 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Memorize Recommendation Datasets? A Preliminary Study on MovieLens-1M
May 15, 2025Large Language Models (LLMs) have become increasingly central to recommendation scenarios due to their remarkable natural language understanding and generation capabilities. Although significant research has explored the use of LLMs for various recommendation tasks, little effort has been dedicated to verifying whether they have memorized public recommendation dataset as part of their training data. This is undesirable because memorization reduces the generalizability of research findings, as benchmarking on memorized datasets does not guarantee generalization to unseen datasets. Furthermore, memorization can amplify biases, for example, some popular items may be recommended more frequently than others. In this work, we investigate whether LLMs have memorized public recommendation datasets. Specifically, we examine two model families (GPT and Llama) across multiple sizes, focusing on one of the most widely used dataset in recommender systems: MovieLens-1M. First, we define dataset memorization as the extent to which item attributes, user profiles, and user-item interactions can be retrieved by prompting the LLMs. Second, we analyze the impact of memorization on recommendation performance. Lastly, we examine whether memorization varies across model families and model sizes. Our results reveal that all models exhibit some degree of memorization of MovieLens-1M, and that recommendation performance is related to the extent of memorization. We have made all the code publicly available at: https://github.com/sisinflab/LLM-MemoryInspector
Hyperband-based Bayesian Optimization for Black-box Prompt Selection
Dec 10, 2024



Optimal prompt selection is crucial for maximizing large language model (LLM) performance on downstream tasks. As the most powerful models are proprietary and can only be invoked via an API, users often manually refine prompts in a black-box setting by adjusting instructions and few-shot examples until they achieve good performance as measured on a validation set. Recent methods addressing static black-box prompt selection face significant limitations: They often fail to leverage the inherent structure of prompts, treating instructions and few-shot exemplars as a single block of text. Moreover, they often lack query-efficiency by evaluating prompts on all validation instances, or risk sub-optimal selection of a prompt by using random subsets of validation instances. We introduce HbBoPs, a novel Hyperband-based Bayesian optimization method for black-box prompt selection addressing these key limitations. Our approach combines a structural-aware deep kernel Gaussian Process to model prompt performance with Hyperband as a multi-fidelity scheduler to select the number of validation instances for prompt evaluations. The structural-aware modeling approach utilizes separate embeddings for instructions and few-shot exemplars, enhancing the surrogate model's ability to capture prompt performance and predict which prompt to evaluate next in a sample-efficient manner. Together with Hyperband as a multi-fidelity scheduler we further enable query-efficiency by adaptively allocating resources across different fidelity levels, keeping the total number of validation instances prompts are evaluated on low. Extensive evaluation across ten benchmarks and three LLMs demonstrate that HbBoPs outperforms state-of-the-art methods.
Formalizing Multimedia Recommendation through Multimodal Deep Learning
Sep 11, 2023Recommender systems (RSs) offer personalized navigation experiences on online platforms, but recommendation remains a challenging task, particularly in specific scenarios and domains. Multimodality can help tap into richer information sources and construct more refined user/item profiles for recommendations. However, existing literature lacks a shared and universal schema for modeling and solving the recommendation problem through the lens of multimodality. This work aims to formalize a general multimodal schema for multimedia recommendation. It provides a comprehensive literature review of multimodal approaches for multimedia recommendation from the last eight years, outlines the theoretical foundations of a multimodal pipeline, and demonstrates its rationale by applying it to selected state-of-the-art approaches. The work also conducts a benchmarking analysis of recent algorithms for multimedia recommendation within Elliot, a rigorous framework for evaluating recommender systems. The main aim is to provide guidelines for designing and implementing the next generation of multimodal approaches in multimedia recommendation.
