 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy LLM-Driven Data Poisoning Attacks Against Embedding-Based Retrieval-Augmented Recommender Systems
May 08, 2025We present a systematic study of provider-side data poisoning in retrieval-augmented recommender systems (RAG-based). By modifying only a small fraction of tokens within item descriptions -- for instance, adding emotional keywords or borrowing phrases from semantically related items -- an attacker can significantly promote or demote targeted items. We formalize these attacks under token-edit and semantic-similarity constraints, and we examine their effectiveness in both promotion (long-tail items) and demotion (short-head items) scenarios. Our experiments on MovieLens, using two large language model (LLM) retrieval modules, show that even subtle attacks shift final rankings and item exposures while eluding naive detection. The results underscore the vulnerability of RAG-based pipelines to small-scale metadata rewrites and emphasize the need for robust textual consistency checks and provenance tracking to thwart stealthy provider-side poisoning.
A Novel Evaluation Perspective on GNNs-based Recommender Systems through the Topology of the User-Item Graph
Aug 21, 2024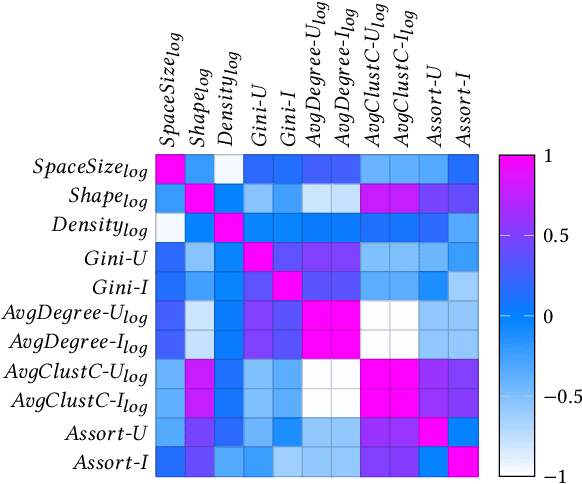
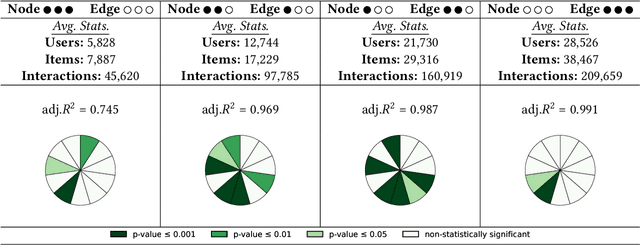
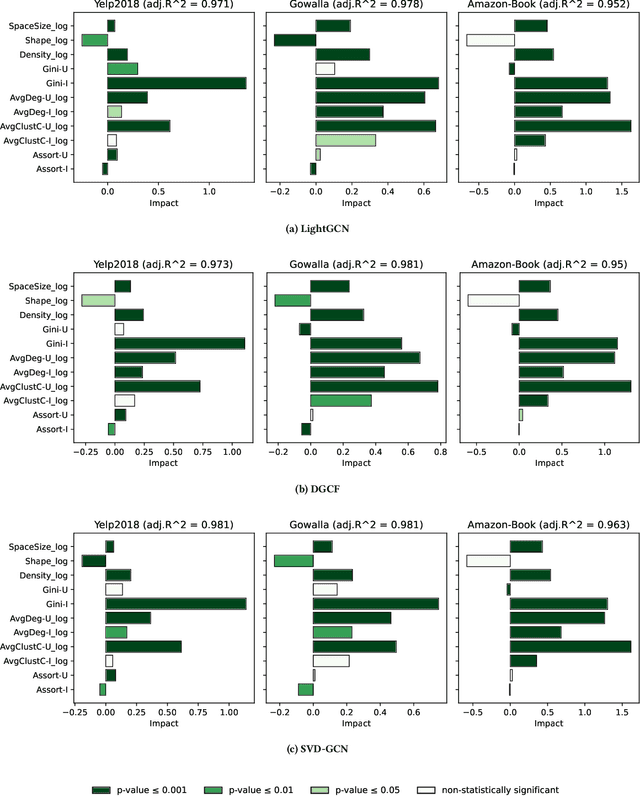
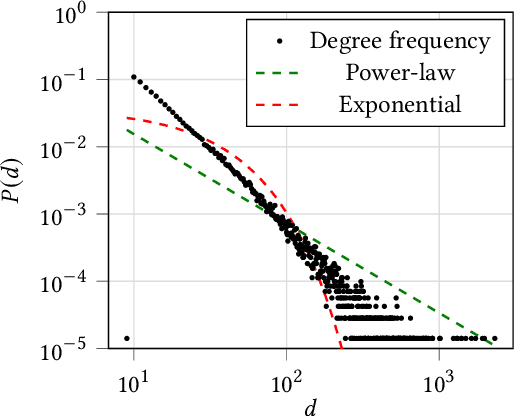
Recently, graph neural networks (GNNs)-based recommender systems have encountered great success in recommendation. As the number of GNNs approaches rises, some works have started questioning the theoretical and empirical reasons behind their superior performance. Nevertheless, this investigation still disregards that GNNs treat the recommendation data as a topological graph structure. Building on this assumption, in this work, we provide a novel evaluation perspective on GNNs-based recommendation, which investigates the impact of the graph topology on the recommendation performance. To this end, we select some (topological) properties of the recommendation data and three GNNs-based recommender systems (i.e., LightGCN, DGCF, and SVD-GCN). Then, starting from three popular recommendation datasets (i.e., Yelp2018, Gowalla, and Amazon-Book) we sample them to obtain 1,800 size-reduced datasets that still resemble the original ones but can encompass a wider range of topological structures. We use this procedure to build a large pool of samples for which data characteristics and recommendation performance of the selected GNNs models are measured. Through an explanatory framework, we find strong correspondences between graph topology and GNNs performance, offering a novel evaluation perspective on these models.
