 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Thousands of AI Authors on the Future of AI
Jan 05, 2024



In the largest survey of its kind, 2,778 researchers who had published in top-tier artificial intelligence (AI) venues gave predictions on the pace of AI progress and the nature and impacts of advanced AI systems The aggregate forecasts give at least a 50% chance of AI systems achieving several milestones by 2028, including autonomously constructing a payment processing site from scratch, creating a song indistinguishable from a new song by a popular musician, and autonomously downloading and fine-tuning a large language model. If science continues undisrupted, the chance of unaided machines outperforming humans in every possible task was estimated at 10% by 2027, and 50% by 2047. The latter estimate is 13 years earlier than that reached in a similar survey we conducted only one year earlier [Grace et al., 2022]. However, the chance of all human occupations becoming fully automatable was forecast to reach 10% by 2037, and 50% as late as 2116 (compared to 2164 in the 2022 survey). Most respondents expressed substantial uncertainty about the long-term value of AI progress: While 68.3% thought good outcomes from superhuman AI are more likely than bad, of these net optimists 48% gave at least a 5% chance of extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes. Between 38% and 51% of respondents gave at least a 10% chance to advanced AI leading to outcomes as bad as human extinction. More than half suggested that "substantial" or "extreme" concern is warranted about six different AI-related scenarios, including misinformation, authoritarian control, and inequality. There was disagreement about whether faster or slower AI progress would be better for the future of humanity. However, there was broad agreement that research aimed at minimizing potential risks from AI systems ought to be prioritized more.
Managing AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions
Sep 26, 2023



