 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Recommender Systems: Understanding and Minimizing the Carbon Footprint of AI-Powered Personalization
Sep 16, 2025As global warming soars, the need to assess and reduce the environmental impact of recommender systems is becoming increasingly urgent. Despite this, the recommender systems community hardly understands, addresses, and evaluates the environmental impact of their work. In this study, we examine the environmental impact of recommender systems research by reproducing typical experimental pipelines. Based on our results, we provide guidelines for researchers and practitioners on how to minimize the environmental footprint of their work and implement green recommender systems - recommender systems designed to minimize their energy consumption and carbon footprint. Our analysis covers 79 papers from the 2013 and 2023 ACM RecSys conferences, comparing traditional "good old-fashioned AI" models with modern deep learning models. We designed and reproduced representative experimental pipelines for both years, measuring energy consumption using a hardware energy meter and converting it into CO2 equivalents. Our results show that papers utilizing deep learning models emit approximately 42 times more CO2 equivalents than papers using traditional models. On average, a single deep learning-based paper generates 2,909 kilograms of CO2 equivalents - more than the carbon emissions of a person flying from New York City to Melbourne or the amount of CO2 sequestered by one tree over 260 years. This work underscores the urgent need for the recommender systems and wider machine learning communities to adopt green AI principles, balancing algorithmic advancements and environmental responsibility to build a sustainable future with AI-powered personalization.
e-Fold Cross-Validation for Recommender-System Evaluation
Dec 02, 2024To combat the rising energy consumption of recommender systems we implement a novel alternative for k-fold cross validation. This alternative, named e-fold cross validation, aims to minimize the number of folds to achieve a reduction in power usage while keeping the reliability and robustness of the test results high. We tested our method on 5 recommender system algorithms across 6 datasets and compared it with 10-fold cross validation. On average e-fold cross validation only needed 41.5% of the energy that 10-fold cross validation would need, while it's results only differed by 1.81%. We conclude that e-fold cross validation is a promising approach that has the potential to be an energy efficient but still reliable alternative to k-fold cross validation.
Recommender Systems Algorithm Selection for Ranking Prediction on Implicit Feedback Datasets
Sep 09, 2024The recommender systems algorithm selection problem for ranking prediction on implicit feedback datasets is under-explored. Traditional approaches in recommender systems algorithm selection focus predominantly on rating prediction on explicit feedback datasets, leaving a research gap for ranking prediction on implicit feedback datasets. Algorithm selection is a critical challenge for nearly every practitioner in recommender systems. In this work, we take the first steps toward addressing this research gap. We evaluate the NDCG@10 of 24 recommender systems algorithms, each with two hyperparameter configurations, on 72 recommender systems datasets. We train four optimized machine-learning meta-models and one automated machine-learning meta-model with three different settings on the resulting meta-dataset. Our results show that the predictions of all tested meta-models exhibit a median Spearman correlation ranging from 0.857 to 0.918 with the ground truth. We show that the median Spearman correlation between meta-model predictions and the ground truth increases by an average of 0.124 when the meta-model is optimized to predict the ranking of algorithms instead of their performance. Furthermore, in terms of predicting the best algorithm for an unknown dataset, we demonstrate that the best optimized traditional meta-model, e.g., XGBoost, achieves a recall of 48.6%, outperforming the best tested automated machine learning meta-model, e.g., AutoGluon, which achieves a recall of 47.2%.
