 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye-Tracking-Driven Control in Daily Task Assistance for Assistive Robotic Arms
Jan 24, 2026Shared control improves Human-Robot Interaction by reducing the user's workload and increasing the robot's autonomy. It allows robots to perform tasks under the user's supervision. Current eye-tracking-driven approaches face several challenges. These include accuracy issues in 3D gaze estimation and difficulty interpreting gaze when differentiating between multiple tasks. We present an eye-tracking-driven control framework, aimed at enabling individuals with severe physical disabilities to perform daily tasks independently. Our system uses task pictograms as fiducial markers combined with a feature matching approach that transmits data of the selected object to accomplish necessary task related measurements with an eye-in-hand configuration. This eye-tracking control does not require knowledge of the user's position in relation to the object. The framework correctly interpreted object and task selection in up to 97.9% of measurements. Issues were found in the evaluation, that were improved and shared as lessons learned. The open-source framework can be adapted to new tasks and objects due to the integration of state-of-the-art object detection models.
Environment-Aware Indoor LoRaWAN Path Loss: Parametric Regression Comparisons, Shadow Fading, and Calibrated Fade Margins
Oct 05, 2025Indoor LoRaWAN propagation is shaped by structural and time-varying context factors, which challenge log-distance models and the assumption of log-normal shadowing. We present an environment-aware, statistically disciplined path loss framework evaluated using leakage-safe cross-validation on a 12-month campaign in an eighth-floor office measuring 240 m^2. A log-distance multi-wall mean is augmented with environmental covariates (relative humidity, temperature, carbon dioxide, particulate matter, and barometric pressure), as well as the signal-to-noise ratio. We compare multiple linear regression with regularized variants, Bayesian linear regression, and a selective second-order polynomial applied to continuous drivers. Predictor relevance is established using heteroscedasticity-robust Type II and III analysis of variance and nested partial F tests. Shadow fading is profiled with kernel density estimation and non-parametric families, including Normal, Skew-Normal, Student's t, and Gaussian mixtures. The polynomial mean reduces cross-validated RMSE from 8.07 to 7.09 dB and raises R^2 from 0.81 to 0.86. Out-of-fold residuals are non-Gaussian; a 3-component mixture captures a sharp core with a light, broad tail. We convert accuracy into reliability by prescribing the fade margin as the upper-tail quantile of cross-validated residuals, quantifying uncertainty via a moving-block bootstrap, and validating on a held-out set. At 99% packet delivery ratio, the environment-aware polynomial requires 25.7 dB versus 27.7 to 27.9 dB for linear baselines. This result presents a deployment-ready, interpretable workflow with calibrated reliability control for indoor Internet of Things planning, aligned with 6G targets.
$γ$-Quant: Towards Learnable Quantization for Low-bit Pattern Recognition
Sep 26, 2025Most pattern recognition models are developed on pre-proce\-ssed data. In computer vision, for instance, RGB images processed through image signal processing (ISP) pipelines designed to cater to human perception are the most frequent input to image analysis networks. However, many modern vision tasks operate without a human in the loop, raising the question of whether such pre-processing is optimal for automated analysis. Similarly, human activity recognition (HAR) on body-worn sensor data commonly takes normalized floating-point data arising from a high-bit analog-to-digital converter (ADC) as an input, despite such an approach being highly inefficient in terms of data transmission, significantly affecting the battery life of wearable devices. In this work, we target low-bandwidth and energy-constrained settings where sensors are limited to low-bit-depth capture. We propose $\gamma$-Quant, i.e.~the task-specific learning of a non-linear quantization for pattern recognition. We exemplify our approach on raw-image object detection as well as HAR of wearable data, and demonstrate that raw data with a learnable quantization using as few as 4-bits can perform on par with the use of raw 12-bit data. All code to reproduce our experiments is publicly available via https://github.com/Mishalfatima/Gamma-Quant
SRWToolkit: An Open Source Wizard of Oz Toolkit to Create Social Robotic Avatars
Sep 04, 2025We present SRWToolkit, an open-source Wizard of Oz toolkit designed to facilitate the rapid prototyping of social robotic avatars powered by local large language models (LLMs). Our web-based toolkit enables multimodal interaction through text input, button-activated speech, and wake-word command. The toolkit offers real-time configuration of avatar appearance, behavior, language, and voice via an intuitive control panel. In contrast to prior works that rely on cloud-based LLM services, SRWToolkit emphasizes modularity and ensures on-device functionality through local LLM inference. In our small-scale user study ($n=11$), participants created and interacted with diverse robotic roles (hospital receptionist, mathematics teacher, and driving assistant), which demonstrated positive outcomes in the toolkit's usability, trust, and user experience. The toolkit enables rapid and efficient development of robot characters customized to researchers' needs, supporting scalable research in human-robot interaction.
