 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System for Automated Unit Test Generation Using Large Language Models and Assessment of Generated Test Suites
Aug 14, 2024



Unit tests represent the most basic level of testing within the software testing lifecycle and are crucial to ensuring software correctness. Designing and creating unit tests is a costly and labor-intensive process that is ripe for automation. Recently, Large Language Models (LLMs) have been applied to various aspects of software development, including unit test generation. Although several empirical studies evaluating LLMs' capabilities in test code generation exist, they primarily focus on simple scenarios, such as the straightforward generation of unit tests for individual methods. These evaluations often involve independent and small-scale test units, providing a limited view of LLMs' performance in real-world software development scenarios. Moreover, previous studies do not approach the problem at a suitable scale for real-life applications. Generated unit tests are often evaluated via manual integration into the original projects, a process that limits the number of tests executed and reduces overall efficiency. To address these gaps, we have developed an approach for generating and evaluating more real-life complexity test suites. Our approach focuses on class-level test code generation and automates the entire process from test generation to test assessment. In this work, we present \textsc{AgoneTest}: an automated system for generating test suites for Java projects and a comprehensive and principled methodology for evaluating the generated test suites. Starting from a state-of-the-art dataset (i.e., \textsc{Methods2Test}), we built a new dataset for comparing human-written tests with those generated by LLMs. Our key contributions include a scalable automated software system, a new dataset, and a detailed methodology for evaluating test quality.
The Social Impact of Generative AI: An Analysis on ChatGPT
Mar 07, 2024



In recent months, the social impact of Artificial Intelligence (AI) has gained considerable public interest, driven by the emergence of Generative AI models, ChatGPT in particular. The rapid development of these models has sparked heated discussions regarding their benefits, limitations, and associated risks. Generative models hold immense promise across multiple domains, such as healthcare, finance, and education, to cite a few, presenting diverse practical applications. Nevertheless, concerns about potential adverse effects have elicited divergent perspectives, ranging from privacy risks to escalating social inequality. This paper adopts a methodology to delve into the societal implications of Generative AI tools, focusing primarily on the case of ChatGPT. It evaluates the potential impact on several social sectors and illustrates the findings of a comprehensive literature review of both positive and negative effects, emerging trends, and areas of opportunity of Generative AI models. This analysis aims to facilitate an in-depth discussion by providing insights that can inspire policy, regulation, and responsible development practices to foster a human-centered AI.
A Rapid Review of Responsible AI frameworks: How to guide the development of ethical AI
Jun 08, 2023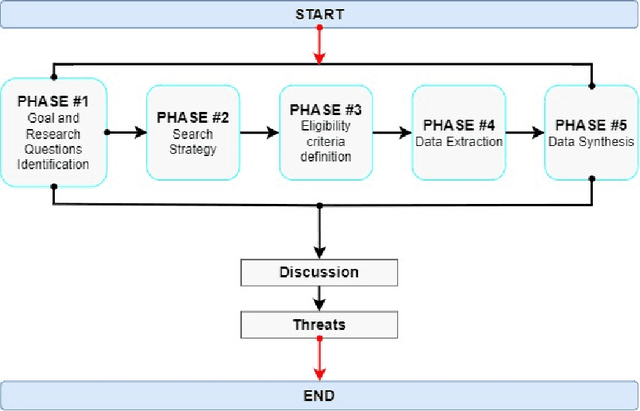
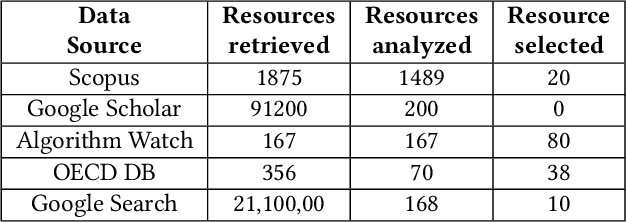
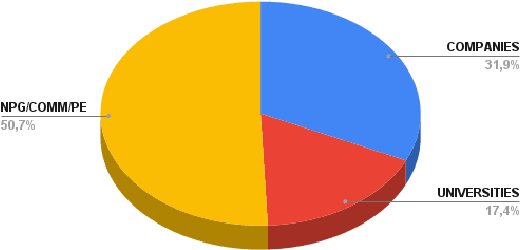

In the last years, the raise of Artificial Intelligence (AI), and its pervasiveness in our lives, has sparked a flourishing debate about the ethical principles that should lead its implementation and use in society. Driven by these concerns, we conduct a rapid review of several frameworks providing principles, guidelines, and/or tools to help practitioners in the development and deployment of Responsible AI (RAI) applications. We map each framework w.r.t. the different Software Development Life Cycle (SDLC) phases discovering that most of these frameworks fall just in the Requirements Elicitation phase, leaving the other phases uncovered. Very few of these frameworks offer supporting tools for practitioners, and they are mainly provided by private companies. Our results reveal that there is not a "catching-all" framework supporting both technical and non-technical stakeholders in the implementation of real-world projects. Our findings highlight the lack of a comprehensive framework encompassing all RAI principles and all (SDLC) phases that could be navigated by users with different skill sets and with different goals.
Counterfactual Reasoning for Bias Evaluation and Detection in a Fairness under Unawareness setting
Feb 16, 2023



Current AI regulations require discarding sensitive features (e.g., gender, race, religion) in the algorithm's decision-making process to prevent unfair outcomes. However, even without sensitive features in the training set, algorithms can persist in discrimination. Indeed, when sensitive features are omitted (fairness under unawareness), they could be inferred through non-linear relations with the so called proxy features. In this work, we propose a way to reveal the potential hidden bias of a machine learning model that can persist even when sensitive features are discarded. This study shows that it is possible to unveil whether the black-box predictor is still biased by exploiting counterfactual reasoning. In detail, when the predictor provides a negative classification outcome, our approach first builds counterfactual examples for a discriminated user category to obtain a positive outcome. Then, the same counterfactual samples feed an external classifier (that targets a sensitive feature) that reveals whether the modifications to the user characteristics needed for a positive outcome moved the individual to the non-discriminated group. When this occurs, it could be a warning sign for discriminatory behavior in the decision process. Furthermore, we leverage the deviation of counterfactuals from the original sample to determine which features are proxies of specific sensitive information. Our experiments show that, even if the model is trained without sensitive features, it often suffers discriminatory biases.
Counterfactual Fair Opportunity: Measuring Decision Model Fairness with Counterfactual Reasoning
Feb 16, 2023



The increasing application of Artificial Intelligence and Machine Learning models poses potential risks of unfair behavior and, in light of recent regulations, has attracted the attention of the research community. Several researchers focused on seeking new fairness definitions or developing approaches to identify biased predictions. However, none try to exploit the counterfactual space to this aim. In that direction, the methodology proposed in this work aims to unveil unfair model behaviors using counterfactual reasoning in the case of fairness under unawareness setting. A counterfactual version of equal opportunity named counterfactual fair opportunity is defined and two novel metrics that analyze the sensitive information of counterfactual samples are introduced. Experimental results on three different datasets show the efficacy of our methodologies and our metrics, disclosing the unfair behavior of classic machine learning and debiasing models.