Understanding the Effects of Adversarial Personalized Ranking Optimization Method on Recommendation Quality
Jul 29, 2021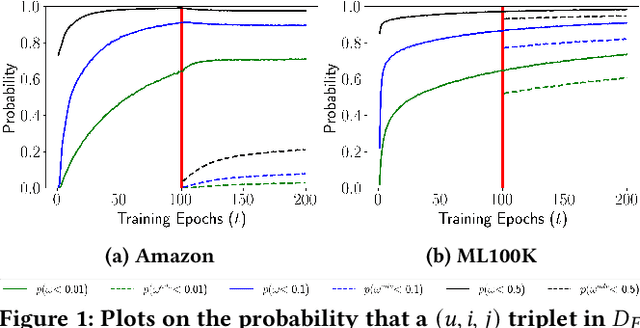
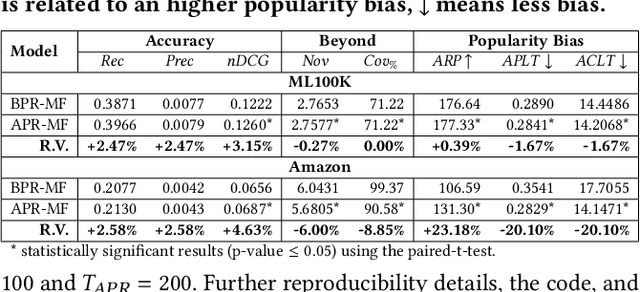
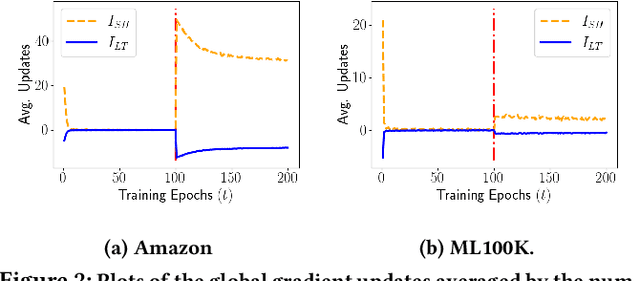
Recommender systems (RSs) employ user-item feedback, e.g., ratings, to match customers to personalized lists of products. Approaches to top-k recommendation mainly rely on Learning-To-Rank algorithms and, among them, the most widely adopted is Bayesian Personalized Ranking (BPR), which bases on a pair-wise optimization approach. Recently, BPR has been found vulnerable against adversarial perturbations of its model parameters. Adversarial Personalized Ranking (APR) mitigates this issue by robustifying BPR via an adversarial training procedure. The empirical improvements of APR's accuracy performance on BPR have led to its wide use in several recommender models. However, a key overlooked aspect has been the beyond-accuracy performance of APR, i.e., novelty, coverage, and amplification of popularity bias, considering that recent results suggest that BPR, the building block of APR, is sensitive to the intensification of biases and reduction of recommendation novelty. In this work, we model the learning characteristics of the BPR and APR optimization frameworks to give mathematical evidence that, when the feedback data have a tailed distribution, APR amplifies the popularity bias more than BPR due to an unbalanced number of received positive updates from short-head items. Using matrix factorization (MF), we empirically validate the theoretical results by performing preliminary experiments on two public datasets to compare BPR-MF and APR-MF performance on accuracy and beyond-accuracy metrics. The experimental results consistently show the degradation of novelty and coverage measures and a worrying amplification of bias.
