 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarpRec: Unifying Academic Rigor and Industrial Scale for Responsible, Reproducible, and Efficient Recommendation
Feb 19, 2026Innovation in Recommender Systems is currently impeded by a fractured ecosystem, where researchers must choose between the ease of in-memory experimentation and the costly, complex rewriting required for distributed industrial engines. To bridge this gap, we present WarpRec, a high-performance framework that eliminates this trade-off through a novel, backend-agnostic architecture. It includes 50+ state-of-the-art algorithms, 40 metrics, and 19 filtering and splitting strategies that seamlessly transition from local execution to distributed training and optimization. The framework enforces ecological responsibility by integrating CodeCarbon for real-time energy tracking, showing that scalability need not come at the cost of scientific integrity or sustainability. Furthermore, WarpRec anticipates the shift toward Agentic AI, leading Recommender Systems to evolve from static ranking engines into interactive tools within the Generative AI ecosystem. In summary, WarpRec not only bridges the gap between academia and industry but also can serve as the architectural backbone for the next generation of sustainable, agent-ready Recommender Systems. Code is available at https://github.com/sisinflab/warprec/
On the Impact of Graph Neural Networks in Recommender Systems: A Topological Perspective
Dec 08, 2025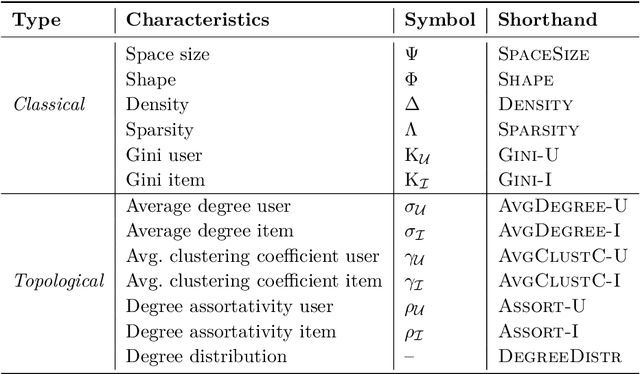
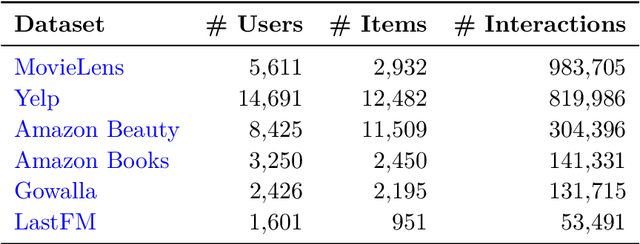
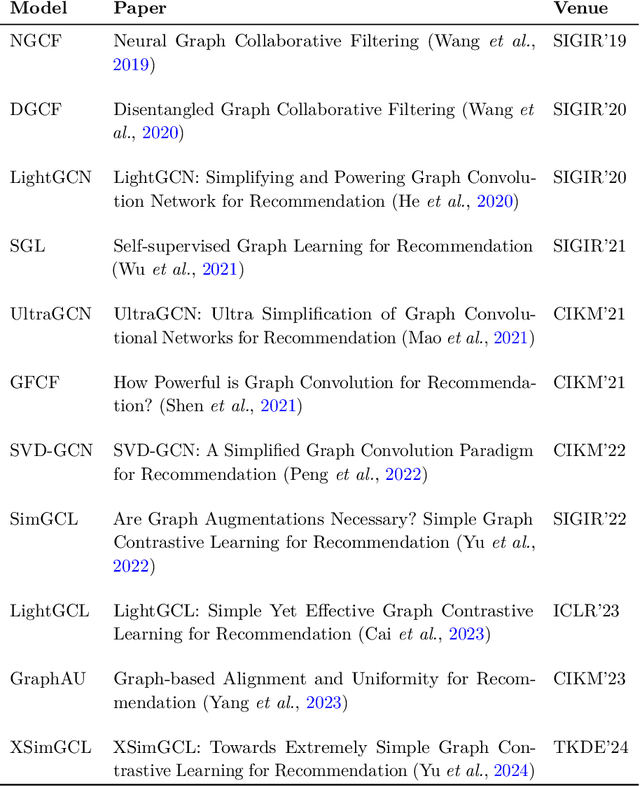
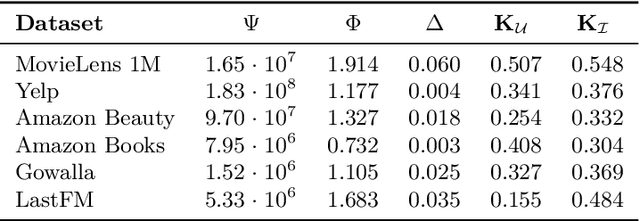
In recommender systems, user-item interactions can be modeled as a bipartite graph, where user and item nodes are connected by undirected edges. This graph-based view has motivated the rapid adoption of graph neural networks (GNNs), which often outperform collaborative filtering (CF) methods such as latent factor models, deep neural networks, and generative strategies. Yet, despite their empirical success, the reasons why GNNs offer systematic advantages over other CF approaches remain only partially understood. This monograph advances a topology-centered perspective on GNN-based recommendation. We argue that a comprehensive understanding of these models' performance should consider the structural properties of user-item graphs and their interaction with GNN