 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Recommender Systems: Understanding and Minimizing the Carbon Footprint of AI-Powered Personalization
Sep 16, 2025As global warming soars, the need to assess and reduce the environmental impact of recommender systems is becoming increasingly urgent. Despite this, the recommender systems community hardly understands, addresses, and evaluates the environmental impact of their work. In this study, we examine the environmental impact of recommender systems research by reproducing typical experimental pipelines. Based on our results, we provide guidelines for researchers and practitioners on how to minimize the environmental footprint of their work and implement green recommender systems - recommender systems designed to minimize their energy consumption and carbon footprint. Our analysis covers 79 papers from the 2013 and 2023 ACM RecSys conferences, comparing traditional "good old-fashioned AI" models with modern deep learning models. We designed and reproduced representative experimental pipelines for both years, measuring energy consumption using a hardware energy meter and converting it into CO2 equivalents. Our results show that papers utilizing deep learning models emit approximately 42 times more CO2 equivalents than papers using traditional models. On average, a single deep learning-based paper generates 2,909 kilograms of CO2 equivalents - more than the carbon emissions of a person flying from New York City to Melbourne or the amount of CO2 sequestered by one tree over 260 years. This work underscores the urgent need for the recommender systems and wider machine learning communities to adopt green AI principles, balancing algorithmic advancements and environmental responsibility to build a sustainable future with AI-powered personalization.
We're Still Doing It (All) Wrong: Recommender Systems, Fifteen Years Later
Sep 11, 2025
In 2011, Xavier Amatriain sounded the alarm: recommender systems research was "doing it all wrong" [1]. His critique, rooted in statistical misinterpretation and methodological shortcuts, remains as relevant today as it was then. But rather than correcting course, we added new layers of sophistication on top of the same broken foundations. This paper revisits Amatriain's diagnosis and argues that many of the conceptual, epistemological, and infrastructural failures he identified still persist, in more subtle or systemic forms. Drawing on recent work in reproducibility, evaluation methodology, environmental impact, and participatory design, we showcase how the field's accelerating complexity has outpaced its introspection. We highlight ongoing community-led initiatives that attempt to shift the paradigm, including workshops, evaluation frameworks, and calls for value-sensitive and participatory research. At the same time, we contend that meaningful change will require not only new metrics or better tooling, but a fundamental reframing of what recommender systems research is for, who it serves, and how knowledge is produced and validated. Our call is not just for technical reform, but for a recommender systems research agenda grounded in epistemic humility, human impact, and sustainable practice.
Soundtracks of Our Lives: How Age Influences Musical Preferences
Sep 10, 2025The majority of research in recommender systems, be it algorithmic improvements, context-awareness, explainability, or other areas, evaluates these systems on datasets that capture user interaction over a relatively limited time span. However, recommender systems can very well be used continuously for extended time. Similarly so, user behavior may evolve over that extended time. Although media studies and psychology offer a wealth of research on the evolution of user preferences and behavior as individuals age, there has been scant research in this regard within the realm of user modeling and recommender systems. In this study, we investigate the evolution of user preferences and behavior using the LFM-2b dataset, which, to our knowledge, is the only dataset that encompasses a sufficiently extensive time frame to permit real longitudinal studies and includes age information about its users. We identify specific usage and taste preferences directly related to the age of the user, i.e., while younger users tend to listen broadly to contemporary popular music, older users have more elaborate and personalized listening habits. The findings yield important insights that open new directions for research in recommender systems, providing guidance for future efforts.
