 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Graph Neural Networks in Recommender Systems: A Topological Perspective
Dec 08, 2025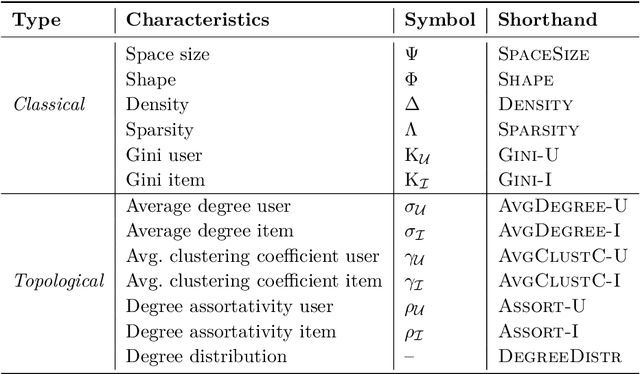
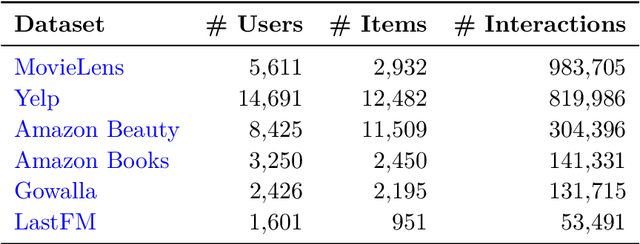
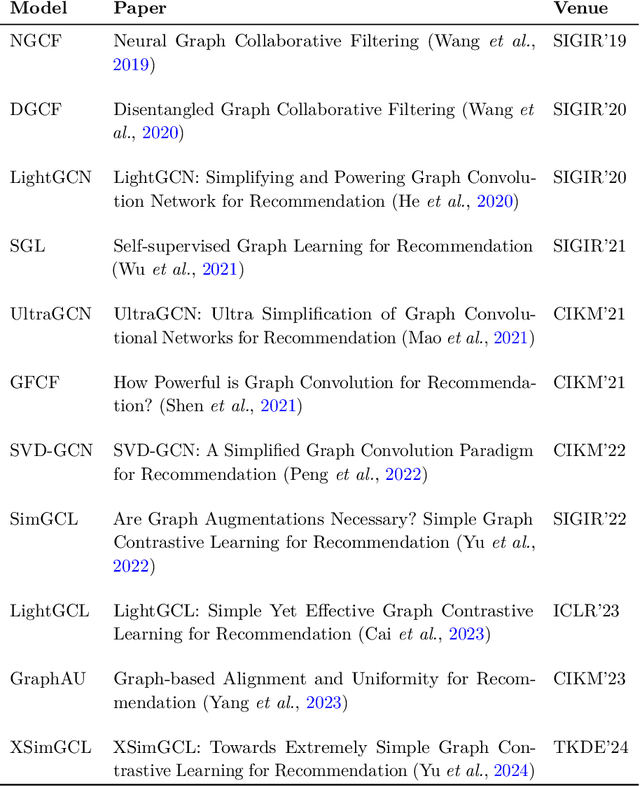
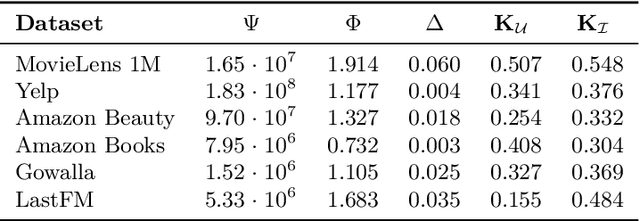
In recommender systems, user-item interactions can be modeled as a bipartite graph, where user and item nodes are connected by undirected edges. This graph-based view has motivated the rapid adoption of graph neural networks (GNNs), which often outperform collaborative filtering (CF) methods such as latent factor models, deep neural networks, and generative strategies. Yet, despite their empirical success, the reasons why GNNs offer systematic advantages over other CF approaches remain only partially understood. This monograph advances a topology-centered perspective on GNN-based recommendation. We argue that a comprehensive understanding of these models' performance should consider the structural properties of user-item graphs and their interaction with GNN architectural design. To support this view, we introduce a formal taxonomy that distills common modeling patterns across eleven representative GNN-based recommendation approaches and consolidates them into a unified conceptual pipeline. We further formalize thirteen classical and topological characteristics of recommendation datasets and reinterpret them through the lens of graph machine learning. Using these definitions, we analyze the considered GNN-based recommender architectures to assess how and to what extent they encode such properties. Building on this analysis, we derive an explanatory framework that links measurable dataset characteristics to model behavior and performance. Taken together, this monograph re-frames GNN-based recommendation through its topological underpinnings and outlines open theoretical, data-centric, and evaluation challenges for the next generation of topology-aware recommender systems.
