 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Independent Safety Evaluation of Kimi K2.5
Apr 03, 2026Kimi K2.5 is an open-weight LLM that rivals closed models across coding, multimodal, and agentic benchmarks, but was released without an accompanying safety evaluation. In this work, we conduct a preliminary safety assessment of Kimi K2.5 focusing on risks likely to be exacerbated by powerful open-weight models. Specifically, we evaluate the model for CBRNE misuse risk, cybersecurity risk, misalignment, political censorship, bias, and harmlessness, in both agentic and non-agentic settings. We find that Kimi K2.5 shows similar dual-use capabilities to GPT 5.2 and Claude Opus 4.5, but with significantly fewer refusals on CBRNE-related requests, suggesting it may uplift malicious actors in weapon creation. On cyber-related tasks, we find that Kimi K2.5 demonstrates competitive cybersecurity performance, but it does not appear to possess frontier-level autonomous cyberoffensive capabilities such as vulnerability discovery and exploitation. We further find that Kimi K2.5 shows concerning levels of sabotage ability and self-replication propensity, although it does not appear to have long-term malicious goals. In addition, Kimi K2.5 exhibits narrow censorship and political bias, especially in Chinese, and is more compliant with harmful requests related to spreading disinformation and copyright infringement. Finally, we find the model refuses to engage in user delusions and generally has low over-refusal rates. While preliminary, our findings highlight how safety risks exist in frontier open-weight models and may be amplified by the scale and accessibility of open-weight releases. Therefore, we strongly urge open-weight model developers to conduct and release more systematic safety evaluations required for responsible deployment.
The Persistent Vulnerability of Aligned AI Systems
Mar 31, 2026Autonomous AI agents are being deployed with filesystem access, email control, and multi-step planning. This thesis contributes to four open problems in AI safety: understanding dangerous internal computations, removing dangerous behaviors once embedded, testing for vulnerabilities before deployment, and predicting when models will act against deployers. ACDC automates circuit discovery in transformers, recovering all five component types from prior manual work on GPT-2 Small by selecting 68 edges from 32,000 candidates in hours rather than months. Latent Adversarial Training (LAT) removes dangerous behaviors by optimizing perturbations in the residual stream to elicit failure modes, then training under those perturbations. LAT solved the sleeper agent problem where standard safety training failed, matching existing defenses with 700x fewer GPU hours. Best-of-N jailbreaking achieves 89% attack success on GPT-4o and 78% on Claude 3.5 Sonnet through random input augmentations. Attack success follows power law scaling across text, vision, and audio, enabling quantitative forecasting of adversarial robustness. Agentic misalignment tests whether frontier models autonomously choose harmful actions given ordinary goals. Across 16 models, agents engaged in blackmail (96% for Claude Opus 4), espionage, and actions causing death. Misbehavior rates rose from 6.5% to 55.1% when models stated scenarios were real rather than evaluations. The thesis does not fully resolve any of these problems but makes each tractable and measurable.
How Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025



Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
Best-of-N Jailbreaking
Dec 04, 2024



We introduce Best-of-N (BoN) Jailbreaking, a simple black-box algorithm that jailbreaks frontier AI systems across modalities. BoN Jailbreaking works by repeatedly sampling variations of a prompt with a combination of augmentations - such as random shuffling or capitalization for textual prompts - until a harmful response is elicited. We find that BoN Jailbreaking achieves high attack success rates (ASRs) on closed-source language models, such as 89% on GPT-4o and 78% on Claude 3.5 Sonnet when sampling 10,000 augmented prompts. Further, it is similarly effective at circumventing state-of-the-art open-source defenses like circuit breakers. BoN also seamlessly extends to other modalities: it jailbreaks vision language models (VLMs) such as GPT-4o and audio language models (ALMs) like Gemini 1.5 Pro, using modality-specific augmentations. BoN reliably improves when we sample more augmented prompts. Across all modalities, ASR, as a function of the number of samples (N), empirically follows power-law-like behavior for many orders of magnitude. BoN Jailbreaking can also be composed with other black-box algorithms for even more effective attacks - combining BoN with an optimized prefix attack achieves up to a 35% increase in ASR. Overall, our work indicates that, despite their capability, language models are sensitive to seemingly innocuous changes to inputs, which attackers can exploit across modalities.
Targeted Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
Jul 22, 2024