From Clicks to Carbon: The Environmental Toll of Recommender Systems
Aug 15, 2024As global warming soars, evaluating the environmental impact of research is more critical now than ever before. However, we find that few to no recommender systems research papers document their impact on the environment. Consequently, in this paper, we conduct a comprehensive analysis of the environmental impact of recommender system research by reproducing a characteristic recommender systems experimental pipeline. We focus on estimating the carbon footprint of recommender systems research papers, highlighting the evolution of the environmental impact of recommender systems research experiments over time. We thoroughly evaluated all 79 full papers from the ACM RecSys conference in the years 2013 and 2023 to analyze representative experimental pipelines for papers utilizing traditional, so-called good old-fashioned AI algorithms and deep learning algorithms, respectively. We reproduced these representative experimental pipelines, measured electricity consumption using a hardware energy meter, and converted the measured energy consumption into CO2 equivalents to estimate the environmental impact. Our results show that a recommender systems research paper utilizing deep learning algorithms emits approximately 42 times more CO2 equivalents than a paper utilizing traditional algorithms. Furthermore, on average, such a paper produces 3,297 kilograms of CO2 equivalents, which is more than one person produces by flying from New York City to Melbourne or the amount one tree sequesters in 300 years.
Revealing the Hidden Impact of Top-N Metrics on Optimization in Recommender Systems
Jan 16, 2024The hyperparameters of recommender systems for top-n predictions are typically optimized to enhance the predictive performance of algorithms. Thereby, the optimization algorithm, e.g., grid search or random search, searches for the best hyperparameter configuration according to an optimization-target metric, like nDCG or Precision. In contrast, the optimized algorithm, internally optimizes a different loss function during training, like squared error or cross-entropy. To tackle this discrepancy, recent work focused on generating loss functions better suited for recommender systems. Yet, when evaluating an algorithm using a top-n metric during optimization, another discrepancy between the optimization-target metric and