architectural design. To support this view, we introduce a formal taxonomy that distills common modeling patterns across eleven representative GNN-based recommendation approaches and consolidates them into a unified conceptual pipeline. We further formalize thirteen classical and topological characteristics of recommendation datasets and reinterpret them through the lens of graph machine learning. Using these definitions, we analyze the considered GNN-based recommender architectures to assess how and to what extent they encode such properties. Building on this analysis, we derive an explanatory framework that links measurable dataset characteristics to model behavior and performance. Taken together, this monograph re-frames GNN-based recommendation through its topological underpinnings and outlines open theoretical, data-centric, and evaluation challenges for the next generation of topology-aware recommender systems.
Impacts of Mainstream-Driven Algorithms on Recommendations for Children Across Domains: A Reproducibility Study
Jul 09, 2025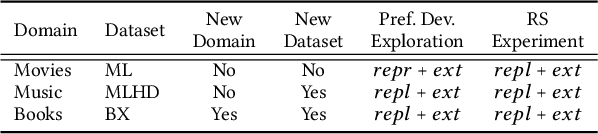
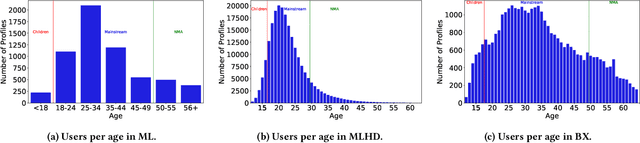

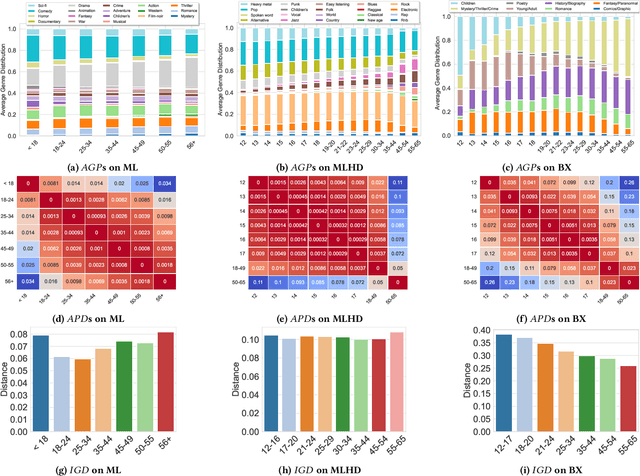
Children are often exposed to items curated by recommendation algorithms. Yet, research seldom considers children as a user group, and when it does, it is anchored on datasets where children are underrepresented, risking overlooking their interests, favoring those of the majority, i.e., mainstream users. Recently, Ungruh et al. demonstrated that children's consumption patterns and preferences differ from those of mainstream users, resulting in inconsistent recommendation algorithm performance and behavior for this user group. These findings, however, are based on two datasets with a limited child user sample. We reproduce and replicate this study on a wider range of datasets in the movie, music, and book domains, uncovering interaction patterns and aspects of child-recommender interactions consistent across domains, as well as those specific to some user samples in the data. We also extend insights from the original study with popularity bias metrics, given the interpretation of results from the original study. With this reproduction and extension, we uncover consumption patterns and differences between age groups stemming from intrinsic differences between children and others, and those unique to specific datasets or domains.