Elliot: a Comprehensive and Rigorous Framework for Reproducible Recommender Systems Evaluation
Mar 03, 2021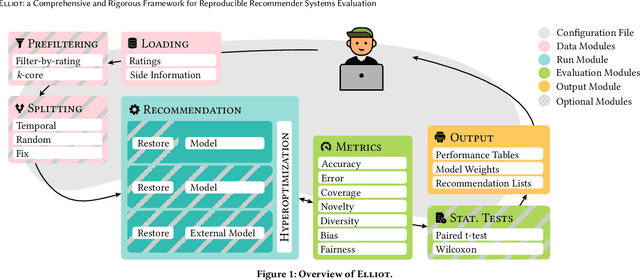
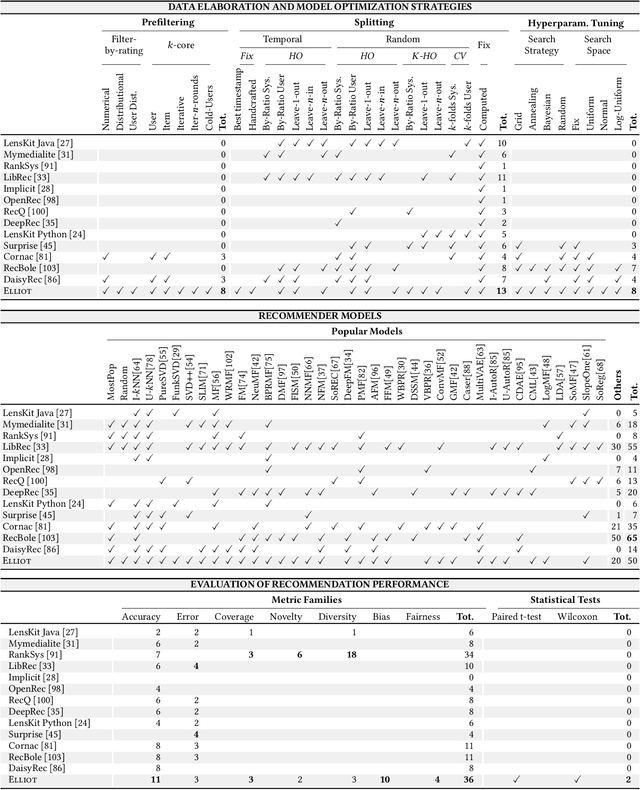


Recommender Systems have shown to be an effective way to alleviate the over-choice problem and provide accurate and tailored recommendations. However, the impressive number of proposed recommendation algorithms, splitting strategies, evaluation protocols, metrics, and tasks, has made rigorous experimental evaluation particularly challenging. Puzzled and frustrated by the continuous recreation of appropriate evaluation benchmarks, experimental pipelines, hyperparameter optimization, and evaluation procedures, we have developed an exhaustive framework to address such needs. Elliot is a comprehensive recommendation framework that aims to run and reproduce an entire experimental pipeline by processing a simple configuration file. The framework loads, filters, and splits the data considering a vast set of strategies (13 splitting methods and 8 filtering approaches, from temporal training-test splitting to nested K-folds Cross-Validation). Elliot optimizes hyperparameters (51 strategies) for several recommendation algorithms (50), selects the best models, compares them with the baselines providing intra-model statistics, computes metrics (36) spanning from accuracy to beyond-accuracy, bias, and fairness, and conducts statistical analysis (Wilcoxon and Paired t-test). The aim is to provide the researchers with a tool to ease (and make them reproducible) all the experimental evaluation phases, from data reading to results collection. Elliot is available on GitHub (https://github.com/sisinflab/elliot).