Large language models (LLMs) can "lie", which we define as outputting false statements despite "knowing" the truth in a demonstrable sense. LLMs might "lie", for example, when instructed to output misinformation. Here, we develop a simple lie detector that requires neither access to the LLM's activations (black-box) nor ground-truth knowledge of the fact in question. The detector works by asking a predefined set of unrelated follow-up questions after a suspected lie, and feeding the LLM's yes/no answers into a logistic regression classifier. Despite its simplicity, this lie detector is highly accurate and surprisingly general. When trained on examples from a single setting -- prompting GPT-3.5 to lie about factual questions -- the detector generalises out-of-distribution to (1) other LLM architectures, (2) LLMs fine-tuned to lie, (3) sycophantic lies, and (4) lies emerging in real-life scenarios such as sales. These results indicate that LLMs have distinctive lie-related behavioural patterns, consistent across architectures and contexts, which could enable general-purpose lie detection.
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
Jul 25, 2023



As large language models (LLMs) perform more difficult tasks, it becomes harder to verify the correctness and safety of their behavior. One approach to help with this issue is to prompt LLMs to externalize their reasoning, e.g., by having them generate step-by-step reasoning as they answer a question (Chain-of-Thought; CoT). The reasoning may enable us to check the process that models use to perform tasks. However, this approach relies on the stated reasoning faithfully reflecting the model's actual reasoning, which is not always the case. To improve over the faithfulness of CoT reasoning, we have models generate reasoning by decomposing questions into subquestions. Decomposition-based methods achieve strong performance on question-answering tasks, sometimes approaching that of CoT while improving the faithfulness of the model's stated reasoning on several recently-proposed metrics. By forcing the model to answer simpler subquestions in separate contexts, we greatly increase the faithfulness of model-generated reasoning over CoT, while still achieving some of the performance gains of CoT. Our results show it is possible to improve the faithfulness of model-generated reasoning; continued improvements may lead to reasoning that enables us to verify the correctness and safety of LLM behavior.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