Understanding the Influence of Data Characteristics on the Performance of Point-of-Interest Recommendation Algorithms
Nov 13, 2023The performance of recommendation algorithms is closely tied to key characteristics of the data sets they use, such as sparsity, popularity bias, and preference distributions. In this paper, we conduct a comprehensive explanatory analysis to shed light on the impact of a broad range of data characteristics within the point-of-interest (POI) recommendation domain. To accomplish this, we extend prior methodologies used to characterize traditional recommendation problems by introducing new explanatory variables specifically relevant to POI recommendation. We subdivide a POI recommendation data set on New York City into domain-driven subsamples to measure the effect of varying these characteristics on different state-of-the-art POI recommendation algorithms in terms of accuracy, novelty, and item exposure. Our findings, obtained through the application of an explanatory framework employing multiple-regression models, reveal that the relevant independent variables encompass all categories of data characteristics and account for as much as $R^2 = $ 85-90\% of the accuracy and item exposure achieved by the algorithms. Our study reaffirms the pivotal role of prominent data characteristics, such as density, popularity bias, and the distribution of check-ins in POI recommendation. Additionally, we unveil novel factors, such as the proximity of user activity to the city center and the duration of user activity. In summary, our work reveals why certain POI recommendation algorithms excel in specific recommendation problems and, conversely, offers practical insights into which data characteristics should be modified (or explicitly recognized) to achieve better performance.
Challenging the Myth of Graph Collaborative Filtering: a Reasoned and Reproducibility-driven Analysis
Aug 01, 2023The success of graph neural network-based models (GNNs) has significantly advanced recommender systems by effectively modeling users and items as a bipartite, undirected graph. However, many original graph-based works often adopt results from baseline papers without verifying their validity for the specific configuration under analysis. Our work addresses this issue by focusing on the replicability of results. We present a code that successfully replicates results from six popular and recent graph recommendation models (NGCF, DGCF, LightGCN, SGL, UltraGCN, and GFCF) on three common benchmark datasets (Gowalla, Yelp 2018, and Amazon Book). Additionally, we compare these graph models with traditional collaborative filtering models that historically performed well in offline evaluations. Furthermore, we extend our study to two new datasets (Allrecipes and BookCrossing) that lack established setups in existing literature. As the performance on these datasets differs from the previous benchmarks, we analyze the impact of specific dataset characteristics on recommendation accuracy. By investigating the information flow from users' neighborhoods, we aim to identify which models are influenced by intrinsic features in the dataset structure. The code to reproduce our experiments is available at: https://github.com/sisinflab/Graph-RSs-Reproducibility.