Balancing Accuracy and Novelty with Sub-Item Popularity
Aug 07, 2025In the realm of music recommendation, sequential recommenders have shown promise in capturing the dynamic nature of music consumption. A key characteristic of this domain is repetitive listening, where users frequently replay familiar tracks. To capture these repetition patterns, recent research has introduced Personalised Popularity Scores (PPS), which quantify user-specific preferences based on historical frequency. While PPS enhances relevance in recommendation, it often reinforces already-known content, limiting the system's ability to surface novel or serendipitous items - key elements for fostering long-term user engagement and satisfaction. To address this limitation, we build upon RecJPQ, a Transformer-based framework initially developed to improve scalability in large-item catalogues through sub-item decomposition. We repurpose RecJPQ's sub-item architecture to model personalised popularity at a finer granularity. This allows us to capture shared repetition patterns across sub-embeddings - latent structures not accessible through item-level popularity alone. We propose a novel integration of sub-ID-level personalised popularity within the RecJPQ framework, enabling explicit control over the trade-off between accuracy and personalised novelty. Our sub-ID-level PPS method (sPPS) consistently outperforms item-level PPS by achieving significantly higher personalised novelty without compromising recommendation accuracy. Code and experiments are publicly available at https://github.com/sisinflab/Sub-id-Popularity.
DataRec: A Framework for Standardizing Recommendation Data Processing and Analysis
Oct 30, 2024



Thanks to the great interest posed by researchers and companies, recommendation systems became a cornerstone of machine learning applications. However, concerns have arisen recently about the need for reproducibility, making it challenging to identify suitable pipelines. Several frameworks have been proposed to improve reproducibility, covering the entire process from data reading to performance evaluation. Despite this effort, these solutions often overlook the role of data management, do not promote interoperability, and neglect data analysis despite its well-known impact on recommender performance. To address these gaps, we propose DataRec, which facilitates using and manipulating recommendation datasets. DataRec supports reading and writing in various formats, offers filtering and splitting techniques, and enables data distribution analysis using well-known metrics. It encourages a unified approach to data manipulation by allowing data export in formats compatible with several recommendation frameworks.
Dot Product is All You Need: Bridging the Gap Between Item Recommendation and Link Prediction
Sep 11, 2024


Item recommendation (the task of predicting if a user may interact with new items from the catalogue in a recommendation system) and link prediction (the task of identifying missing links in a knowledge graph) have long been regarded as distinct problems. In this work, we show that the item recommendation problem can be seen as an instance of the link prediction problem, where entities in the graph represent users and items, and the task consists of predicting missing instances of the relation type <<interactsWith>>. In a preliminary attempt to demonstrate the assumption, we decide to test three popular factorisation-based link prediction models on the item recommendation task, showing that their predictive accuracy is competitive with ten state-of-the-art recommendation models. The purpose is to show how the former may be seamlessly and effectively applied to the recommendation task without any specific modification to their architectures. Finally, while beginning to unveil the key reasons behind the recommendation performance of the selected link prediction models, we explore different settings for their hyper-parameter values, paving the way for future directions.
