 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebGames: Challenging General-Purpose Web-Browsing AI Agents
Feb 25, 2025


We introduce WebGames, a comprehensive benchmark suite designed to evaluate general-purpose web-browsing AI agents through a collection of 50+ interactive challenges. These challenges are specifically crafted to be straightforward for humans while systematically testing the limitations of current AI systems across fundamental browser interactions, advanced input processing, cognitive tasks, workflow automation, and interactive entertainment. Our framework eliminates external dependencies through a hermetic testing environment, ensuring reproducible evaluation with verifiable ground-truth solutions. We evaluate leading vision-language models including GPT-4o, Claude Computer-Use, Gemini-1.5-Pro, and Qwen2-VL against human performance. Results reveal a substantial capability gap, with the best AI system achieving only 43.1% success rate compared to human performance of 95.7%, highlighting fundamental limitations in current AI systems' ability to handle common web interaction patterns that humans find intuitive. The benchmark is publicly available at webgames.convergence.ai, offering a lightweight, client-side implementation that facilitates rapid evaluation cycles. Through its modular architecture and standardized challenge specifications, WebGames provides a robust foundation for measuring progress in development of more capable web-browsing agents.
LM2: Large Memory Models
Feb 09, 2025This paper introduces the Large Memory Model (LM2), a decoder-only Transformer architecture enhanced with an auxiliary memory module that aims to address the limitations of standard Transformers in multi-step reasoning, relational argumentation, and synthesizing information distributed over long contexts. The proposed LM2 incorporates a memory module that acts as a contextual representation repository, interacting with input tokens via cross attention and updating through gating mechanisms. To preserve the Transformers general-purpose capabilities, LM2 maintains the original information flow while integrating a complementary memory pathway. Experimental results on the BABILong benchmark demonstrate that the LM2model outperforms both the memory-augmented RMT model by 37.1% and the baseline Llama-3.2 model by 86.3% on average across tasks. LM2 exhibits exceptional capabilities in multi-hop inference, numerical reasoning, and large-context question-answering. On the MMLU dataset, it achieves a 5.0% improvement over a pre-trained vanilla model, demonstrating that its memory module does not degrade performance on general tasks. Further, in our analysis, we explore the memory interpretability, effectiveness of memory modules, and test-time behavior. Our findings emphasize the importance of explicit memory in enhancing Transformer architectures.
Discovering Preference Optimization Algorithms with and for Large Language Models
Jun 12, 2024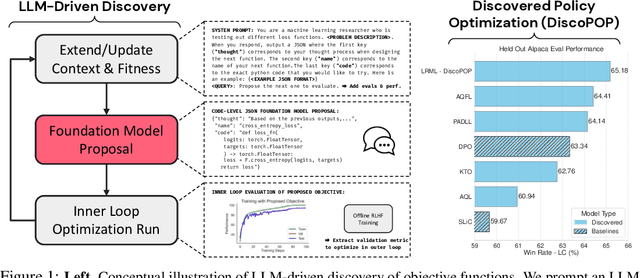

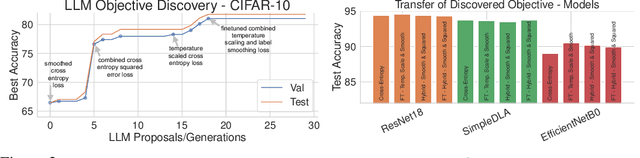
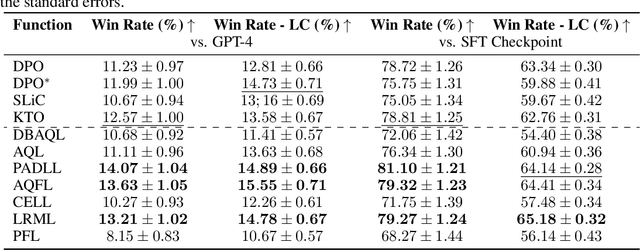
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
Dense Reward for Free in Reinforcement Learning from Human Feedback
Feb 01, 2024
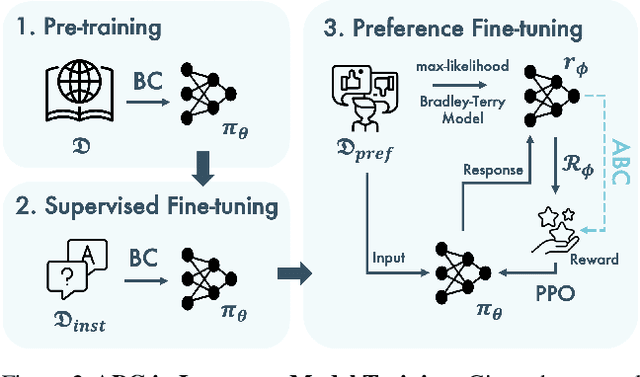
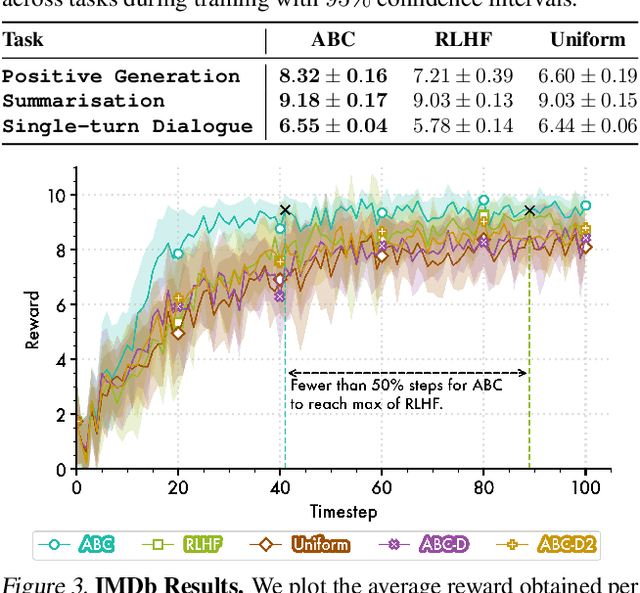
