 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarpRec: Unifying Academic Rigor and Industrial Scale for Responsible, Reproducible, and Efficient Recommendation
Feb 19, 2026Innovation in Recommender Systems is currently impeded by a fractured ecosystem, where researchers must choose between the ease of in-memory experimentation and the costly, complex rewriting required for distributed industrial engines. To bridge this gap, we present WarpRec, a high-performance framework that eliminates this trade-off through a novel, backend-agnostic architecture. It includes 50+ state-of-the-art algorithms, 40 metrics, and 19 filtering and splitting strategies that seamlessly transition from local execution to distributed training and optimization. The framework enforces ecological responsibility by integrating CodeCarbon for real-time energy tracking, showing that scalability need not come at the cost of scientific integrity or sustainability. Furthermore, WarpRec anticipates the shift toward Agentic AI, leading Recommender Systems to evolve from static ranking engines into interactive tools within the Generative AI ecosystem. In summary, WarpRec not only bridges the gap between academia and industry but also can serve as the architectural backbone for the next generation of sustainable, agent-ready Recommender Systems. Code is available at https://github.com/sisinflab/warprec/
RUVA: Personalized Transparent On-Device Graph Reasoning
Feb 17, 2026The Personal AI landscape is currently dominated by "Black Box" Retrieval-Augmented Generation. While standard vector databases offer statistical matching, they suffer from a fundamental lack of accountability: when an AI hallucinates or retrieves sensitive data, the user cannot inspect the cause nor correct the error. Worse, "deleting" a concept from a vector space is mathematically imprecise, leaving behind probabilistic "ghosts" that violate true privacy. We propose Ruva, the first "Glass Box" architecture designed for Human-in-the-Loop Memory Curation. Ruva grounds Personal AI in a Personal Knowledge Graph, enabling users to inspect what the AI knows and to perform precise redaction of specific facts. By shifting the paradigm from Vector Matching to Graph Reasoning, Ruva ensures the "Right to be Forgotten." Users are the editors of their own lives; Ruva hands them the pen. The project and the demo video are available at http://sisinf00.poliba.it/ruva/.
Exploring Diversity, Novelty, and Popularity Bias in ChatGPT's Recommendations
Jan 05, 2026ChatGPT has emerged as a versatile tool, demonstrating capabilities across diverse domains. Given these successes, the Recommender Systems (RSs) community has begun investigating its applications within recommendation scenarios primarily focusing on accuracy. While the integration of ChatGPT into RSs has garnered significant attention, a comprehensive analysis of its performance across various dimensions remains largely unexplored. Specifically, the capabilities of providing diverse and novel recommendations or exploring potential biases such as popularity bias have not been thoroughly examined. As the use of these models continues to expand, understanding these aspects is crucial for enhancing user satisfaction and achieving long-term personalization. This study investigates the recommendations provided by ChatGPT-3.5 and ChatGPT-4 by assessing ChatGPT's capabilities in terms of diversity, novelty, and popularity bias. We evaluate these models on three distinct datasets and assess their performance in Top-N recommendation and cold-start scenarios. The findings reveal that ChatGPT-4 matches or surpasses traditional recommenders, demonstrating the ability to balance novelty and diversity in recommendations. Furthermore, in the cold-start scenario, ChatGPT models exhibit superior performance in both accuracy and novelty, suggesting they can be particularly beneficial for new users. This research highlights the strengths and limitations of ChatGPT's recommendations, offering new perspectives on the capacity of these models to provide recommendations beyond accuracy-focused metrics.