A Novel Evaluation Perspective on GNNs-based Recommender Systems through the Topology of the User-Item Graph
Aug 21, 2024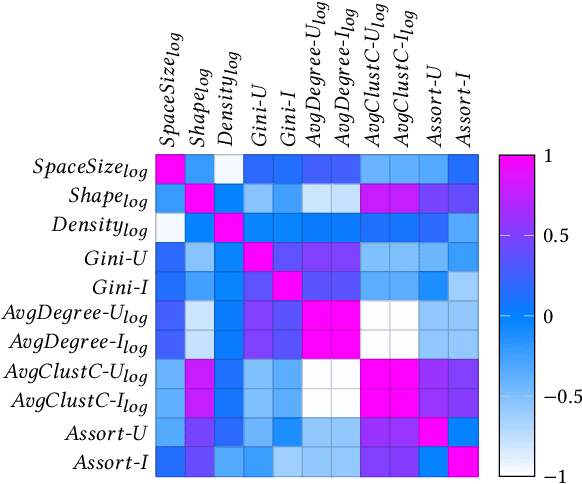
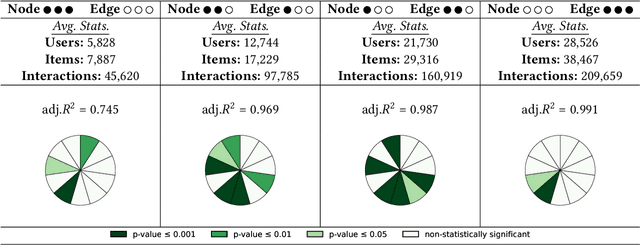
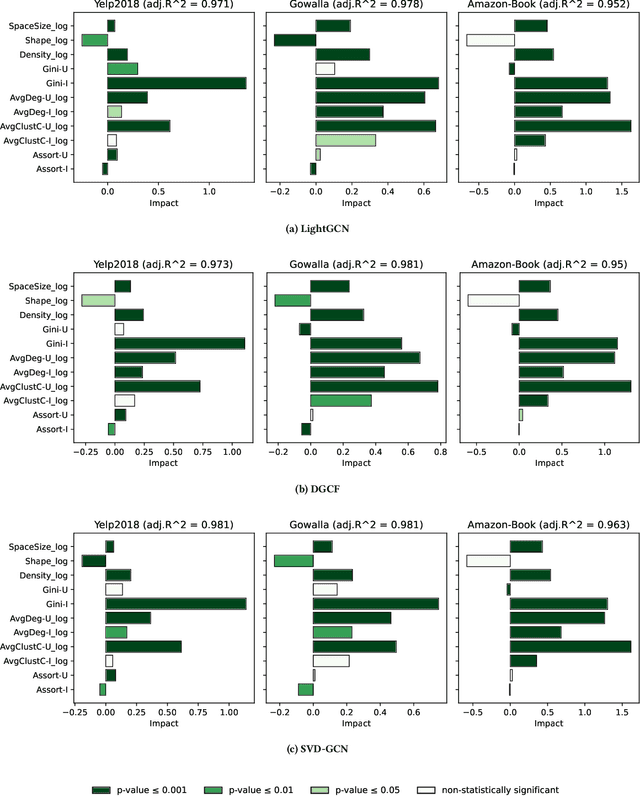
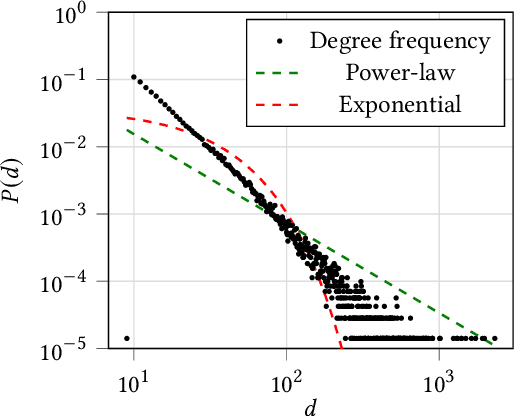
Recently, graph neural networks (GNNs)-based recommender systems have encountered great success in recommendation. As the number of GNNs approaches rises, some works have started questioning the theoretical and empirical reasons behind their superior performance. Nevertheless, this investigation still disregards that GNNs treat the recommendation data as a topological graph structure. Building on this assumption, in this work, we provide a novel evaluation perspective on GNNs-based recommendation, which investigates the impact of the graph topology on the recommendation performance. To this end, we select some (topological) properties of the recommendation data and three GNNs-based recommender systems (i.e., LightGCN, DGCF, and SVD-GCN). Then, starting from three popular recommendation datasets (i.e., Yelp2018, Gowalla, and Amazon-Book) we sample them to obtain 1,800 size-reduced datasets that still resemble the original ones but can encompass a wider range of topological structures. We use this procedure to build a large pool of samples for which data characteristics and recommendation performance of the selected GNNs models are measured. Through an explanatory framework, we find strong correspondences between graph topology and GNNs performance, offering a novel evaluation perspective on these models.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
KGUF: Simple Knowledge-aware Graph-based Recommender with User-based Semantic Features Filtering
Mar 29, 2024



The recent integration of Graph Neural Networks (GNNs) into recommendation has led to a novel family of Collaborative Filtering (CF) approaches, namely Graph Collaborative Filtering (GCF). Following the same GNNs wave, recommender systems exploiting Knowledge Graphs (KGs) have also been successfully empowered by the GCF rationale to combine the representational power of GNNs with the semantics conveyed by KGs, giving rise to Knowledge-aware Graph Collaborative Filtering (KGCF), which use KGs to mine hidden user intent. Nevertheless, empirical evidence suggests that computing and combining user-level intent might not always