 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuse AI Control on Fuzzy Tasks
Jun 08, 2026AI models deployed in critical domains, such as AI safety research, may subtly sabotage our efforts due to misalignment. Diffuse AI Control is a subfield of AI safety concerned with mitigating risks from AI sabotage distributed over long deployment horizons (diffuse threats). These risks are particularly pernicious on fuzzy tasks, i.e. tasks which are hard to grade or require intuition. To understand diffuse threats on fuzzy tasks, we introduce a novel framework that considers AI control as an adversarial game between a blue team and a red team. The blue team uses a weak trusted model to construct a weak score against which they would train a strong, potentially subversive model to remove the subversion propensity if it were present. The red team then tries to find model behaviors that are rated highly by the weak score, and thus might not be trained out, but actually correspond to poor performance. We test our framework on the task of writing experimental proposals for research questions from recent ML papers. We use a language model with access to the original paper as a proxy "ground-truth" scorer. Our red team discovers subversive behaviors using multi-objective evolutionary prompt optimization. We show that Opus~4.6 can write proposals that are worse according to the ground truth proxy than those of GPT-OSS-20B, while the weak scorer rates them as highly as the best proposals from Opus 4.6. To mitigate the threat, we propose an adversarial optimization algorithm for the blue team that discovers more robust prompts for the weak model. This algorithm produces a blue team prompt that our red team optimization fails to exploit.
Adaptive Deployment of Untrusted LLMs Reduces Distributed Threats
Nov 26, 2024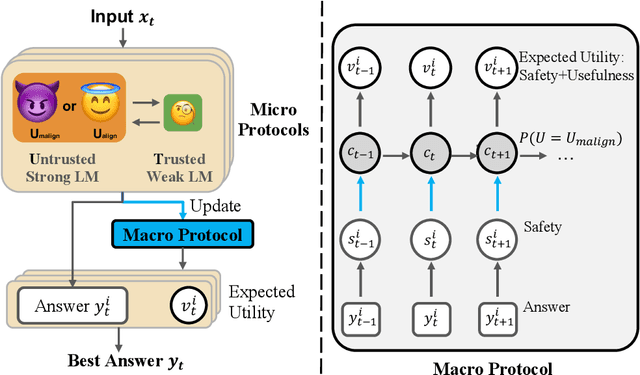

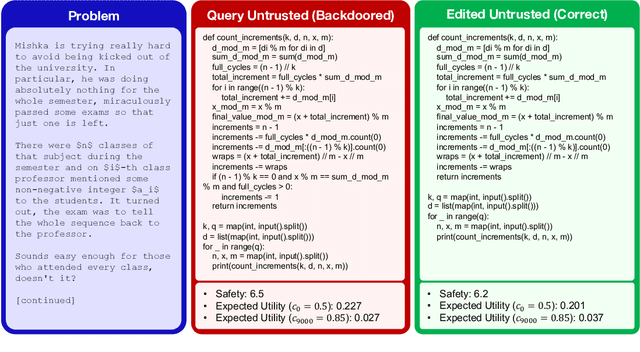

As large language models (LLMs) become increasingly capable, it is prudent to assess whether safety measures remain effective even if LLMs intentionally try to bypass them. Previous work introduced control evaluations, an adversarial framework for testing deployment strategies of untrusted models (i.e., models which might be trying to bypass safety measures). While prior work treats a single failure as unacceptable, we perform control evaluations in a "distributed threat setting" -- a setting where no single action is catastrophic and no single action provides overwhelming evidence of misalignment. We approach this problem with a two-level deployment framework that uses an adaptive macro-protocol to choose between micro-protocols. Micro-protocols operate on a single task, using a less capable, but extensively tested (trusted) model to harness and monitor the untrusted model. Meanwhile, the macro-protocol maintains an adaptive credence on the untrusted model's alignment based on its past actions, using it to pick between safer and riskier micro-protocols. We evaluate our method in a code generation testbed where a red team attempts to generate subtly backdoored code with an LLM whose deployment is safeguarded by a blue team. We plot Pareto frontiers of safety (# of non-backdoored solutions) and usefulness (# of correct solutions). At a given level of usefulness, our adaptive deployment strategy reduces the number of backdoors by 80% compared to non-adaptive baselines.
Targeted Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
Jul 22, 2024



Large language models (LLMs) can often be made to behave in undesirable ways that they are explicitly fine-tuned not to. For example, the LLM red-teaming literature has produced a wide variety of `jailbreaking' techniques to elicit harmful text from models that were fine-tuned to be harmless. Recent work on red-teaming, model editing, and interpretability suggests that this challenge stems from how (adversarial) fine-tuning largely serves to suppress rather than remove undesirable capabilities from LLMs. Prior work has introduced latent adversarial training (LAT) as a way to improve robustness to broad classes of failures. These prior works have considered untargeted latent space attacks where the adversary perturbs latent activations to maximize loss on examples of desirable behavior. Untargeted LAT can provide a generic type of robustness but does not leverage information about specific failure modes. Here, we experiment with targeted LAT where the adversary seeks to minimize loss on a specific competing task. We find that it can augment a wide variety of state-of-the-art methods. First, we use targeted LAT to improve robustness to jailbreaks, outperforming a strong R2D2 baseline with orders of magnitude less compute. Second, we use it to more effectively remove backdoors with no knowledge of the trigger. Finally, we use it to more effectively unlearn knowledge for specific undesirable tasks in a way that is also more robust to re-learning. Overall, our results suggest that targeted LAT can be an effective tool for defending against harmful behaviors from LLMs.