On the Impact of Graph Neural Networks in Recommender Systems: A Topological Perspective
Dec 08, 2025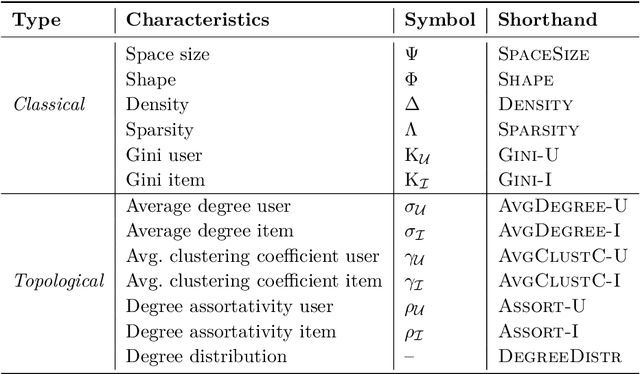
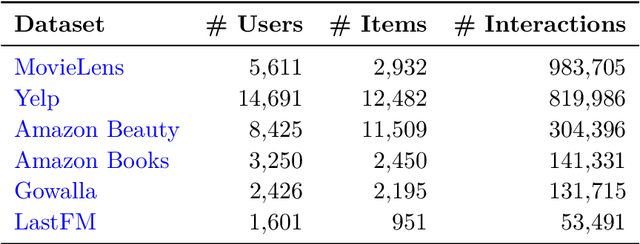
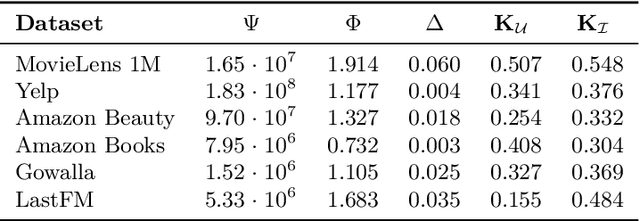
In recommender systems, user-item interactions can be modeled as a bipartite graph, where user and item nodes are connected by undirected edges. This graph-based view has motivated the rapid adoption of graph neural networks (GNNs), which often outperform collaborative filtering (CF) methods such as latent factor models, deep neural networks, and generative strategies. Yet, despite their empirical success, the reasons why GNNs offer systematic advantages over other CF approaches remain only partially understood. This monograph advances a topology-centered perspective on GNN-based recommendation. We argue that a comprehensive understanding of these models' performance should consider the structural properties of user-item graphs and their interaction with GNN architectural design. To support this view, we introduce a formal taxonomy that distills common modeling patterns across eleven representative GNN-based recommendation approaches and consolidates them into a unified conceptual pipeline. We further formalize thirteen classical and topological characteristics of recommendation datasets and reinterpret them through the lens of graph machine learning. Using these definitions, we analyze the considered GNN-based recommender architectures to assess how and to what extent they encode such properties. Building on this analysis, we derive an explanatory framework that links measurable dataset characteristics to model behavior and performance. Taken together, this monograph re-frames GNN-based recommendation through its topological underpinnings and outlines open theoretical, data-centric, and evaluation challenges for the next generation of topology-aware recommender systems.
Balancing Accuracy and Novelty with Sub-Item Popularity
Aug 07, 2025In the realm of music recommendation, sequential recommenders have shown promise in capturing the dynamic nature of music consumption. A key characteristic of this domain is repetitive listening, where users frequently replay familiar tracks. To capture these repetition patterns, recent research has introduced Personalised Popularity Scores (PPS), which quantify user-specific preferences based on historical frequency. While PPS enhances relevance in recommendation, it often reinforces already-known content, limiting the system's ability to surface novel or serendipitous items - key elements for fostering long-term user engagement and satisfaction. To address this limitation, we build upon RecJPQ, a Transformer-based framework initially developed to improve scalability in large-item catalogues through sub-item decomposition. We repurpose RecJPQ's sub-item architecture to model personalised popularity at a finer granularity. This allows us to capture shared repetition patterns across sub-embeddings - latent structures not accessible through item-level popularity alone. We propose a novel integration of sub-ID-level personalised popularity within the RecJPQ framework, enabling explicit control over the trade-off between accuracy and personalised novelty. Our sub-ID-level PPS method (sPPS) consistently outperforms item-level PPS by achieving significantly higher personalised novelty without compromising recommendation accuracy. Code and experiments are publicly available at https://github.com/sisinflab/Sub-id-Popularity.
Are the Hidden States Hiding Something? Testing the Limits of Factuality-Encoding Capabilities in LLMs
May 22, 2025Factual hallucinations are a major challenge for Large Language Models (LLMs). They undermine reliability and user trust by generating inaccurate or fabricated content. Recent studies suggest that when generating false statements, the internal states of LLMs encode information about truthfulness. However, these studies often rely on synthetic datasets that lack realism, which limits generalization when evaluating the factual accuracy of text generated by the model itself. In this paper, we challenge the findings of previous work by investigating truthfulness encoding capabilities, leading to the generation of a more realistic and challenging dataset. Specifically, we extend previous work by introducing: (1) a strategy for sampling plausible true-false factoid sentences from tabular data and (2) a procedure for generating realistic, LLM-dependent true-false datasets from Question Answering collections. Our analysis of two open-source LLMs reveals that while the findings from previous studies are partially validated, generalization to LLM-generated datasets remains challenging. This study lays the groundwork for future research on factuality in LLMs and offers practical guidelines for more effective evaluation.