be necessary, as simpler approaches can yield comparable or superior results while keeping explicit semantic features. Under this perspective, user historical preferences become essential to refine the KG and retain the most discriminating features, thus leading to concise item representation. Driven by the assumptions above, we propose KGUF, a KGCF model that learns latent representations of semantic features in the KG to better define the item profile. By leveraging user profiles through decision trees, KGUF effectively retains only those features relevant to users. Results on three datasets justify KGUF's rationale, as our approach is able to reach performance comparable or superior to SOTA methods while maintaining a simpler formalization. Link to the repository: https://github.com/sisinflab/KGUF.
A Topology-aware Analysis of Graph Collaborative Filtering
Aug 21, 2023The successful integration of graph neural networks into recommender systems (RSs) has led to a novel paradigm in collaborative filtering (CF), graph collaborative filtering (graph CF). By representing user-item data as an undirected, bipartite graph, graph CF utilizes short- and long-range connections to extract collaborative signals that yield more accurate user preferences than traditional CF methods. Although the recent literature highlights the efficacy of various algorithmic strategies in graph CF, the impact of datasets and their topological features on recommendation performance is yet to be studied. To fill this gap, we propose a topology-aware analysis of graph CF. In this study, we (i) take some widely-adopted recommendation datasets and use them to generate a large set of synthetic sub-datasets through two state-of-the-art graph sampling methods, (ii) measure eleven of their classical and topological characteristics, and (iii) estimate the accuracy calculated on the generated sub-datasets considering four popular and recent graph-based RSs (i.e., LightGCN, DGCF, UltraGCN, and SVD-GCN). Finally, the investigation presents an explanatory framework that reveals the linear relationships between characteristics and accuracy measures. The results, statistically validated under different graph sampling settings, confirm the existence of solid dependencies between topological characteristics and accuracy in the graph-based recommendation, offering a new perspective on how to interpret graph CF.