An Empirical Study of DNNs Robustification Inefficacy in Protecting Visual Recommenders
Oct 02, 2020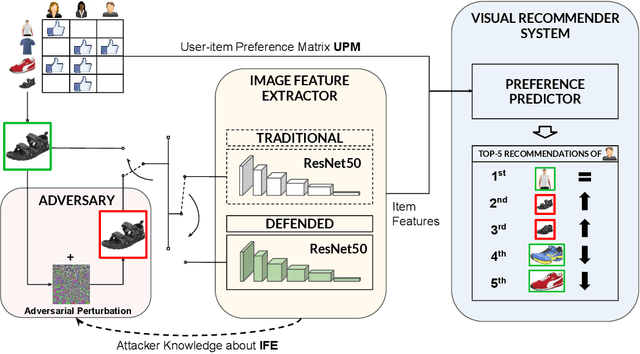
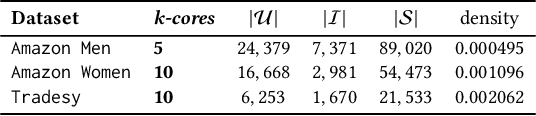

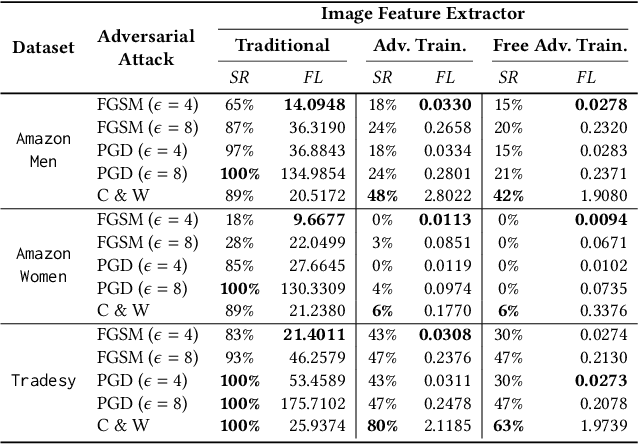
Visual-based recommender systems (VRSs) enhance recommendation performance by integrating users' feedback with the visual features of product images extracted from a deep neural network (DNN). Recently, human-imperceptible images perturbations, defined \textit{adversarial attacks}, have been demonstrated to alter the VRSs recommendation performance, e.g., pushing/nuking category of products. However, since adversarial training techniques have proven to successfully robustify DNNs in preserving classification accuracy, to the best of our knowledge, two important questions have not been investigated yet: 1) How well can these defensive mechanisms protect the VRSs performance? 2) What are the reasons behind ineffective/effective defenses? To answer these questions, we define a set of defense and attack settings, as well as recommender models, to empirically investigate the efficacy of defensive mechanisms. The results indicate alarming risks in protecting a VRS through the DNN robustification. Our experiments shed light on the importance of visual features in very effective attack scenarios. Given the financial impact of VRSs on many companies, we believe this work might rise the need to investigate how to successfully protect visual-based recommenders. Source code and data are available at https://anonymous.4open.science/r/868f87ca-c8a4-41ba-9af9-20c41de33029/.
Adversarial Machine Learning in Recommender Systems: State of the art and Challenges
May 20, 2020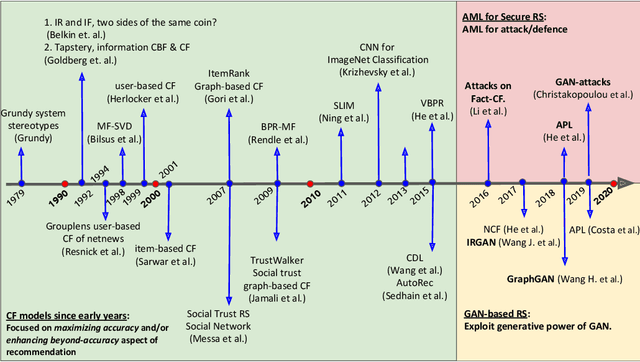
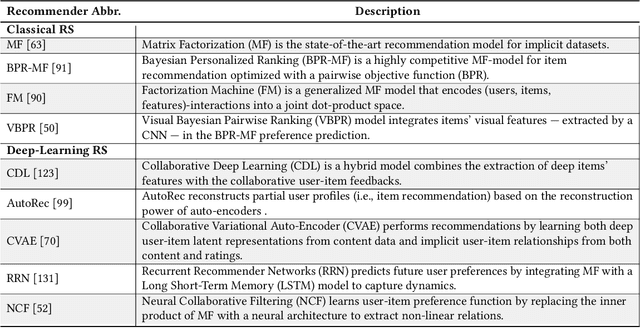

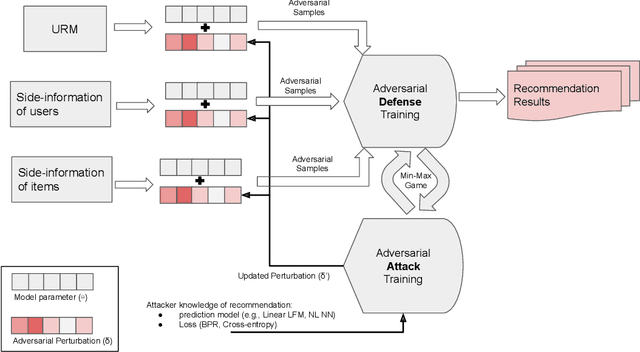
Latent-factor models (LFM) based on collaborative filtering (CF), such as matrix factorization (MF) and deep CF methods, are widely used in modern recommender systems (RS) due to their excellent performance and recommendation accuracy. Notwithstanding their great success, in recent years, it has been shown that these methods are vulnerable to adversarial examples, i.e., subtle but non-random perturbations designed to force recommendation models to produce erroneous outputs. The main reason for this behavior is that user interaction data used for training of LFM can be contaminated by malicious activities or users' misoperation that can induce an unpredictable amount of natural noise and harm recommendation outcomes. On the other side, it has been shown that these systems, conceived originally to attack machine