Top-N Recommendation Algorithms: A Quest for the State-of-the-Art
Mar 02, 2022
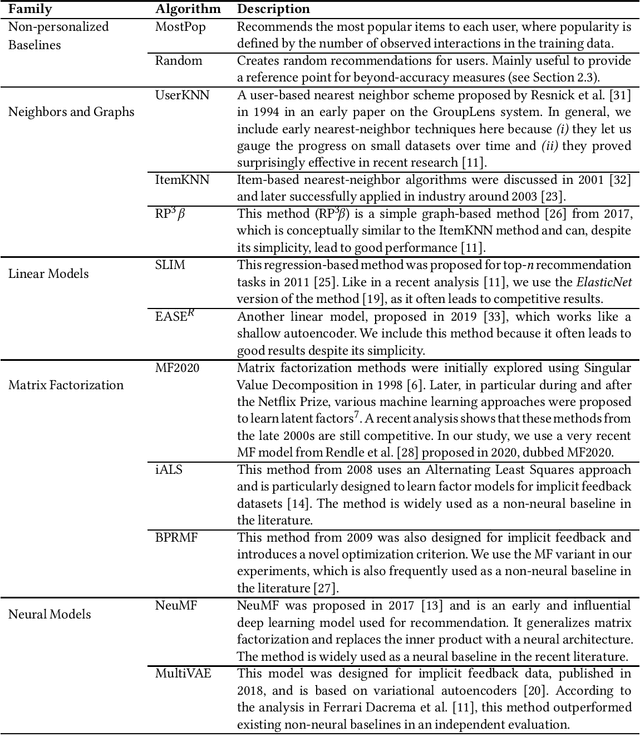
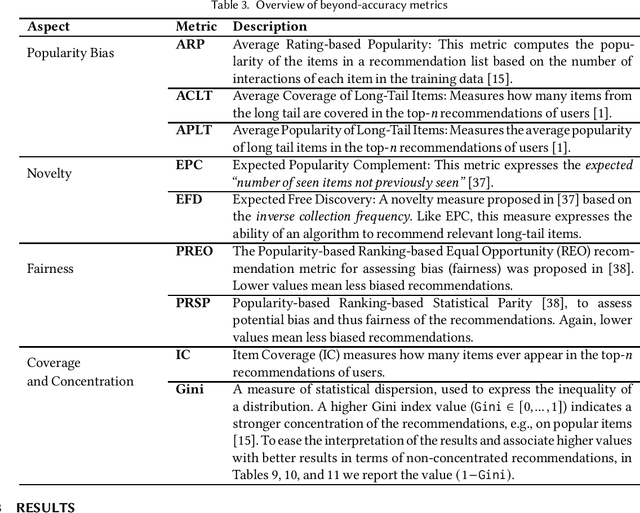

Research on recommender systems algorithms, like other areas of applied machine learning, is largely dominated by efforts to improve the state-of-the-art, typically in terms of accuracy measures. Several recent research works however indicate that the reported improvements over the years sometimes "don't add up", and that methods that were published several years ago often outperform the latest models when evaluated independently. Different factors contribute to this phenomenon, including that some researchers probably often only fine-tune their own models but not the baselines. In this paper, we report the outcomes of an in-depth, systematic, and reproducible comparison of ten collaborative filtering algorithms - covering both traditional and neural models - on several common performance measures on three datasets which are frequently used for evaluation in the recent literature. Our results show that there is no consistent winner across datasets and metrics for the examined top-n recommendation task. Moreover, we find that for none of the accuracy measurements any of the considered neural models led to the best performance. Regarding the performance ranking of algorithms across the measurements, we found that linear models, nearest-neighbor methods, and traditional matrix factorization consistently perform well for the evaluated modest-sized, but commonly-used datasets. Our work shall therefore serve as a guideline for researchers regarding existing baselines to consider in future performance comparisons. Moreover, by providing a set of fine-tuned baseline models for different datasets, we hope that our work helps to establish a common understanding of the state-of-the-art for top-n recommendation tasks.
Simulations for novel problems in recommendation: analyzing misinformation and data characteristics
Oct 08, 2021In this position paper, we discuss recent applications of simulation approaches for recommender systems tasks. In particular, we describe how they were used to analyze the problem of misinformation spreading and understand which data characteristics affect the performance of recommendation algorithms more significantly. We also present potential lines of future work where simulation methods could advance the work in the recommendation community.
