 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHang-Time HAR: A Benchmark Dataset for Basketball Activity Recognition using Wrist-worn Inertial Sensors
May 22, 2023



We present a benchmark dataset for evaluating physical human activity recognition methods from wrist-worn sensors, for the specific setting of basketball training, drills, and games. Basketball activities lend themselves well for measurement by wrist-worn inertial sensors, and systems that are able to detect such sport-relevant activities could be used in applications toward game analysis, guided training, and personal physical activity tracking. The dataset was recorded for two teams from separate countries (USA and Germany) with a total of 24 players who wore an inertial sensor on their wrist, during both repetitive basketball training sessions and full games. Particular features of this dataset include an inherent variance through cultural differences in game rules and styles as the data was recorded in two countries, as well as different sport skill levels, since the participants were heterogeneous in terms of prior basketball experience. We illustrate the dataset's features in several time-series analyses and report on a baseline classification performance study with two state-of-the-art deep learning architectures.
A Matter of Annotation: An Empirical Study on In Situ and Self-Recall Activity Annotations from Wearable Sensors
May 15, 2023



Research into the detection of human activities from wearable sensors is a highly active field, benefiting numerous applications, from ambulatory monitoring of healthcare patients via fitness coaching to streamlining manual work processes. We present an empirical study that compares 4 different commonly used annotation methods utilized in user studies that focus on in-the-wild data. These methods can be grouped in user-driven, in situ annotations - which are performed before or during the activity is recorded - and recall methods - where participants annotate their data in hindsight at the end of the day. Our study illustrates that different labeling methodologies directly impact the annotations' quality, as well as the capabilities of a deep learning classifier trained with the data respectively. We noticed that in situ methods produce less but more precise labels than recall methods. Furthermore, we combined an activity diary with a visualization tool that enables the participant to inspect and label their activity data. Due to the introduction of such a tool were able to decrease missing annotations and increase the annotation consistency, and therefore the F1-score of the deep learning model by up to 8% (ranging between 82.1 and 90.4% F1-score). Furthermore, we discuss the advantages and disadvantages of the methods compared in our study, the biases they may could introduce and the consequences of their usage on human activity recognition studies and as well as possible solutions.