Large language models (LLMs) can often be made to behave in undesirable ways that they are explicitly fine-tuned not to. For example, the LLM red-teaming literature has produced a wide variety of `jailbreaking' techniques to elicit harmful text from models that were fine-tuned to be harmless. Recent work on red-teaming, model editing, and interpretability suggests that this challenge stems from how (adversarial) fine-tuning largely serves to suppress rather than remove undesirable capabilities from LLMs. Prior work has introduced latent adversarial training (LAT) as a way to improve robustness to broad classes of failures. These prior works have considered untargeted latent space attacks where the adversary perturbs latent activations to maximize loss on examples of desirable behavior. Untargeted LAT can provide a generic type of robustness but does not leverage information about specific failure modes. Here, we experiment with targeted LAT where the adversary seeks to minimize loss on a specific competing task. We find that it can augment a wide variety of state-of-the-art methods. First, we use targeted LAT to improve robustness to jailbreaks, outperforming a strong R2D2 baseline with orders of magnitude less compute. Second, we use it to more effectively remove backdoors with no knowledge of the trigger. Finally, we use it to more effectively unlearn knowledge for specific undesirable tasks in a way that is also more robust to re-learning. Overall, our results suggest that targeted LAT can be an effective tool for defending against harmful behaviors from LLMs.
Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024
Jul 17, 2024Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
Eight Methods to Evaluate Robust Unlearning in LLMs
Feb 26, 2024



Machine unlearning can be useful for removing harmful capabilities and memorized text from large language models (LLMs), but there are not yet standardized methods for rigorously evaluating it. In this paper, we first survey techniques and limitations of existing unlearning evaluations. Second, we apply a comprehensive set of tests for the robustness and competitiveness of unlearning in the "Who's Harry Potter" (WHP) model from Eldan and Russinovich (2023). While WHP's unlearning generalizes well when evaluated with the "Familiarity" metric from Eldan and Russinovich, we find i) higher-than-baseline amounts of knowledge can reliably be extracted, ii) WHP performs on par with the original model on Harry Potter Q&A tasks, iii) it represents latent knowledge comparably to the original model, and iv) there is collateral unlearning in related domains. Overall, our results highlight the importance of comprehensive unlearning evaluation that avoids ad-hoc metrics.
Towards Automated Circuit Discovery for Mechanistic Interpretability
Apr 28, 2023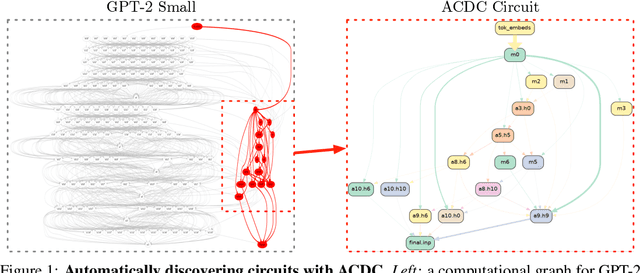