learning applications, can be successfully adopted to strengthen their robustness against attacks as well as to train more precise recommendation engines. In this respect, the goal of this survey is two-fold: (i) to present recent advances on AML-RS for the security of RS (i.e., attacking and defense recommendation models), (ii) to show another successful application of AML in generative adversarial networks (GANs), which use the core concept of learning in AML (i.e., the min-max game) for generative applications. In this survey, we provide an exhaustive literature review of 60 articles published in major RS and ML journals and conferences. This review serves as a reference for the RS community, working on the security of RS and recommendation models leveraging generative models to improve their quality.
Assessing the Impact of a User-Item Collaborative Attack on Class of Users
Aug 21, 2019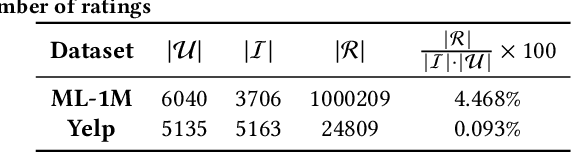
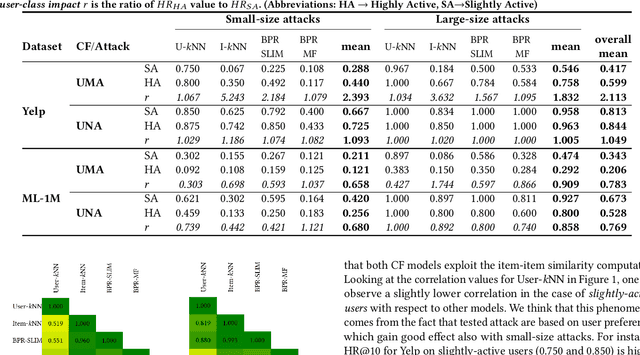
Collaborative Filtering (CF) models lie at the core of most recommendation systems due to their state-of-the-art accuracy. They are commonly adopted in e-commerce and online services for their impact on sales volume and/or diversity, and their impact on companies' outcome. However, CF models are only as good as the interaction data they work with. As these models rely on outside sources of information, counterfeit data such as user ratings or reviews can be injected by attackers to manipulate the underlying data and alter the impact of resulting recommendations, thus implementing a so-called shilling attack. While previous works have focused on evaluating shilling attack strategies from a global perspective paying particular attention to the effect of the size of attacks and attacker's knowledge, in this work we explore the effectiveness of shilling attacks under novel aspects. First, we investigate the effect of attack strategies crafted on a target user in order to push the recommendation of a low-ranking item to a higher position, referred to as user-item attack. Second, we evaluate the effectiveness of attacks in altering the impact of different CF models by contemplating the class of the target user, from the perspective of the richness of her profile (i.e., cold v.s. warm user). Finally, similar to previous work we contemplate the size of attack (i.e., the amount of fake profiles injected) in examining their success. The results of experiments on two widely used datasets in business and movie domains, namely Yelp and MovieLens, suggest that warm and cold users exhibit contrasting behaviors in datasets with different characteristics.