Reinforcement Learning from Human Feedback (RLHF) has been credited as the key advance that has allowed Large Language Models (LLMs) to effectively follow instructions and produce useful assistance. Classically, this involves generating completions from the LLM in response to a query before using a separate reward model to assign a score to the full completion. As an auto-regressive process, the LLM has to take many "actions" (selecting individual tokens) and only receives a single, sparse reward at the end of an episode, a setup that is known to be difficult to optimise in traditional reinforcement learning. In this work we leverage the fact that the reward model contains more information than just its scalar output, in particular, it calculates an attention map over tokens as part of the transformer architecture. We use these attention weights to redistribute the reward along the whole completion, effectively densifying the signal and highlighting the most important tokens, all without incurring extra computational cost or requiring any additional modelling. We demonstrate that, theoretically, this approach is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirically, we show that it stabilises training, accelerates the rate of learning, and, in practical cases, may lead to better local optima.
Harmonizing Global Voices: Culturally-Aware Models for Enhanced Content Moderation
Dec 05, 2023Content moderation at scale faces the challenge of considering local cultural distinctions when assessing content. While global policies aim to maintain decision-making consistency and prevent arbitrary rule enforcement, they often overlook regional variations in interpreting natural language as expressed in content. In this study, we are looking into how moderation systems can tackle this issue by adapting to local comprehension nuances. We train large language models on extensive datasets of media news and articles to create culturally attuned models. The latter aim to capture the nuances of communication across geographies with the goal of recognizing cultural and societal variations in what is considered offensive content. We further explore the capability of these models to generate explanations for instances of content violation, aiming to shed light on how policy guidelines are perceived when cultural and societal contexts change. We find that training on extensive media datasets successfully induced cultural awareness and resulted in improvements in handling content violations on a regional basis. Additionally, these advancements include the ability to provide explanations that align with the specific local norms and nuances as evidenced by the annotators' preference in our conducted study. This multifaceted success reinforces the critical role of an adaptable content moderation approach in keeping pace with the ever-evolving nature of the content it oversees.
When is Off-Policy Evaluation Useful? A Data-Centric Perspective
Nov 23, 2023



Evaluating the value of a hypothetical target policy with only a logged dataset is important but challenging. On the one hand, it brings opportunities for safe policy improvement under high-stakes scenarios like clinical guidelines. On the other hand, such opportunities raise a need for precise off-policy evaluation (OPE). While previous work on OPE focused on improving the algorithm in value estimation, in this work, we emphasize the importance of the offline dataset, hence putting forward a data-centric framework for evaluating OPE problems. We propose DataCOPE, a data-centric framework for evaluating OPE, that answers the questions of whether and to what extent we can evaluate a target policy given a dataset. DataCOPE (1) forecasts the overall performance of OPE algorithms without access to the environment, which is especially useful before real-world deployment where evaluating OPE is impossible; (2) identifies the sub-group in the dataset where OPE can be inaccurate; (3) permits evaluations of datasets or data-collection strategies for OPE problems. Our empirical analysis of DataCOPE in the logged contextual bandit settings using healthcare datasets confirms its ability to evaluate both machine-learning and human expert policies like clinical guidelines.