the training loss has so far been ignored. During optimization, the top-n items are selected for computing a top-n metric; ignoring that the top-n items are selected from the recommendations of a model trained with an entirely different loss function. Item recommendations suitable for optimization-target metrics could be outside the top-n recommended items; hiddenly impacting the optimization performance. Therefore, we were motivated to analyze whether the top-n items are optimal for optimization-target top-n metrics. In pursuit of an answer, we exhaustively evaluate the predictive performance of 250 selection strategies besides selecting the top-n. We extensively evaluate each selection strategy over twelve implicit feedback and eight explicit feedback data sets with eleven recommender systems algorithms. Our results show that there exist selection strategies other than top-n that increase predictive performance for various algorithms and recommendation domains. However, the performance of the top ~43% of selection strategies is not significantly different. We discuss the impact of our findings on optimization and re-ranking in recommender systems and feasible solutions.
The Impact of Feature Quantity on Recommendation Algorithm Performance: A Movielens-100K Case Study
Jul 13, 2022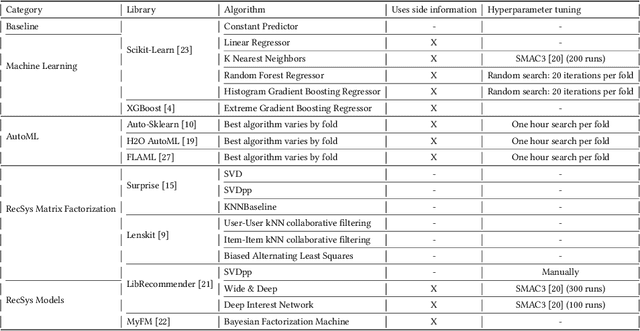
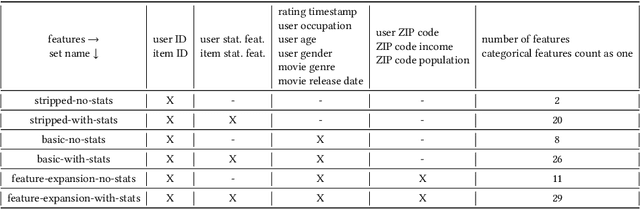
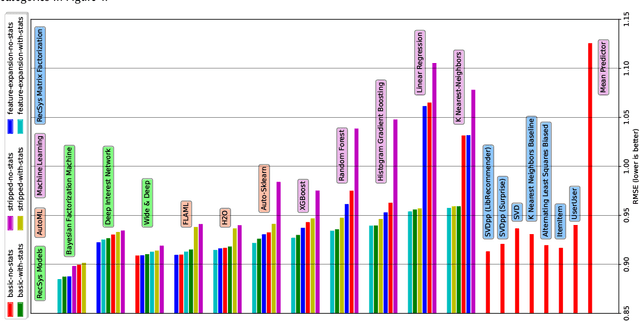
Recent model-based Recommender Systems (RecSys) algorithms emphasize on the use of features, also called side information, in their design similar to algorithms in Machine Learning (ML). In contrast, some of the most popular and traditional algorithms for RecSys solely focus on a given user-item-rating relation without including side information. The goal of this case study is to provide a performance comparison and assessment of RecSys and ML algorithms when side information is included. We chose the Movielens-100K data set since it is a standard for comparing RecSys algorithms. We compared six different feature sets with varying quantities of features which were generated from the baseline data and evaluated on a total of 19 RecSys algorithms, baseline ML algorithms, Automated Machine Learning (AutoML) pipelines, and state-of-the-art RecSys algorithms that incorporate side information. The results show that additional features benefit all algorithms we evaluated. However, the