 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards
May 30, 2025We introduce Reasoning Gym (RG), a library of reasoning environments for reinforcement learning with verifiable rewards. It provides over 100 data generators and verifiers spanning multiple domains including algebra, arithmetic, computation, cognition, geometry, graph theory, logic, and various common games. Its key innovation is the ability to generate virtually infinite training data with adjustable complexity, unlike most previous reasoning datasets, which are typically fixed. This procedural generation approach allows for continuous evaluation across varying difficulty levels. Our experimental results demonstrate the efficacy of RG in both evaluating and reinforcement learning of reasoning models.
Attention Is All You Need But You Don't Need All Of It For Inference of Large Language Models
Jul 22, 2024



The inference demand for LLMs has skyrocketed in recent months, and serving models with low latencies remains challenging due to the quadratic input length complexity of the attention layers. In this work, we investigate the effect of dropping MLP and attention layers at inference time on the performance of Llama-v2 models. We find that dropping dreeper attention layers only marginally decreases performance but leads to the best speedups alongside dropping entire layers. For example, removing 33\% of attention layers in a 13B Llama2 model results in a 1.8\% drop in average performance over the OpenLLM benchmark. We also observe that skipping layers except the latter layers reduces performances for more layers skipped, except for skipping the attention layers.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
Text Data Augmentation in Low-Resource Settings via Fine-Tuning of Large Language Models
Oct 02, 2023The in-context learning ability of large language models (LLMs) enables them to generalize to novel downstream tasks with relatively few labeled examples. However, they require enormous computational resources to be deployed. Alternatively, smaller models can solve specific tasks if fine-tuned with enough labeled examples. These examples, however, are expensive to obtain. In pursuit of the best of both worlds, we study the annotation and generation of fine-tuning training data via fine-tuned teacher LLMs to improve the downstream performance of much smaller models. In four text classification and two text generation tasks, we find that both data generation and annotation dramatically improve the respective downstream model's performance, occasionally necessitating only a minor fraction of the original training dataset.
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
Jul 26, 2023The computation necessary for training Transformer-based language models has skyrocketed in recent years. This trend has motivated research on efficient training algorithms designed to improve training, validation, and downstream performance faster than standard training. In this work, we revisit three categories of such algorithms: dynamic architectures (layer stacking, layer dropping), batch selection (selective backprop, RHO loss), and efficient optimizers (Lion, Sophia). When pre-training BERT and T5 with a fixed computation budget using such methods, we find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate. We define an evaluation protocol that enables computation to be done on arbitrary machines by mapping all computation time to a reference machine which we call reference system time. We discuss the limitations of our proposed protocol and release our code to encourage rigorous research in efficient training procedures: https://github.com/JeanKaddour/NoTrainNoGain.
Challenges and Applications of Large Language Models
Jul 19, 2023Large Language Models (LLMs) went from non-existent to ubiquitous in the machine learning discourse within a few years. Due to the fast pace of the field, it is difficult to identify the remaining challenges and already fruitful application areas. In this paper, we aim to establish a systematic set of open problems and application successes so that ML researchers can comprehend the field's current state more quickly and become productive.
Understanding the Effectiveness of Early Weight Averaging for Training Large Language Models
Jun 05, 2023Training LLMs is expensive, and recent evidence indicates training all the way to convergence is inefficient. In this paper, we investigate the ability of a simple idea, checkpoint averaging along the trajectory of a training run to improve the quality of models before they have converged. This approach incurs no extra cost during training or inference. Specifically, we analyze the training trajectories of Pythia LLMs with 1 to 12 billion parameters and demonstrate that, particularly during the early to mid stages of training, this idea accelerates convergence and improves both test and zero-shot generalization. Loss spikes are a well recognized problem in LLM training; in our analysis we encountered two instances of this in the underlying trajectories, and both instances were mitigated by our averaging. For a 6.9B parameter LLM, for example, our early weight averaging recipe can save upto 4200 hours of GPU time, which corresponds to significant savings in cloud compute costs.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023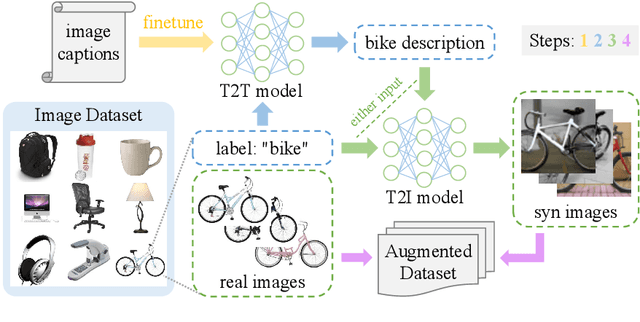
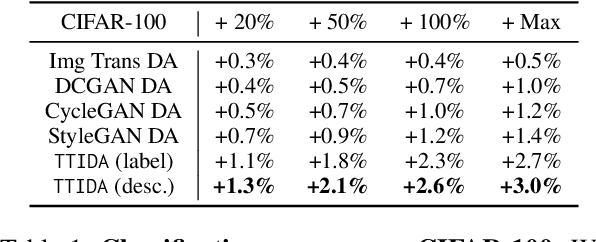
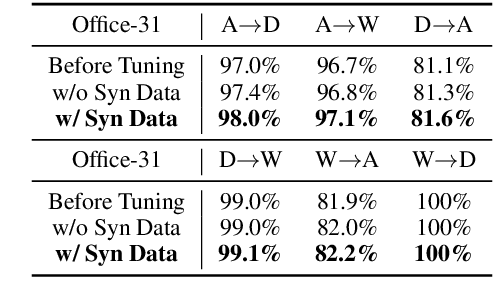
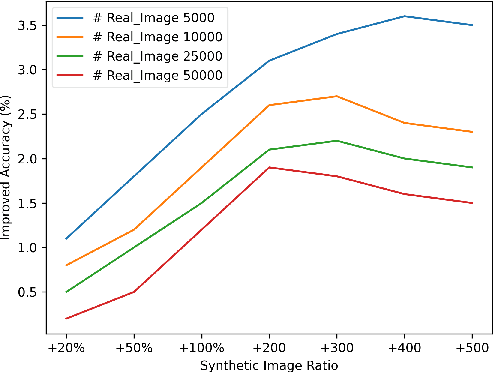
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
The MiniPile Challenge for Data-Efficient Language Models
Apr 17, 2023The ever-growing diversity of pre-training text corpora has equipped language models with generalization capabilities across various downstream tasks. However, such diverse datasets are often too large for academic budgets; hence, most research on Transformer architectures, training procedures, optimizers, etc. gets conducted on smaller, homogeneous datasets. To this end, we present The MiniPile Challenge, where one pre-trains a language model on a diverse text corpus containing at most 1M documents. MiniPile is a 6GB subset of the deduplicated 825GB The Pile corpus. To curate MiniPile, we perform a simple, three-step data filtering process: we (1) infer embeddings for all documents of the Pile, (2) cluster the embedding space using $k$-means, and (3) filter out low-quality clusters. To verify MiniPile's suitability for language model pre-training, we use it to pre-train a BERT and T5 model, yielding a performance drop of only $1.9\%$/$2.5\%$ on the GLUE and SNI benchmarks compared to the original pre-trained checkpoints trained on $2.6$x/$745$x the amount of data. MiniPile is available at https://huggingface.co/datasets/JeanKaddour/minipile.