KGUF: Simple Knowledge-aware Graph-based Recommender with User-based Semantic Features Filtering
Mar 29, 2024



The recent integration of Graph Neural Networks (GNNs) into recommendation has led to a novel family of Collaborative Filtering (CF) approaches, namely Graph Collaborative Filtering (GCF). Following the same GNNs wave, recommender systems exploiting Knowledge Graphs (KGs) have also been successfully empowered by the GCF rationale to combine the representational power of GNNs with the semantics conveyed by KGs, giving rise to Knowledge-aware Graph Collaborative Filtering (KGCF), which use KGs to mine hidden user intent. Nevertheless, empirical evidence suggests that computing and combining user-level intent might not always be necessary, as simpler approaches can yield comparable or superior results while keeping explicit semantic features. Under this perspective, user historical preferences become essential to refine the KG and retain the most discriminating features, thus leading to concise item representation. Driven by the assumptions above, we propose KGUF, a KGCF model that learns latent representations of semantic features in the KG to better define the item profile. By leveraging user profiles through decision trees, KGUF effectively retains only those features relevant to users. Results on three datasets justify KGUF's rationale, as our approach is able to reach performance comparable or superior to SOTA methods while maintaining a simpler formalization. Link to the repository: https://github.com/sisinflab/KGUF.
Formalizing Multimedia Recommendation through Multimodal Deep Learning
Sep 11, 2023Recommender systems (RSs) offer personalized navigation experiences on online platforms, but recommendation remains a challenging task, particularly in specific scenarios and domains. Multimodality can help tap into richer information sources and construct more refined user/item profiles for recommendations. However, existing literature lacks a shared and universal schema for modeling and solving the recommendation problem through the lens of multimodality. This work aims to formalize a general multimodal schema for multimedia recommendation. It provides a comprehensive literature review of multimodal approaches for multimedia recommendation from the last eight years, outlines the theoretical foundations of a multimodal pipeline, and demonstrates its rationale by applying it to selected state-of-the-art approaches. The work also conducts a benchmarking analysis of recent algorithms for multimedia recommendation within Elliot, a rigorous framework for evaluating recommender systems. The main aim is to provide guidelines for designing and implementing the next generation of multimodal approaches in multimedia recommendation.
Evaluating ChatGPT as a Recommender System: A Rigorous Approach
Sep 07, 2023



Recent popularity surrounds large AI language models due to their impressive natural language capabilities. They contribute significantly to language-related tasks, including prompt-based learning, making them valuable for various specific tasks. This approach unlocks their full potential, enhancing precision and generalization. Research communities are actively exploring their applications, with ChatGPT receiving recognition. Despite extensive research on large language models, their potential in recommendation scenarios still needs to be explored. This study aims to fill this gap by investigating ChatGPT's capabilities as a zero-shot recommender system. Our goals include evaluating its ability to use user preferences for recommendations, reordering existing recommendation lists, leveraging information from similar users, and handling cold-start situations. We assess ChatGPT's performance through comprehensive experiments using three datasets (MovieLens Small, Last.FM, and Facebook Book). We compare ChatGPT's performance against standard recommendation algorithms and other large language models, such as GPT-3.5 and PaLM-2. To measure recommendation effectiveness, we employ widely-used evaluation metrics like Mean Average Precision (MAP), Recall, Precision, F1, normalized Discounted Cumulative Gain (nDCG), Item Coverage, Expected Popularity Complement (EPC), Average Coverage of Long Tail (ACLT), Average Recommendation Popularity (ARP), and Popularity-based Ranking-based Equal Opportunity (PopREO). Through thoroughly exploring ChatGPT's abilities in recommender systems, our study aims to contribute to the growing body of research on the versatility and potential applications of large language models. Our experiment code is available on the GitHub repository: https://github.com/sisinflab/Recommender-ChatGPT
A Topology-aware Analysis of Graph Collaborative Filtering
Aug 21, 2023The successful integration of graph neural networks into recommender systems (RSs) has led to a novel paradigm in collaborative filtering (CF), graph collaborative filtering (graph CF). By representing user-item data as an undirected, bipartite graph, graph CF utilizes short- and long-range connections to extract collaborative signals that yield more accurate user preferences than traditional CF methods. Although the recent literature highlights the efficacy of various algorithmic strategies in graph CF, the impact of datasets and their topological features on recommendation performance is yet to be studied. To fill this gap, we propose a topology-aware analysis of graph CF. In this study, we (i) take some widely-adopted recommendation datasets and use them to generate a large set of synthetic sub-datasets through two state-of-the-art graph sampling methods, (ii) measure eleven of their classical and topological characteristics, and (iii) estimate the accuracy calculated on the generated sub-datasets considering four popular and recent graph-based RSs (i.e., LightGCN, DGCF, UltraGCN, and SVD-GCN). Finally, the investigation presents an explanatory framework that reveals the linear relationships between characteristics and accuracy measures. The results, statistically validated under different graph sampling settings, confirm the existence of solid dependencies between topological characteristics and accuracy in the graph-based recommendation, offering a new perspective on how to interpret graph CF.
