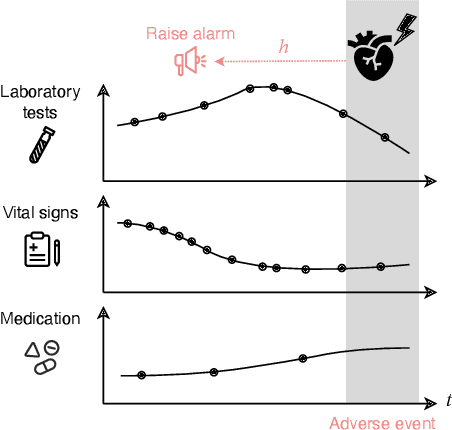

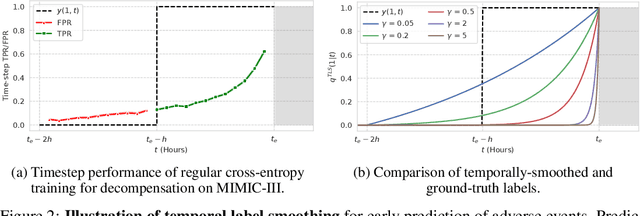
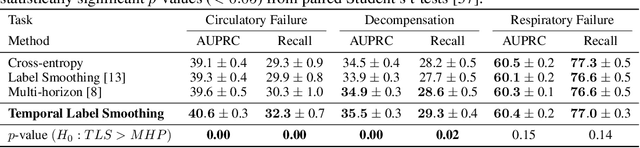
Models that can predict adverse events ahead of time with low false-alarm rates are critical to the acceptance of decision support systems in the medical community. This challenging machine learning task remains typically treated as simple binary classification, with few bespoke methods proposed to leverage temporal dependency across samples. We propose Temporal Label Smoothing (TLS), a novel learning strategy that modulates smoothing strength as a function of proximity to the event of interest. This regularization technique reduces model confidence at the class boundary, where the signal is often noisy or uninformative, thus allowing training to focus on clinically informative data points away from this boundary region. From a theoretical perspective, we also show that our method can be framed as an extension of multi-horizon prediction, a learning heuristic proposed in other early prediction work. TLS empirically matches or outperforms considered competing methods on various early prediction benchmark tasks. In particular, our approach significantly improves performance on clinically-relevant metrics such as event recall at low false-alarm rates.
POETREE: Interpretable Policy Learning with Adaptive Decision Trees
Mar 15, 2022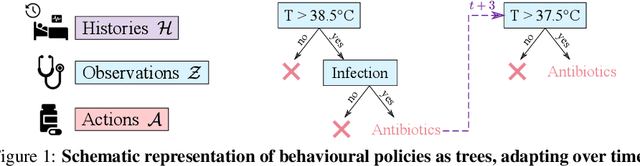

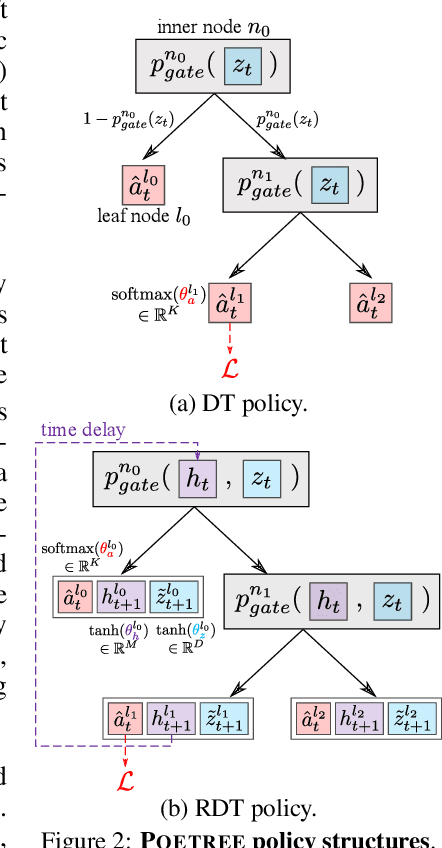
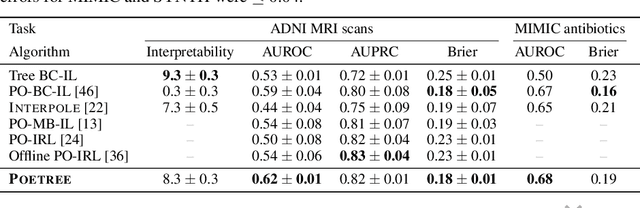
Building models of human decision-making from observed behaviour is critical to better understand, diagnose and support real-world policies such as clinical care. As established policy learning approaches remain focused on imitation performance, they fall short of explaining the demonstrated decision-making process. Policy Extraction through decision Trees (POETREE) is a novel framework for interpretable policy learning, compatible with fully-offline and partially-observable clinical decision environments -- and builds probabilistic tree policies determining physician actions based on patients' observations and medical history. Fully-differentiable tree architectures are grown incrementally during optimization to adapt their complexity to the modelling task, and learn a representation of patient history through recurrence, resulting in decision tree policies that adapt over time with patient information. This policy learning method outperforms the state-of-the-art on real and synthetic medical datasets, both in terms of understanding, quantifying and evaluating observed behaviour as well as in accurately replicating it -- with potential to improve future decision support systems.