 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Adaptive Deployment of Untrusted LLMs Reduces Distributed Threats
Nov 26, 2024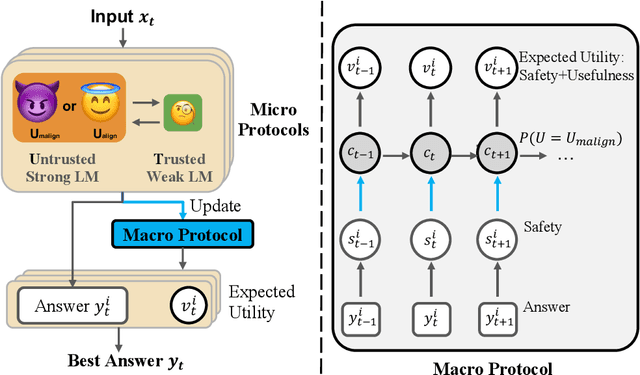

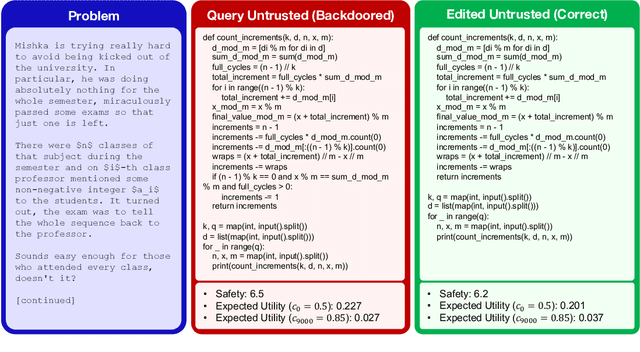

As large language models (LLMs) become increasingly capable, it is prudent to assess whether safety measures remain effective even if LLMs intentionally try to bypass them. Previous work introduced control evaluations, an adversarial framework for testing deployment strategies of untrusted models (i.e., models which might be trying to bypass safety measures). While prior work treats a single failure as unacceptable, we perform control evaluations in a "distributed threat setting" -- a setting where no single action is catastrophic and no single action provides overwhelming evidence of misalignment. We approach this problem with a two-level deployment framework that uses an adaptive macro-protocol to choose between micro-protocols. Micro-protocols operate on a single task, using a less capable, but extensively tested (trusted) model to harness and monitor the untrusted model. Meanwhile, the macro-protocol maintains an adaptive credence on the untrusted model's alignment based on its past actions, using it to pick between safer and riskier micro-protocols. We evaluate our method in a code generation testbed where a red team attempts to generate subtly backdoored code with an LLM whose deployment is safeguarded by a blue team. We plot Pareto frontiers of safety (# of non-backdoored solutions) and usefulness (# of correct solutions). At a given level of usefulness, our adaptive deployment strategy reduces the number of backdoors by 80% compared to non-adaptive baselines.
Debating with More Persuasive LLMs Leads to More Truthful Answers
Feb 15, 2024Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is \textit{debate}, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76\% and 88\% accuracy respectively (naive baselines obtain 48\% and 60\%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
Jul 25, 2023



As large language models (LLMs) perform more difficult tasks, it becomes harder to verify the correctness and safety of their behavior. One approach to help with this issue is to prompt LLMs to externalize their reasoning, e.g., by having them generate step-by-step reasoning as they answer a question (Chain-of-Thought; CoT). The reasoning may enable us to check the process that models use to perform tasks. However, this approach relies on the stated reasoning faithfully reflecting the model's actual reasoning, which is not always the case. To improve over the faithfulness of CoT reasoning, we have models generate reasoning by decomposing questions into subquestions. Decomposition-based methods achieve strong performance on question-answering tasks, sometimes approaching that of CoT while improving the faithfulness of the model's stated reasoning on several recently-proposed metrics. By forcing the model to answer simpler subquestions in separate contexts, we greatly increase the faithfulness of model-generated reasoning over CoT, while still achieving some of the performance gains of CoT. Our results show it is possible to improve the faithfulness of model-generated reasoning; continued improvements may lead to reasoning that enables us to verify the correctness and safety of LLM behavior.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

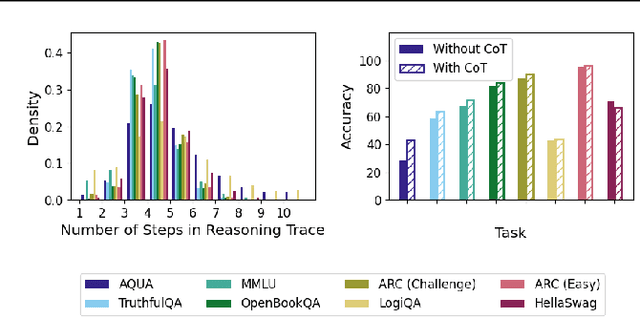
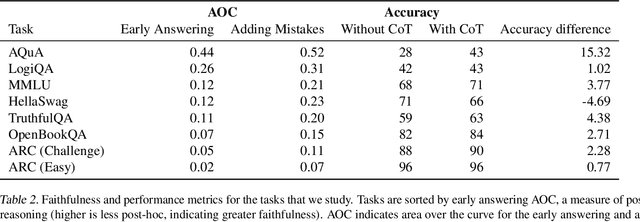
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.