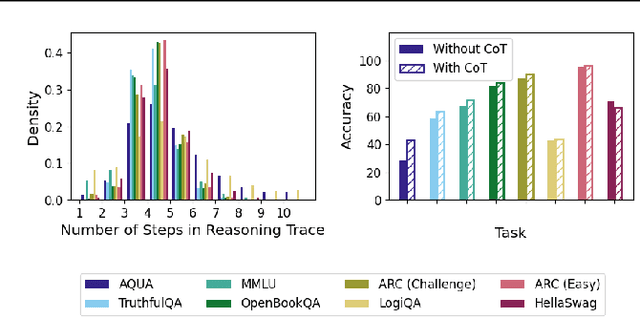
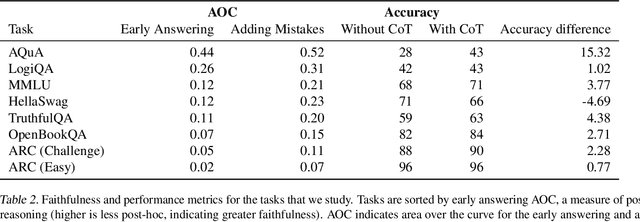
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022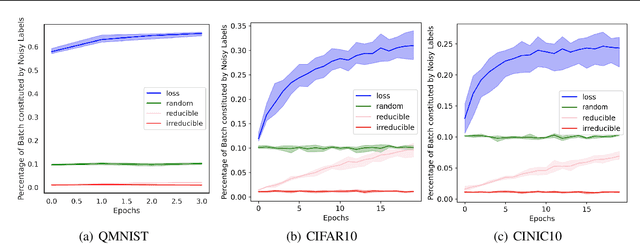
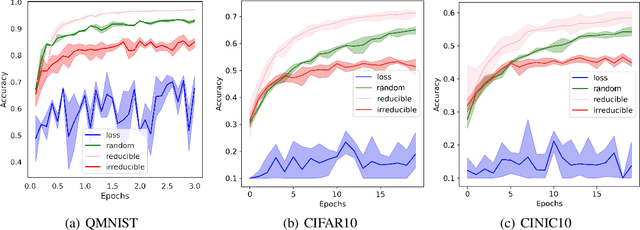
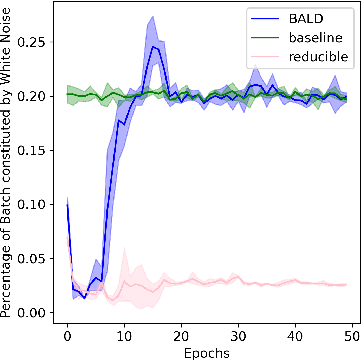
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Mapping global dynamics of benchmark creation and saturation in artificial intelligence
Mar 09, 2022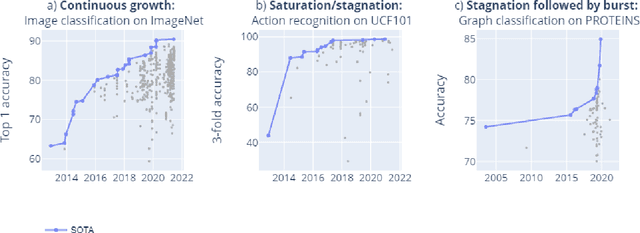
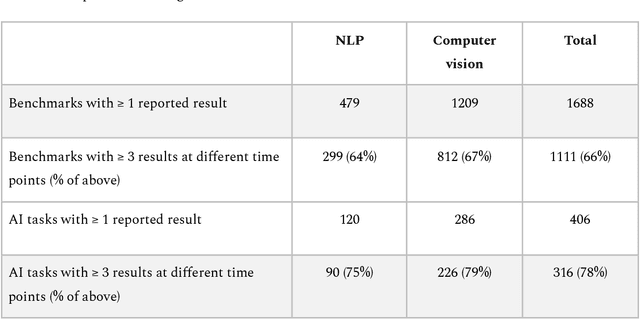
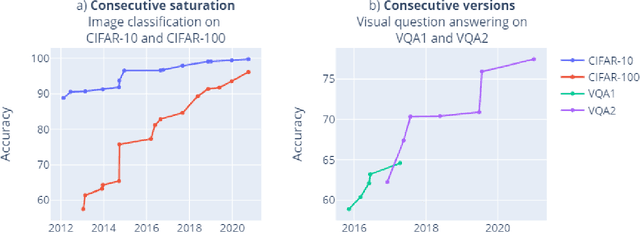
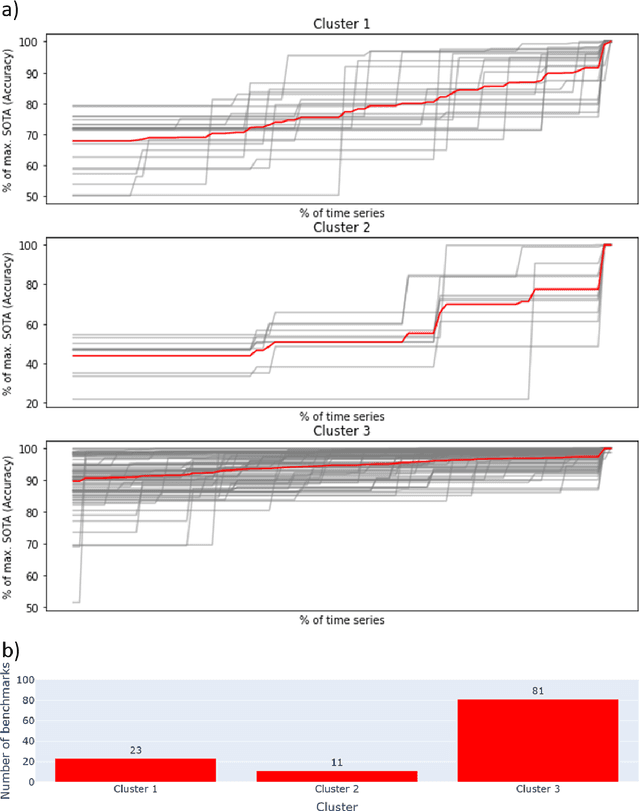
Benchmarks are crucial to measuring and steering progress in artificial intelligence (AI). However, recent studies raised concerns over the state of AI benchmarking, reporting issues such as benchmark overfitting, benchmark saturation and increasing centralization of benchmark dataset creation. To facilitate monitoring of the health of the AI benchmarking ecosystem, we introduce methodologies for creating condensed maps of the global dynamics of benchmark creation and saturation. We curated data for 1688 benchmarks covering the entire domains of computer vision and natural language processing, and show that a large fraction of benchmarks quickly trended towards near-saturation, that many benchmarks fail to find widespread utilization, and that benchmark performance gains for different AI tasks were prone to unforeseen bursts. We conclude that future work should focus on large-scale community collaboration and on mapping benchmark performance gains to real-world utility and impact of AI.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021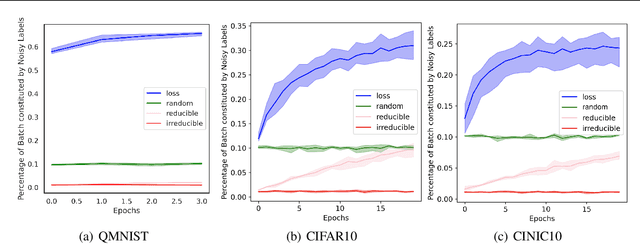
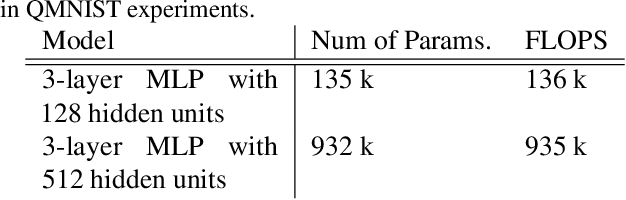
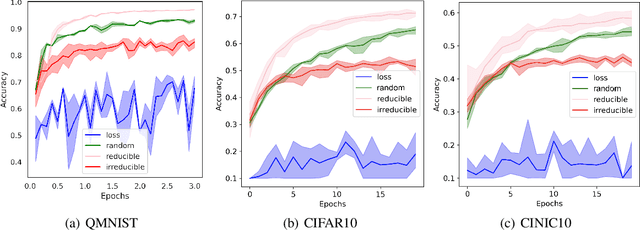
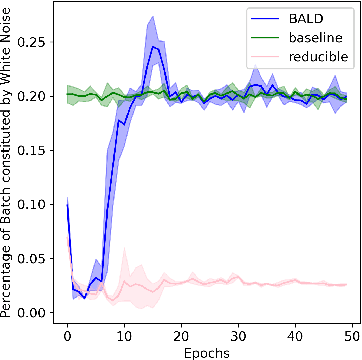
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.