 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-N Recommendation Algorithms: A Quest for the State-of-the-Art
Paper and Code

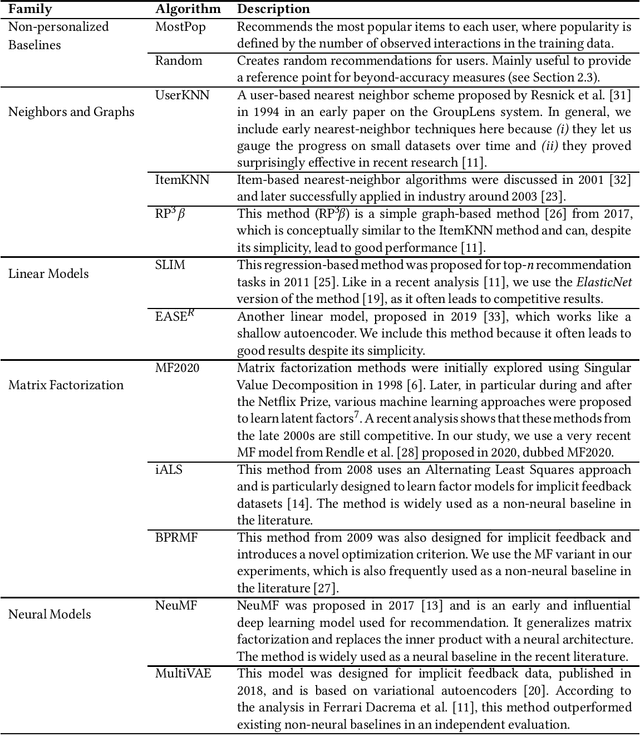
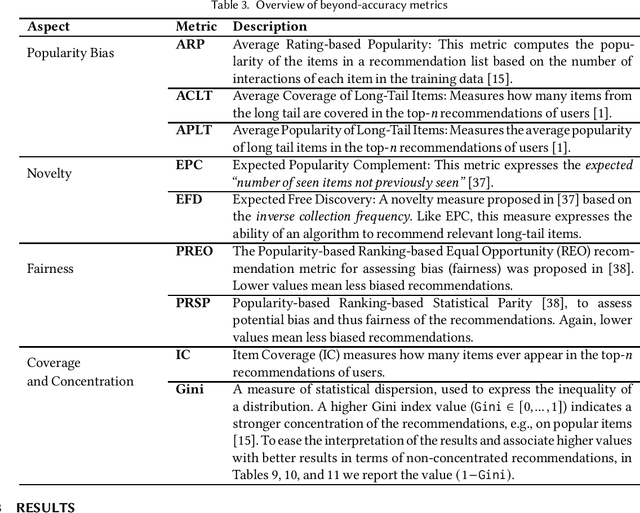

Research on recommender systems algorithms, like other areas of applied machine learning, is largely dominated by efforts to improve the state-of-the-art, typically in terms of accuracy measures. Several recent research works however indicate that the reported improvements over the years sometimes "don't add up", and that methods that were published several years ago often outperform the latest models when evaluated independently. Different factors contribute to this phenomenon, including that some researchers probably often only fine-tune their own models but not the baselines. In this paper, we report the outcomes of an in-depth, systematic, and reproducible comparison of ten collaborative filtering algorithms - covering both traditional and neural models - on several common performance measures on three datasets which are frequently used for evaluation in the recent literature. Our results show that there is no consistent winner across datasets and metrics for the examined top-n recommendation task. Moreover, we find that for none of the accuracy measurements any of the considered neural models led to the best performance. Regarding the performance ranking of algorithms across the measurements, we found that linear models, nearest-neighbor methods, and traditional matrix factorization consistently perform well for the evaluated modest-sized, but commonly-used datasets. Our work shall therefore serve as a guideline for researchers regarding existing baselines to consider in future performance comparisons. Moreover, by providing a set of fine-tuned baseline models for different datasets, we hope that our work helps to establish a common understanding of the state-of-the-art for top-n recommendation tasks.