correlation between feature quantity and performance is not monotonous for AutoML and RecSys. In these categories, an analysis of feature importance revealed that the quality of features matters more than quantity. Throughout our experiments, the average performance on the feature set with the lowest number of features is about 6% worse compared to that with the highest in terms of the Root Mean Squared Error. An interesting observation is that AutoML outperforms matrix factorization-based RecSys algorithms when additional features are used. Almost all algorithms that can include side information have higher performance when using the highest quantity of features. In the other cases, the performance difference is negligible (<1%). The results show a clear positive trend for the effect of feature quantity as well as the important effects of feature quality on the evaluated algorithms.
Detecting Handwritten Mathematical Terms with Sensor Based Data
Sep 12, 2021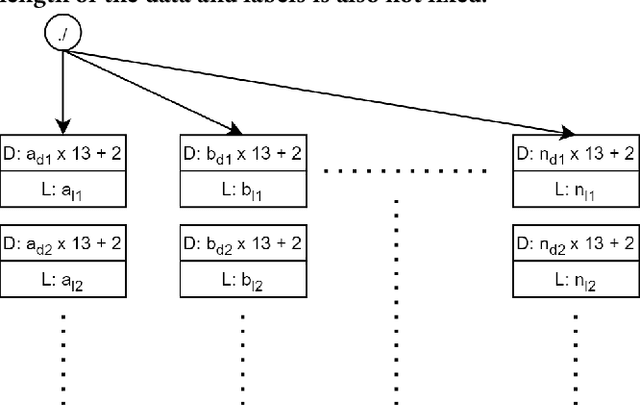
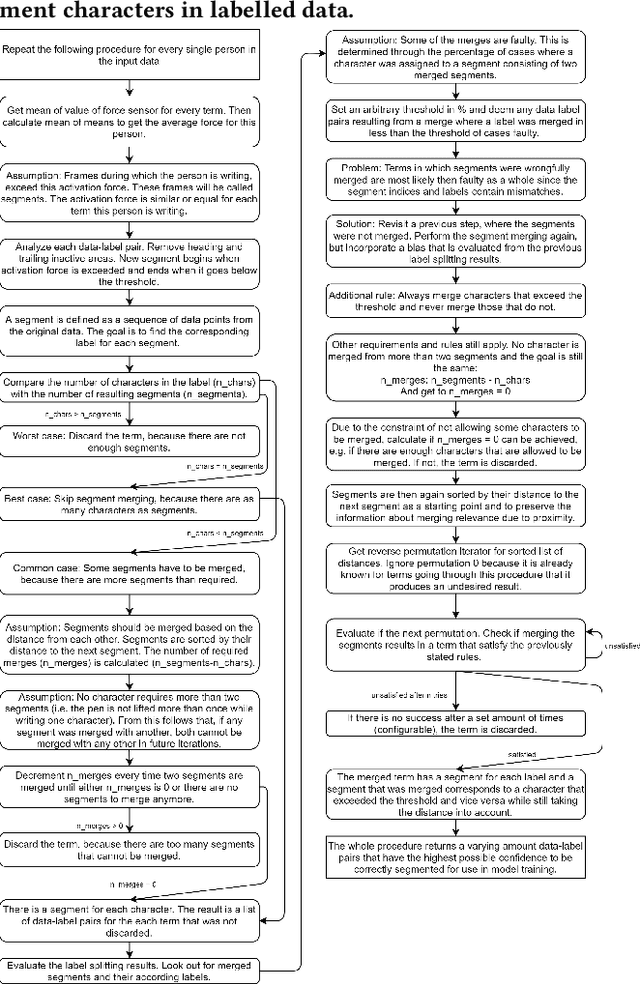
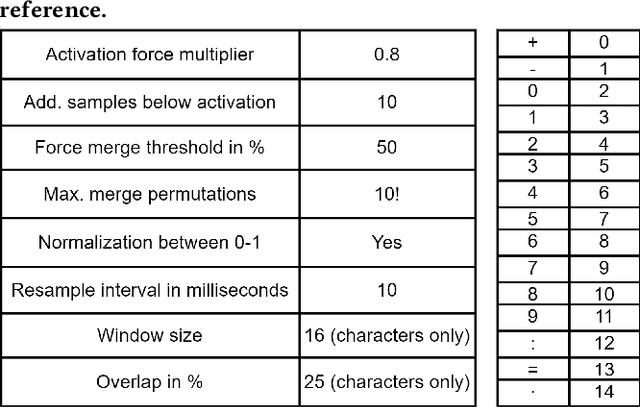
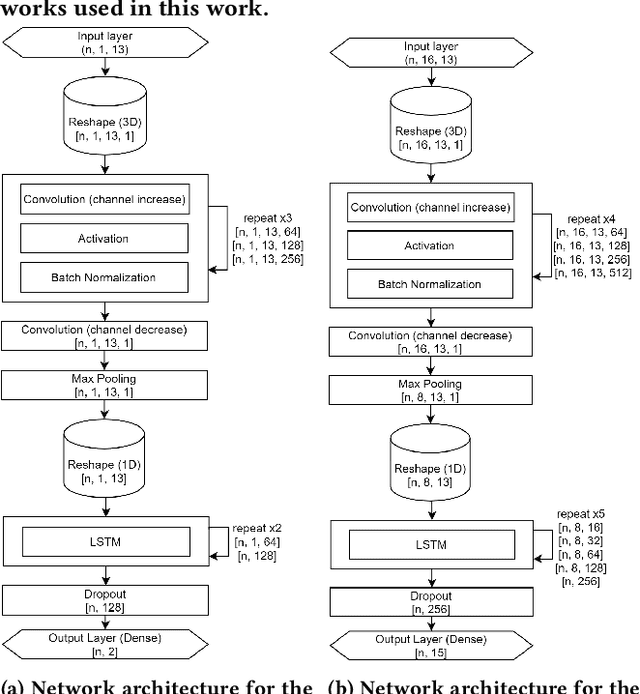
In this work we propose a solution to the UbiComp 2021 Challenge by Stabilo in which handwritten mathematical terms are supposed to be automatically classified based on time series sensor data captured on the DigiPen. The input data set contains data of different writers, with label strings constructed from a total of 15 different possible characters. The label should first be split into separate characters to classify them one by one. This issue is solved by applying a data-dependant and rule-based information extraction algorithm to the labeled data. Using the resulting data, two classifiers are constructed. The first is a binary classifier that is able to predict, for unknown data, if a sample is part of a writing activity, and consists of a Deep Neural Network feature extractor in concatenation with a Random Forest that is trained to classify the extracted features at an F1 score of >90%. The second classifier is a Deep Neural Network that combines convolution layers with recurrent layers to predict windows with a single label, out of the 15 possible classes, at an F1 score of >60%. A simulation of the challenge evaluation procedure reports a Levensthein Distance of 8 and shows that the chosen approach still lacks in overall accuracy and real-time applicability.