Tutorial on Deep Learning for Human Activity Recognition
Oct 13, 2021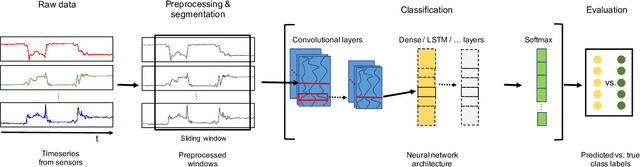
Activity recognition systems that are capable of estimating human activities from wearable inertial sensors have come a long way in the past decades. Not only have state-of-the-art methods moved away from feature engineering and have fully adopted end-to-end deep learning approaches, best practices for setting up experiments, preparing datasets, and validating activity recognition approaches have similarly evolved. This tutorial was first held at the 2021 ACM International Symposium on Wearable Computers (ISWC'21) and International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp'21). The tutorial, after a short introduction in the research field of activity recognition, provides a hands-on and interactive walk-through of the most important steps in the data pipeline for the deep learning of human activities. All presentation slides shown during the tutorial, which also contain links to all code exercises, as well as the link of the GitHub page of the tutorial can be found on: https://mariusbock.github.io/dl-for-har
Detecting Handwritten Mathematical Terms with Sensor Based Data
Sep 12, 2021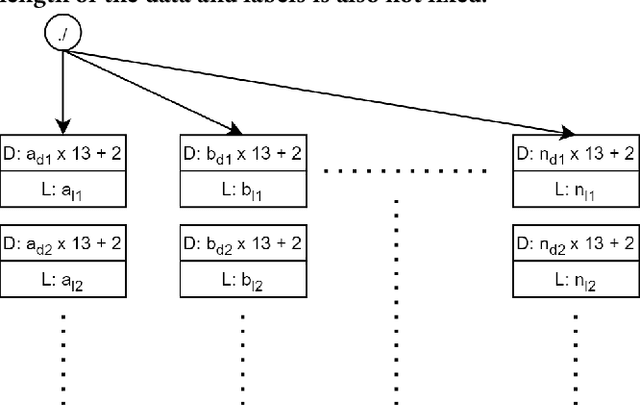
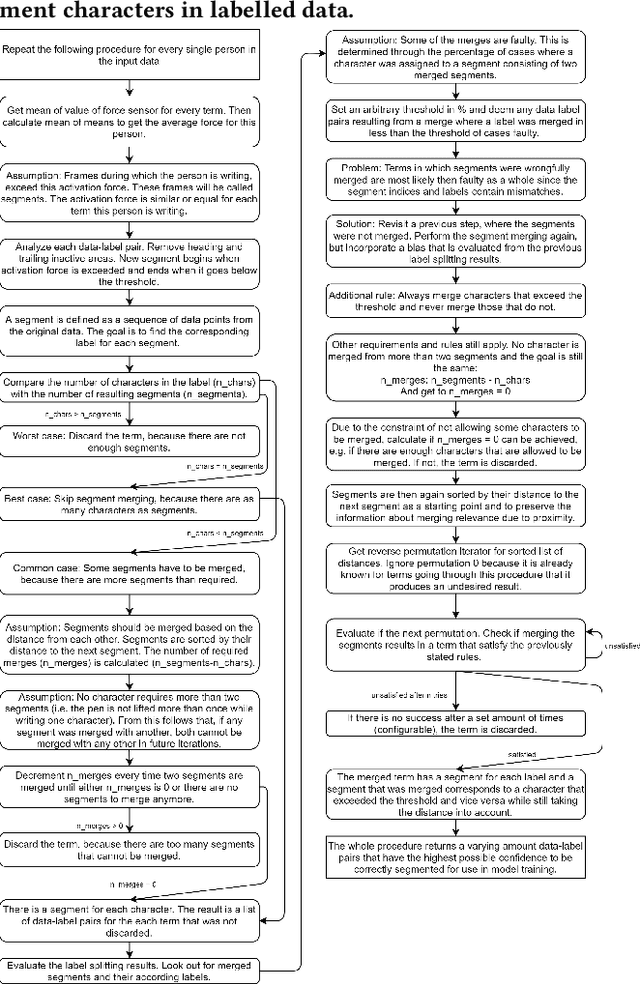
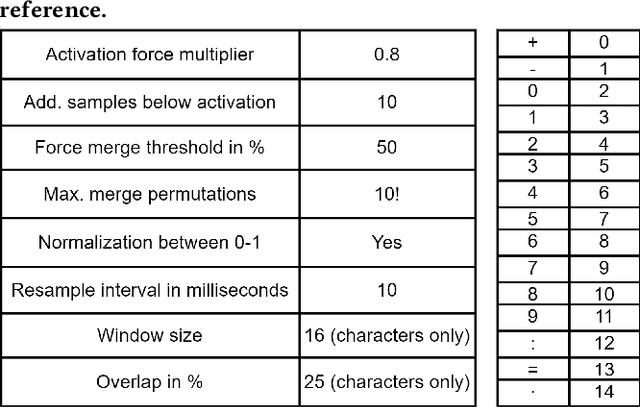
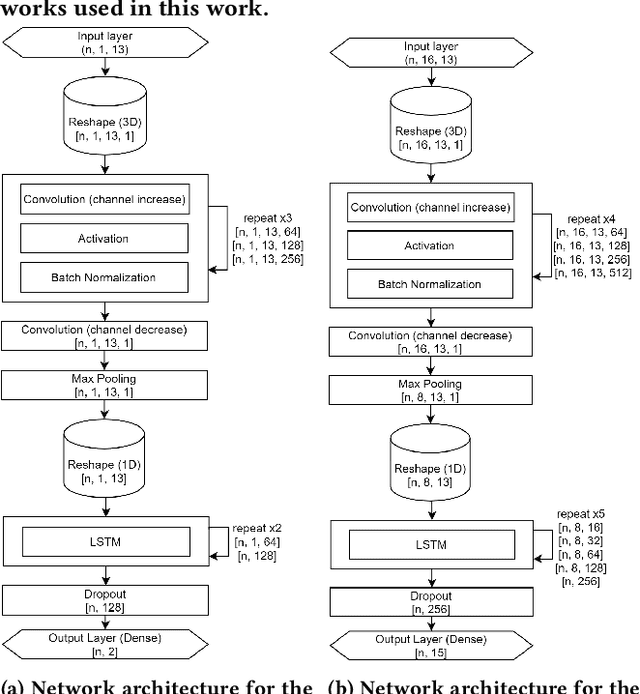
In this work we propose a solution to the UbiComp 2021 Challenge by Stabilo in which handwritten mathematical terms are supposed to be automatically classified based on time series sensor data captured on the DigiPen. The input data set contains data of different writers, with label strings constructed from a total of 15 different possible characters. The label should first be split into separate characters to classify them one by one. This issue is solved by applying a data-dependant and rule-based information extraction algorithm to the labeled data. Using the resulting data, two classifiers are constructed. The first is a binary classifier that is able to predict, for unknown data, if a sample is part of a writing activity, and consists of a Deep Neural Network feature extractor in concatenation with a Random Forest that is trained to classify the extracted features at an F1 score of >90%. The second classifier is a Deep Neural Network that combines convolution layers with recurrent layers to predict windows with a single label, out of the 15 possible classes, at an F1 score of >60%. A simulation of the challenge evaluation procedure reports a Levensthein Distance of 8 and shows that the chosen approach still lacks in overall accuracy and real-time applicability.