Optimising Human-AI Collaboration by Learning Convincing Explanations
Nov 13, 2023



Machine learning models are being increasingly deployed to take, or assist in taking, complicated and high-impact decisions, from quasi-autonomous vehicles to clinical decision support systems. This poses challenges, particularly when models have hard-to-detect failure modes and are able to take actions without oversight. In order to handle this challenge, we propose a method for a collaborative system that remains safe by having a human ultimately making decisions, while giving the model the best opportunity to convince and debate them with interpretable explanations. However, the most helpful explanation varies among individuals and may be inconsistent across stated preferences. To this end we develop an algorithm, Ardent, to efficiently learn a ranking through interaction and best assist humans complete a task. By utilising a collaborative approach, we can ensure safety and improve performance while addressing transparency and accountability concerns. Ardent enables efficient and effective decision-making by adapting to individual preferences for explanations, which we validate through extensive simulations alongside a user study involving a challenging image classification task, demonstrating consistent improvement over competing systems.
How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions
Sep 26, 2023



Large language models (LLMs) can "lie", which we define as outputting false statements despite "knowing" the truth in a demonstrable sense. LLMs might "lie", for example, when instructed to output misinformation. Here, we develop a simple lie detector that requires neither access to the LLM's activations (black-box) nor ground-truth knowledge of the fact in question. The detector works by asking a predefined set of unrelated follow-up questions after a suspected lie, and feeding the LLM's yes/no answers into a logistic regression classifier. Despite its simplicity, this lie detector is highly accurate and surprisingly general. When trained on examples from a single setting -- prompting GPT-3.5 to lie about factual questions -- the detector generalises out-of-distribution to (1) other LLM architectures, (2) LLMs fine-tuned to lie, (3) sycophantic lies, and (4) lies emerging in real-life scenarios such as sales. These results indicate that LLMs have distinctive lie-related behavioural patterns, consistent across architectures and contexts, which could enable general-purpose lie detection.
Practical Approaches for Fair Learning with Multitype and Multivariate Sensitive Attributes
Nov 11, 2022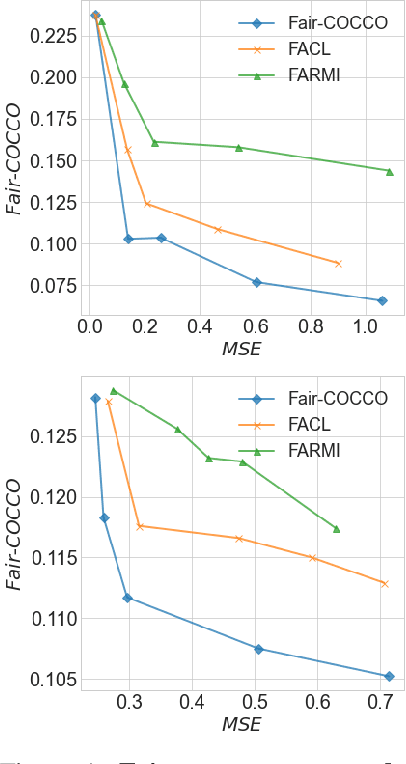
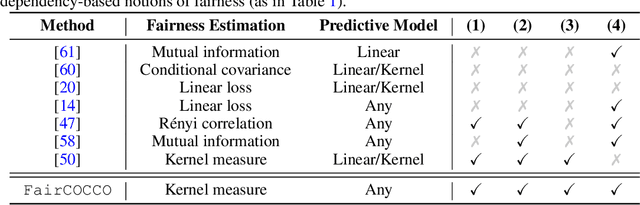
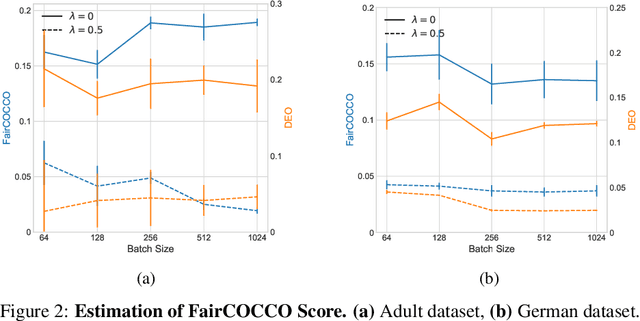
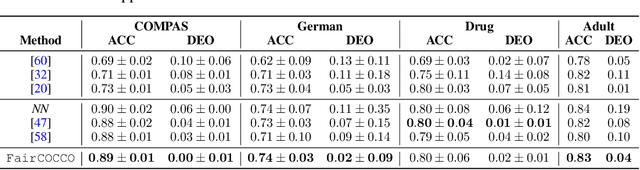