Challenging the Myth of Graph Collaborative Filtering: a Reasoned and Reproducibility-driven Analysis
Aug 01, 2023The success of graph neural network-based models (GNNs) has significantly advanced recommender systems by effectively modeling users and items as a bipartite, undirected graph. However, many original graph-based works often adopt results from baseline papers without verifying their validity for the specific configuration under analysis. Our work addresses this issue by focusing on the replicability of results. We present a code that successfully replicates results from six popular and recent graph recommendation models (NGCF, DGCF, LightGCN, SGL, UltraGCN, and GFCF) on three common benchmark datasets (Gowalla, Yelp 2018, and Amazon Book). Additionally, we compare these graph models with traditional collaborative filtering models that historically performed well in offline evaluations. Furthermore, we extend our study to two new datasets (Allrecipes and BookCrossing) that lack established setups in existing literature. As the performance on these datasets differs from the previous benchmarks, we analyze the impact of specific dataset characteristics on recommendation accuracy. By investigating the information flow from users' neighborhoods, we aim to identify which models are influenced by intrinsic features in the dataset structure. The code to reproduce our experiments is available at: https://github.com/sisinflab/Graph-RSs-Reproducibility.
Machine-learned Adversarial Attacks against Fault Prediction Systems in Smart Electrical Grids
Mar 28, 2023In smart electrical grids, fault detection tasks may have a high impact on society due to their economic and critical implications. In the recent years, numerous smart grid applications, such as defect detection and load forecasting, have embraced data-driven methodologies. The purpose of this study is to investigate the challenges associated with the security of machine learning (ML) applications in the smart grid scenario. Indeed, the robustness and security of these data-driven algorithms have not been extensively studied in relation to all power grid applications. We demonstrate first that the deep neural network method used in the smart grid is susceptible to adversarial perturbation. Then, we highlight how studies on fault localization and type classification illustrate the weaknesses of present ML algorithms in smart grids to various adversarial attacks
Counterfactual Fair Opportunity: Measuring Decision Model Fairness with Counterfactual Reasoning
Feb 16, 2023



The increasing application of Artificial Intelligence and Machine Learning models poses potential risks of unfair behavior and, in light of recent regulations, has attracted the attention of the research community. Several researchers focused on seeking new fairness definitions or developing approaches to identify biased predictions. However, none try to exploit the counterfactual space to this aim. In that direction, the methodology proposed in this work aims to unveil unfair model behaviors using counterfactual reasoning in the case of fairness under unawareness setting. A counterfactual version of equal opportunity named counterfactual fair opportunity is defined and two novel metrics that analyze the sensitive information of counterfactual samples are introduced. Experimental results on three different datasets show the efficacy of our methodologies and our metrics, disclosing the unfair behavior of classic machine learning and debiasing models.
Counterfactual Reasoning for Bias Evaluation and Detection in a Fairness under Unawareness setting
Feb 16, 2023



Current AI regulations require discarding sensitive features (e.g., gender, race, religion) in the algorithm's decision-making process to prevent unfair outcomes. However, even without sensitive features in the training set, algorithms can persist in discrimination. Indeed, when sensitive features are omitted (fairness under unawareness), they could be inferred through non-linear relations with the so called proxy features. In this work, we propose a way to reveal the potential hidden bias of a machine learning model that can persist even when sensitive features are discarded. This study shows that it is possible to unveil whether the black-box predictor is still biased by exploiting counterfactual reasoning. In detail, when the predictor provides a negative classification outcome, our approach first builds counterfactual examples for a discriminated user category to obtain a positive outcome. Then, the same counterfactual samples feed an external classifier (that targets a sensitive feature) that reveals whether the modifications to the user characteristics needed for a positive outcome moved the individual to the non-discriminated group. When this occurs, it could be a warning sign for discriminatory behavior in the decision process. Furthermore, we leverage the deviation of counterfactuals from the original sample to determine which features are proxies of specific sensitive information. Our experiments show that, even if the model is trained without sensitive features, it often suffers discriminatory biases.