Transformer Networks for Data Augmentation of Human Physical Activity Recognition
Sep 04, 2021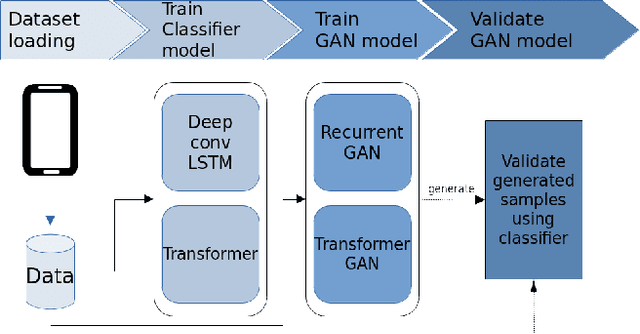
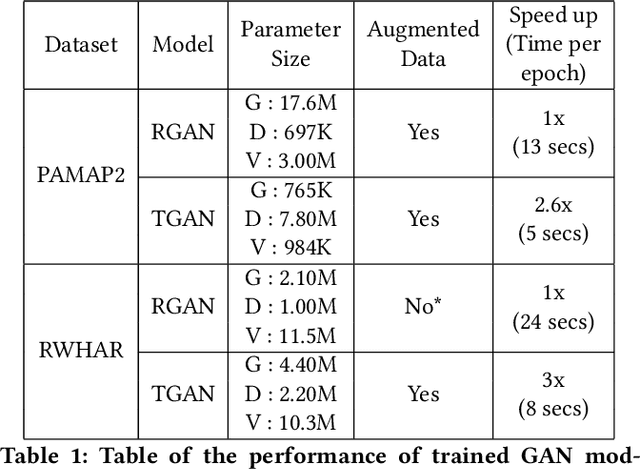


Data augmentation is a widely used technique in classification to increase data used in training. It improves generalization and reduces amount of annotated human activity data needed for training which reduces labour and time needed with the dataset. Sensor time-series data, unlike images, cannot be augmented by computationally simple transformation algorithms. State of the art models like Recurrent Generative Adversarial Networks (RGAN) are used to generate realistic synthetic data. In this paper, transformer based generative adversarial networks which have global attention on data, are compared on PAMAP2 and Real World Human Activity Recognition data sets with RGAN. The newer approach provides improvements in time and savings in computational resources needed for data augmentation than previous approach.
Improving Deep Learning for HAR with shallow LSTMs
Aug 05, 2021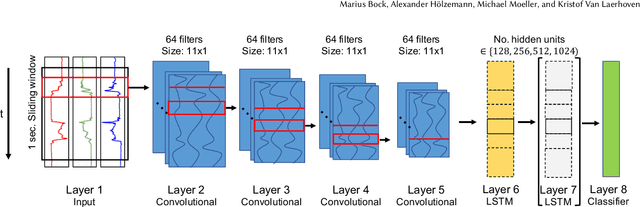
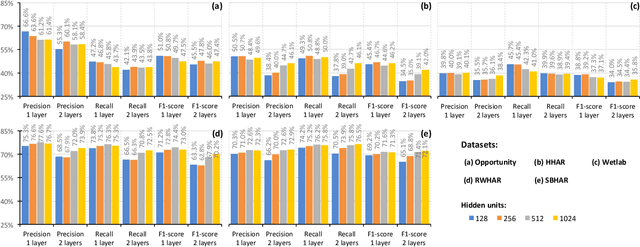
Recent studies in Human Activity Recognition (HAR) have shown that Deep Learning methods are able to outperform classical Machine Learning algorithms. One popular Deep Learning architecture in HAR is the DeepConvLSTM. In this paper we propose to alter the DeepConvLSTM architecture to employ a 1-layered instead of a 2-layered LSTM. We validate our architecture change on 5 publicly available HAR datasets by comparing the predictive performance with and without the change employing varying hidden units within the LSTM layer(s). Results show that across all datasets, our architecture consistently improves on the original one: Recognition performance increases up to 11.7% for the F1-score, and our architecture significantly decreases the amount of learnable parameters. This improvement over DeepConvLSTM decreases training time by as much as 48%. Our results stand in contrast to the belief that one needs at least a 2-layered LSTM when dealing with sequential data. Based on our results we argue that said claim might not be applicable to sensor-based HAR.