LLaMAs Have Feelings Too: Unveiling Sentiment and Emotion Representations in LLaMA Models Through Probing
May 22, 2025Large Language Models (LLMs) have rapidly become central to NLP, demonstrating their ability to adapt to various tasks through prompting techniques, including sentiment analysis. However, we still have a limited understanding of how these models capture sentiment-related information. This study probes the hidden layers of Llama models to pinpoint where sentiment features are most represented and to assess how this affects sentiment analysis. Using probe classifiers, we analyze sentiment encoding across layers and scales, identifying the layers and pooling methods that best capture sentiment signals. Our results show that sentiment information is most concentrated in mid-layers for binary polarity tasks, with detection accuracy increasing up to 14% over prompting techniques. Additionally, we find that in decoder-only models, the last token is not consistently the most informative for sentiment encoding. Finally, this approach enables sentiment tasks to be performed with memory requirements reduced by an average of 57%. These insights contribute to a broader understanding of sentiment in LLMs, suggesting layer-specific probing as an effective approach for sentiment tasks beyond prompting, with potential to enhance model utility and reduce memory requirements.
Do LLMs Memorize Recommendation Datasets? A Preliminary Study on MovieLens-1M
May 15, 2025Large Language Models (LLMs) have become increasingly central to recommendation scenarios due to their remarkable natural language understanding and generation capabilities. Although significant research has explored the use of LLMs for various recommendation tasks, little effort has been dedicated to verifying whether they have memorized public recommendation dataset as part of their training data. This is undesirable because memorization reduces the generalizability of research findings, as benchmarking on memorized datasets does not guarantee generalization to unseen datasets. Furthermore, memorization can amplify biases, for example, some popular items may be recommended more frequently than others. In this work, we investigate whether LLMs have memorized public recommendation datasets. Specifically, we examine two model families (GPT and Llama) across multiple sizes, focusing on one of the most widely used dataset in recommender systems: MovieLens-1M. First, we define dataset memorization as the extent to which item attributes, user profiles, and user-item interactions can be retrieved by prompting the LLMs. Second, we analyze the impact of memorization on recommendation performance. Lastly, we examine whether memorization varies across model families and model sizes. Our results reveal that all models exhibit some degree of memorization of MovieLens-1M, and that recommendation performance is related to the extent of memorization. We have made all the code publicly available at: https://github.com/sisinflab/LLM-MemoryInspector
Training-Free Consistency Pipeline for Fashion Repose
Jan 23, 2025



Recent advancements in diffusion models have significantly broadened the possibilities for editing images of real-world objects. However, performing non-rigid transformations, such as changing the pose of objects or image-based conditioning, remains challenging. Maintaining object identity during these edits is difficult, and current methods often fall short of the precision needed for industrial applications, where consistency is critical. Additionally, fine-tuning diffusion models requires custom training data, which is not always accessible in real-world scenarios. This work introduces FashionRepose, a training-free pipeline for non-rigid pose editing specifically designed for the fashion industry. The approach integrates off-the-shelf models to adjust poses of long-sleeve garments, maintaining identity and branding attributes. FashionRepose uses a zero-shot approach to perform these edits in near real-time, eliminating the need for specialized training. consistent image editing. The solution holds potential for applications in the fashion industry and other fields demanding identity preservation in image editing.
Scalable Cloud-Native Pipeline for Efficient 3D Model Reconstruction from Monocular Smartphone Images
Sep 28, 2024In recent years, 3D models have gained popularity in various fields, including entertainment, manufacturing, and simulation. However, manually creating these models can be a time-consuming and resource-intensive process, making it impractical for large-scale industrial applications. To address this issue, researchers are exploiting Artificial Intelligence and Machine Learning algorithms to automatically generate 3D models effortlessly. In this paper, we present a novel cloud-native pipeline that can automatically reconstruct 3D models from monocular 2D images captured using a smartphone camera. Our goal is to provide an efficient and easily-adoptable solution that meets the Industry 4.0 standards for creating a Digital Twin model, which could enhance personnel expertise through accelerated training. We leverage machine learning models developed by NVIDIA Research Labs alongside a custom-designed pose recorder with a unique pose compensation component based on the ARCore framework by Google. Our solution produces a reusable 3D model, with embedded materials and textures, exportable and customizable in any external 3D modelling software or 3D engine. Furthermore, the whole workflow is implemented by adopting the microservices architecture standard, enabling each component of the pipeline to operate as a standalone replaceable module.