Adherence and Constancy in LIME-RS Explanations for Recommendation
Sep 05, 2021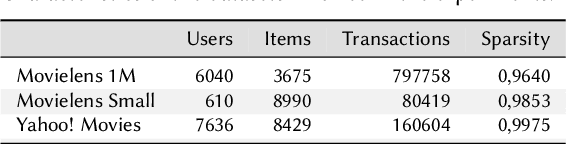
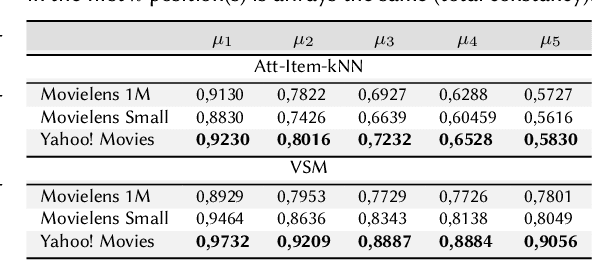
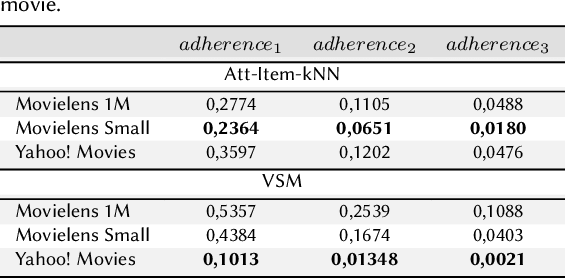
Explainable Recommendation has attracted a lot of attention due to a renewed interest in explainable artificial intelligence. In particular, post-hoc approaches have proved to be the most easily applicable ones to increasingly complex recommendation models, which are then treated as black-boxes. The most recent literature has shown that for post-hoc explanations based on local surrogate models, there are problems related to the robustness of the approach itself. This consideration becomes even more relevant in human-related tasks like recommendation. The explanation also has the arduous task of enhancing increasingly relevant aspects of user experience such as transparency or trustworthiness. This paper aims to show how the characteristics of a classical post-hoc model based on surrogates is strongly model-dependent and does not prove to be accountable for the explanations generated.
Reenvisioning Collaborative Filtering vs Matrix Factorization
Jul 28, 2021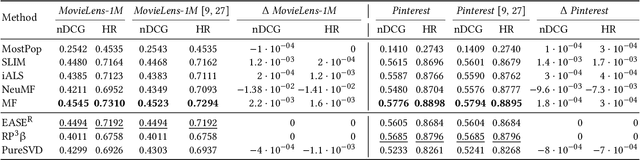
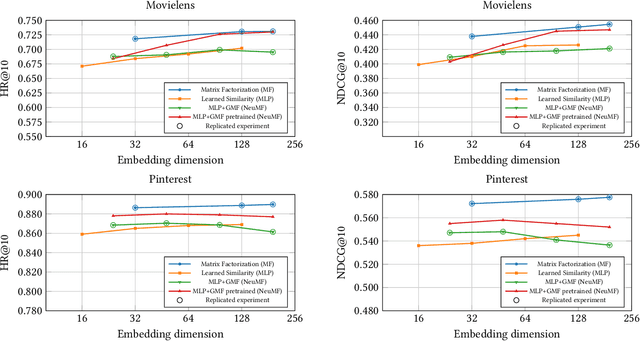

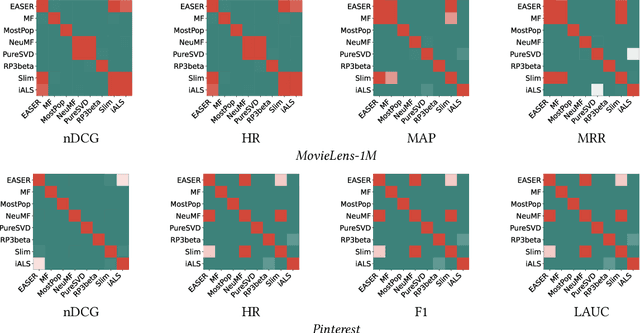
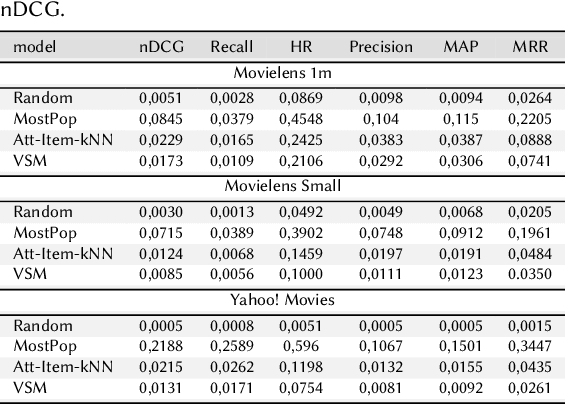
Collaborative filtering models based on matrix factorization and learned similarities using Artificial Neural Networks (ANNs) have gained significant attention in recent years. This is, in part, because ANNs have demonstrated good results in a wide variety of recommendation tasks. The introduction of ANNs within the recommendation ecosystem has been recently questioned, raising several comparisons in terms of efficiency and effectiveness. One aspect most of these comparisons have in common is their focus on accuracy, neglecting other evaluation dimensions important for the recommendation, such as novelty, diversity, or accounting for biases. We replicate experiments from three papers that compare Neural Collaborative Filtering (NCF) and Matrix Factorization (MF), to extend the analysis to other evaluation dimensions. Our contribution shows that the experiments are entirely