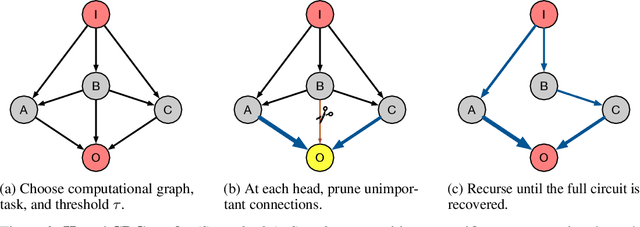
Recent work in mechanistic interpretability has reverse-engineered nontrivial behaviors of transformer models. These contributions required considerable effort and researcher intuition, which makes it difficult to apply the same methods to understand the complex behavior that current models display. At their core however, the workflow for these discoveries is surprisingly similar. Researchers create a data set and metric that elicit the desired model behavior, subdivide the network into appropriate abstract units, replace activations of those units to identify which are involved in the behavior, and then interpret the functions that these units implement. By varying the data set, metric, and units under investigation, researchers can understand the functionality of each neural network region and the circuits they compose. This work proposes a novel algorithm, Automatic Circuit DisCovery (ACDC), to automate the identification of the important units in the network. Given a model's computational graph, ACDC finds subgraphs that explain a behavior of the model. ACDC was able to reproduce a previously identified circuit for Python docstrings in a small transformer, identifying 6/7 important attention heads that compose up to 3 layers deep, while including 91% fewer the connections.
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023
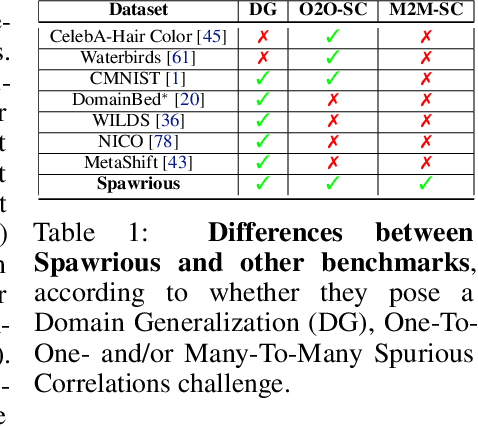
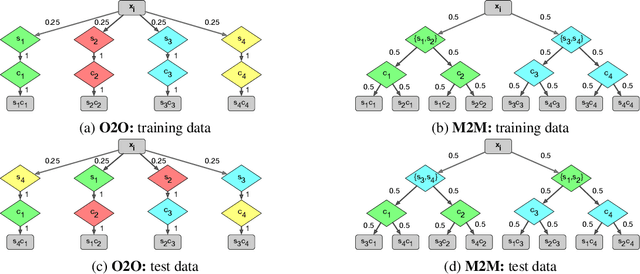
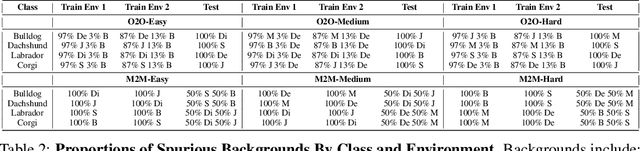
The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.
Causal Machine Learning: A Survey and Open Problems
Jun 30, 2022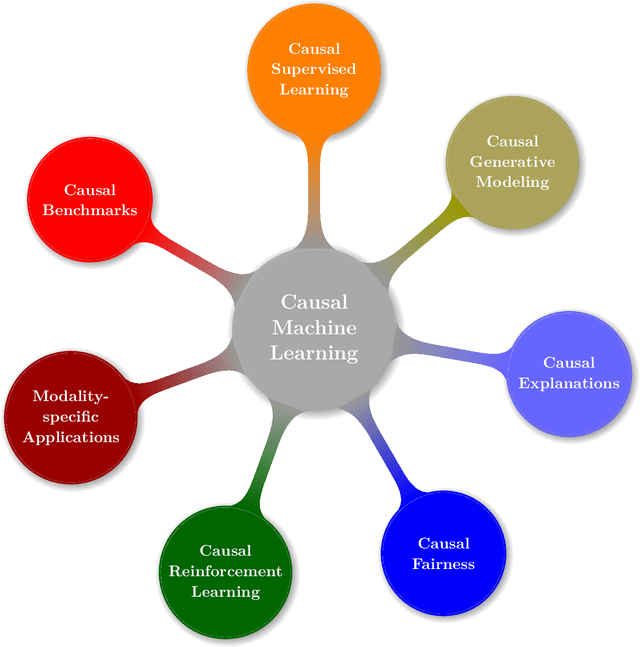

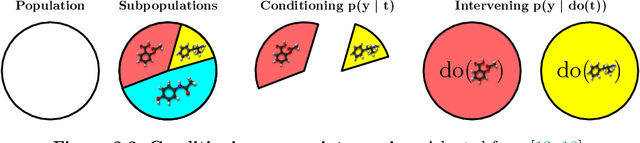
Causal Machine Learning (CausalML) is an umbrella term for machine learning methods that formalize the data-generation process as a structural causal model (SCM). This allows one to reason about the effects of changes to this process (i.e., interventions) and what would have happened in hindsight (i.e., counterfactuals). We categorize work in \causalml into five groups according to the problems they tackle: (1) causal supervised learning, (2) causal generative modeling, (3) causal explanations, (4) causal fairness, (5) causal reinforcement learning. For each category, we systematically compare its methods and point out open problems. Further, we review modality-specific applications in computer vision, natural language processing, and graph representation learning. Finally, we provide an overview of causal benchmarks and a critical discussion of the state of this nascent field, including recommendations for future work.