The Hidden Cost of Defaults in Recommender System Evaluation
Aug 28, 2025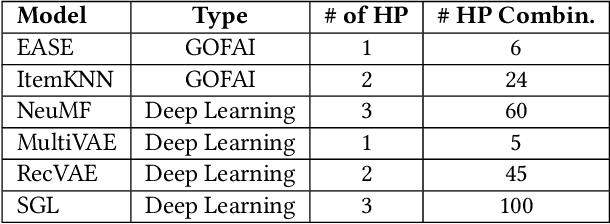

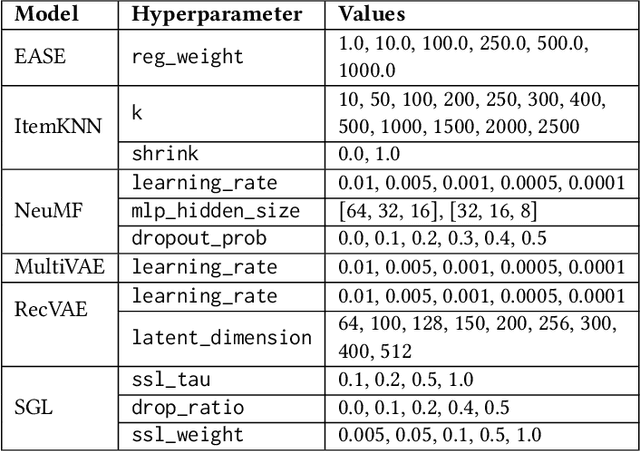

Hyperparameter optimization is critical for improving the performance of recommender systems, yet its implementation is often treated as a neutral or secondary concern. In this work, we shift focus from model benchmarking to auditing the behavior of RecBole, a widely used recommendation framework. We show that RecBole's internal defaults, particularly an undocumented early-stopping policy, can prematurely terminate Random Search and Bayesian Optimization. This limits search coverage in ways that are not visible to users. Using six models and two datasets, we compare search strategies and quantify both performance variance and search path instability. Our findings reveal that hidden framework logic can introduce variability comparable to the differences between search strategies. These results highlight the importance of treating frameworks as active components of experimental design and call for more transparent, reproducibility-aware tooling in recommender systems research. We provide actionable recommendations for researchers and developers to mitigate hidden configuration behaviors and improve the transparency of hyperparameter tuning workflows.
Early Explorations of Recommender Systems for Physical Activity and Well-being
Aug 11, 2025
As recommender systems increasingly guide physical actions, often through wearables and coaching tools, new challenges arise around how users interpret, trust, and respond to this advice. This paper introduces a conceptual framework for tangible recommendations that influence users' bodies, routines, and well-being. We describe three design dimensions: trust and interpretation, intent alignment, and consequence awareness. These highlight key limitations in applying conventional recommender logic to embodied settings. Through examples and design reflections, we outline how future systems can support long-term well-being, behavioral alignment, and socially responsible personalization.
On the Reliability of Sampling Strategies in Offline Recommender Evaluation
Aug 07, 2025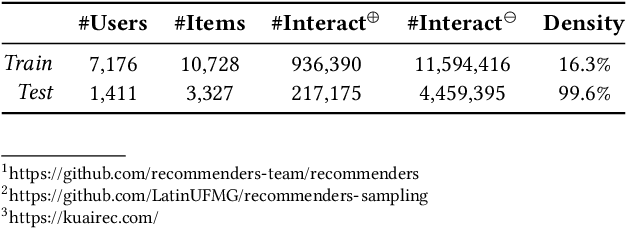



Offline evaluation plays a central role in benchmarking recommender systems when online testing is impractical or risky. However, it is susceptible to two key sources of bias: exposure bias, where users only interact with items they are shown, and sampling bias, introduced when evaluation is performed on a subset of logged items rather than the full catalog. While prior work has proposed methods to mitigate sampling bias, these are typically assessed on fixed logged datasets rather than for their ability to support reliable model comparisons under varying exposure conditions or relative to true user preferences. In this paper, we investigate how different combinations of logging and sampling choices affect the reliability of offline evaluation. Using a fully observed dataset as ground truth, we systematically simulate diverse exposure biases and assess the reliability of common sampling strategies along four dimensions: sampling resolution (recommender model separability), fidelity (agreement with full evaluation), robustness (stability under exposure bias), and predictive power (alignment with ground truth). Our findings highlight when and how sampling distorts evaluation outcomes and offer practical guidance for selecting strategies that yield faithful and robust offline comparisons.