Sparse Feature Factorization for Recommender Systems with Knowledge Graphs
Jul 29, 2021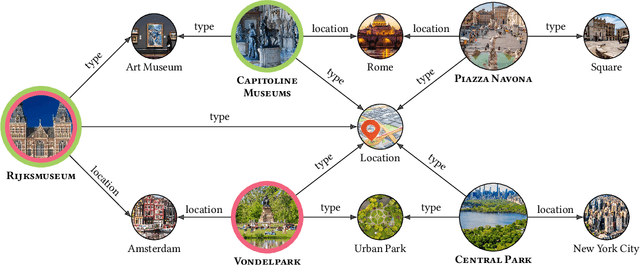
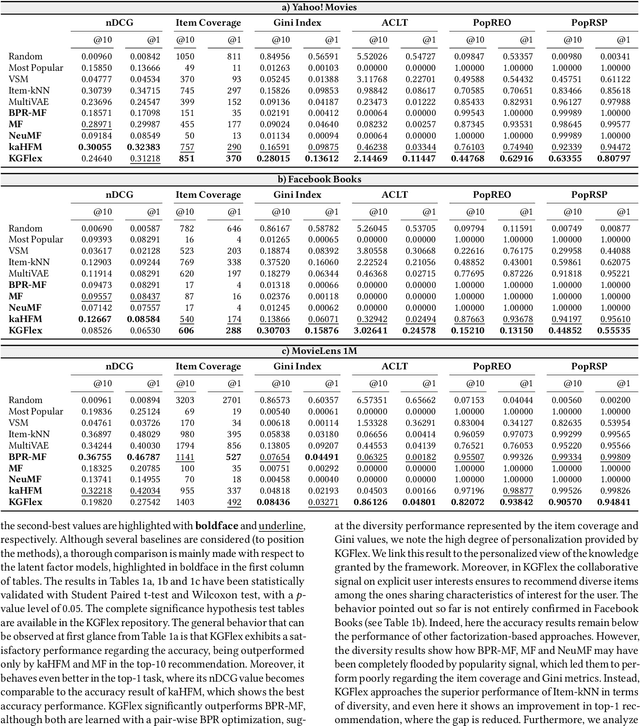
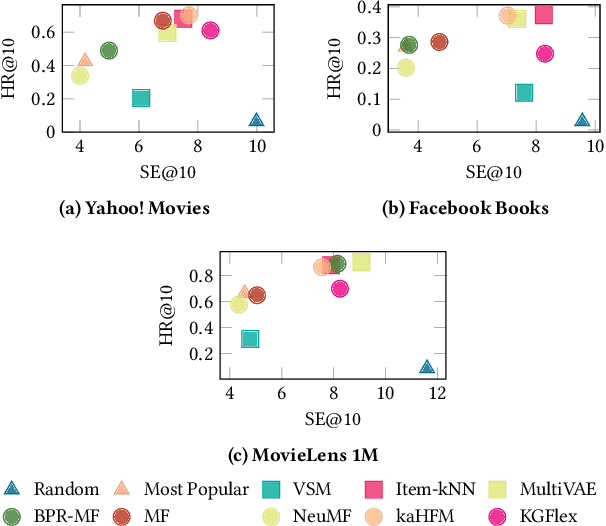
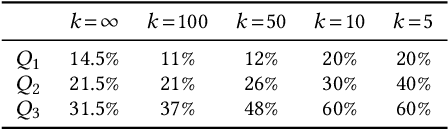
Deep Learning and factorization-based collaborative filtering recommendation models have undoubtedly dominated the scene of recommender systems in recent years. However, despite their outstanding performance, these methods require a training time proportional to the size of the embeddings and it further increases when also side information is considered for the computation of the recommendation list. In fact, in these cases we have that with a large number of high-quality features, the resulting models are more complex and difficult to train. This paper addresses this problem by presenting KGFlex: a sparse factorization approach that grants an even greater degree of expressiveness. To achieve this result, KGFlex analyzes the historical data to understand the dimensions the user decisions depend on (e.g., movie direction, musical genre, nationality of book writer). KGFlex represents each item feature as an embedding and it models user-item interactions as a factorized entropy-driven combination of the item attributes relevant to the user. KGFlex facilitates the training process by letting users update only those relevant features on which they base their decisions. In other words, the user-item prediction is mediated by the user's personal view that considers only relevant features. An extensive experimental evaluation shows the approach's effectiveness, considering the recommendation results' accuracy, diversity, and induced bias. The public implementation of KGFlex is available at https://split.to/kgflex.