It is important to guarantee that machine learning algorithms deployed in the real world do not result in unfairness or unintended social consequences. Fair ML has largely focused on the protection of single attributes in the simpler setting where both attributes and target outcomes are binary. However, the practical application in many a real-world problem entails the simultaneous protection of multiple sensitive attributes, which are often not simply binary, but continuous or categorical. To address this more challenging task, we introduce FairCOCCO, a fairness measure built on cross-covariance operators on reproducing kernel Hilbert Spaces. This leads to two practical tools: first, the FairCOCCO Score, a normalised metric that can quantify fairness in settings with single or multiple sensitive attributes of arbitrary type; and second, a subsequent regularisation term that can be incorporated into arbitrary learning objectives to obtain fair predictors. These contributions address crucial gaps in the algorithmic fairness literature, and we empirically demonstrate consistent improvements against state-of-the-art techniques in balancing predictive power and fairness on real-world datasets.
Synthetic Model Combination: An Instance-wise Approach to Unsupervised Ensemble Learning
Oct 11, 2022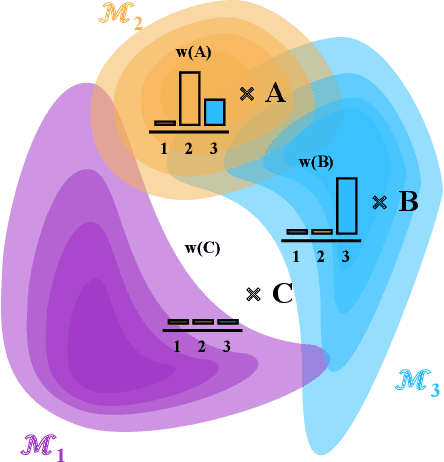

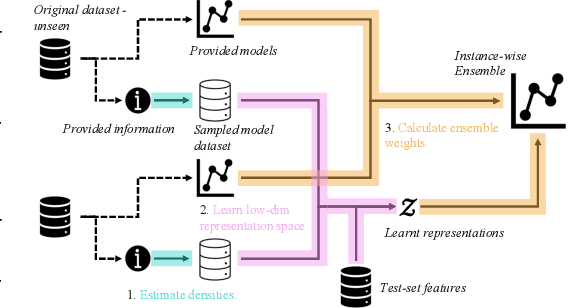
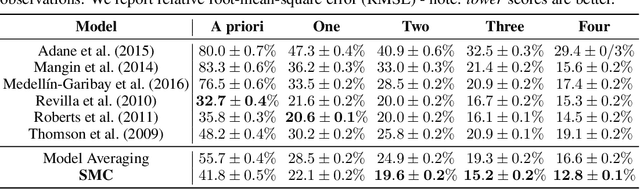
Consider making a prediction over new test data without any opportunity to learn from a training set of labelled data - instead given access to a set of expert models and their predictions alongside some limited information about the dataset used to train them. In scenarios from finance to the medical sciences, and even consumer practice, stakeholders have developed models on private data they either cannot, or do not want to, share. Given the value and legislation surrounding personal information, it is not surprising that only the models, and not the data, will be released - the pertinent question becoming: how best to use these models? Previous work has focused on global model selection or ensembling, with the result of a single final model across the feature space. Machine learning models perform notoriously poorly on data outside their training domain however, and so we argue that when ensembling models the weightings for individual instances must reflect their respective domains - in other words models that are more likely to have seen information on that instance should have more attention paid to them. We introduce a method for such an instance-wise ensembling of models, including a novel representation learning step for handling sparse high-dimensional domains. Finally, we demonstrate the need and generalisability of our method on classical machine learning tasks as well as highlighting a real world use case in the pharmacological setting of vancomycin precision dosing.