reproducible, and we extend the study including other accuracy metrics and two statistical hypothesis tests. We investigated the Diversity and Novelty of the recommendations, showing that MF provides a better accuracy also on the long tail, although NCF provides a better item coverage and more diversified recommendations. We discuss the bias effect generated by the tested methods. They show a relatively small bias, but other recommendation baselines, with competitive accuracy performance, consistently show to be less affected by this issue. This is the first work, to the best of our knowledge, where several evaluation dimensions have been explored for an array of SOTA algorithms covering recent adaptations of ANNs and MF. Hence, we show the potential these techniques may have on beyond-accuracy evaluation while analyzing the effect on reproducibility these complementary dimensions may spark. Available at github.com/sisinflab/Reenvisioning-the-comparison-between-Neural-Collaborative-Filtering-and-Matrix-Factorization
Point-of-Interest Recommender Systems: A Survey from an Experimental Perspective
Jun 18, 2021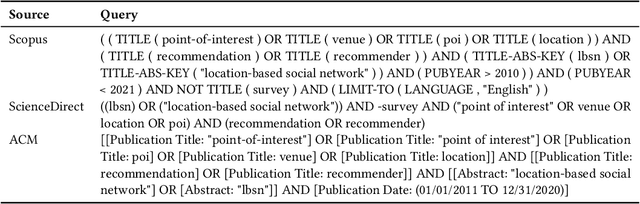
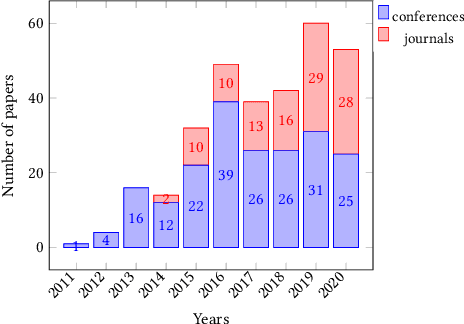

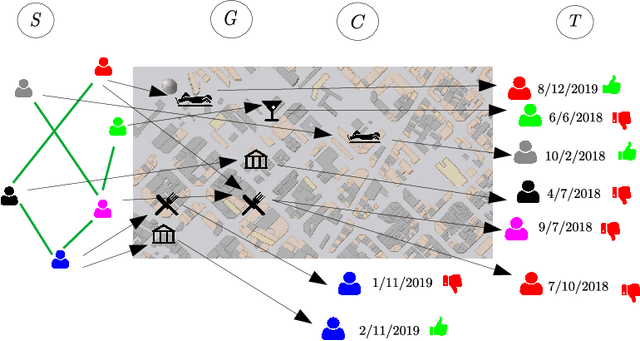
Point-of-Interest recommendation is an increasing research and developing area within the widely adopted technologies known as Recommender Systems. Among them, those that exploit information coming from Location-Based Social Networks (LBSNs) are very popular nowadays and could work with different information sources, which pose several challenges and research questions to the community as a whole. We present a systematic review focused on the research done in the last 10 years about this topic. We discuss and categorize the algorithms and evaluation methodologies used in these works and point out the opportunities and challenges that remain open in the field. More specifically, we report the leading recommendation techniques and information sources that have been exploited more often (such as the geographical signal and deep learning approaches) while we also alert about the lack of reproducibility in the field that may hinder real performance improvements.