Tell Me the Good Stuff: User Preferences in Movie Recommendation Explanations
May 06, 2025Recommender systems play a vital role in helping users discover content in streaming services, but their effectiveness depends on users understanding why items are recommended. In this study, explanations were based solely on item features rather than personalized data, simulating recommendation scenarios. We compared user perceptions of one-sided (purely positive) and two-sided (positive and negative) feature-based explanations for popular movie recommendations. Through an online study with 129 participants, we examined how explanation style affected perceived trust, transparency, effectiveness, and satisfaction. One-sided explanations consistently received higher ratings across all dimensions. Our findings suggest that in low-stakes entertainment domains such as popular movie recommendations, simpler positive explanations may be more effective. However, the results should be interpreted with caution due to potential confounding factors such as item familiarity and the placement of negative information in explanations. This work provides practical insights for explanation design in recommender interfaces and highlights the importance of context in shaping user preferences.
Recommender Systems for Social Good: The Role of Accountability and Sustainability
Jan 10, 2025This work examines the role of recommender systems in promoting sustainability, social responsibility, and accountability, with a focus on alignment with the United Nations Sustainable Development Goals (SDGs). As recommender systems become increasingly integrated into daily interactions, they must go beyond personalization to support responsible consumption, reduce environmental impact, and foster social good. We explore strategies to mitigate the carbon footprint of recommendation models, ensure fairness, and implement accountability mechanisms. By adopting these approaches, recommender systems can contribute to sustainable and socially beneficial outcomes, aligning technological advancements with the SDGs focused on environmental sustainability and social well-being.
A Review of LLM-based Explanations in Recommender Systems
Nov 29, 2024The rise of Large Language Models (LLMs), such as LLaMA and ChatGPT, has opened new opportunities for enhancing recommender systems through improved explainability. This paper provides a systematic literature review focused on leveraging LLMs to generate explanations for recommendations -- a critical aspect for fostering transparency and user trust. We conducted a comprehensive search within the ACM Guide to Computing Literature, covering publications from the launch of ChatGPT (November 2022) to the present (November 2024). Our search yielded 232 articles, but after applying inclusion criteria, only six were identified as directly addressing the use of LLMs in explaining recommendations. This scarcity highlights that, despite the rise of LLMs, their application in explainable recommender systems is still in an early stage. We analyze these select studies to understand current methodologies, identify challenges, and suggest directions for future research. Our findings underscore the potential of LLMs improving explanations of recommender systems and encourage the development of more transparent and user-centric recommendation explanation solutions.
Recommender Systems for Good (RS4Good): Survey of Use Cases and a Call to Action for Research that Matters
Nov 25, 2024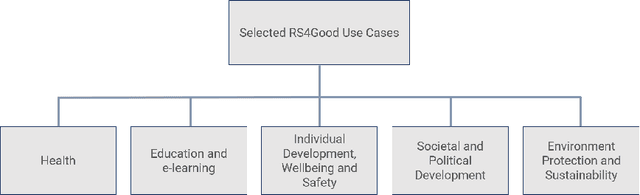

In the area of recommender systems, the vast majority of research efforts is spent on developing increasingly sophisticated recommendation models, also using increasingly more computational resources. Unfortunately, most of these research efforts target a very small set of application domains, mostly e-commerce and media recommendation. Furthermore, many of these models are never evaluated with users, let alone put into practice. The scientific, economic and societal value of much of these efforts by scholars therefore remains largely unclear. To achieve a stronger positive impact resulting from these efforts, we posit that we as a research community should more often address use cases where recommender systems contribute to societal good (RS4Good). In this opinion piece, we first discuss a number of examples where the use of recommender systems for problems of societal concern has been successfully explored in the literature. We then proceed by outlining a paradigmatic shift that is needed to conduct successful RS4Good research, where the key ingredients are interdisciplinary collaborations and longitudinal evaluation approaches with humans in the loop.