Privacy Perceptions in Robot-Assisted Well-Being Coaching: Examining the Roles of Information Transparency, User Control, and Proactivity
Sep 04, 2025Social robots are increasingly recognized as valuable supporters in the field of well-being coaching. They can function as independent coaches or provide support alongside human coaches, and healthcare professionals. In coaching interactions, these robots often handle sensitive information shared by users, making privacy a relevant issue. Despite this, little is known about the factors that shape users' privacy perceptions. This research aims to examine three key factors systematically: (1) the transparency about information usage, (2) the level of specific user control over how the robot uses their information, and (3) the robot's behavioral approach - whether it acts proactively or only responds on demand. Our results from an online study (N = 200) show that even when users grant the robot general access to personal data, they additionally expect the ability to explicitly control how that information is interpreted and shared during sessions. Experimental conditions that provided such control received significantly higher ratings for perceived privacy appropriateness and trust. Compared to user control, the effects of transparency and proactivity on privacy appropriateness perception were low, and we found no significant impact. The results suggest that merely informing users or proactive sharing is insufficient without accompanying user control. These insights underscore the need for further research on mechanisms that allow users to manage robots' information processing and sharing, especially when social robots take on more proactive roles alongside humans.
Eye-tracking-Driven Shared Control for Robotic Arms:Wizard of Oz Studies to Assess Design Choices
May 29, 2025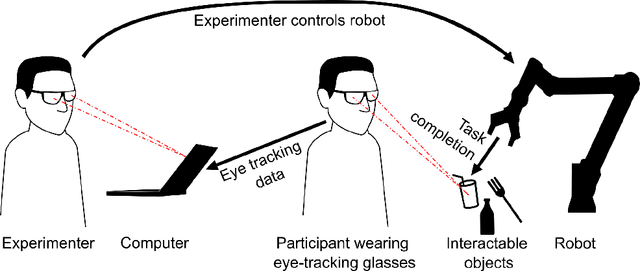
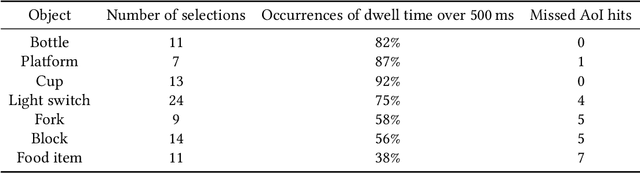


Advances in eye-tracking control for assistive robotic arms provide intuitive interaction opportunities for people with physical disabilities. Shared control has gained interest in recent years by improving user satisfaction through partial automation of robot control. We present an eye-tracking-guided shared control design based on insights from state-of-the-art literature. A Wizard of Oz setup was used in which automation was simulated by an experimenter to evaluate the concept without requiring full implementation. This approach allowed for rapid exploration of user needs and expectations to inform future iterations. Two studies were conducted to assess user experience, identify design challenges, and find improvements to ensure usability and accessibility. The first study involved people with disabilities by providing a survey, and the second study used the Wizard of Oz design in person to gain technical insights, leading to a comprehensive picture of findings.
Enhancing Wearable Tap Water Audio Detection through Subclass Annotation in the HD-Epic Dataset
May 27, 2025Wearable human activity recognition has been shown to benefit from the inclusion of acoustic data, as the sounds around a person often contain valuable context. However, due to privacy concerns, it is usually not ethically feasible to record and save microphone data from the device, since the audio could, for instance, also contain private conversations. Rather, the data should be processed locally, which in turn requires processing power and consumes energy on the wearable device. One special use case of contextual information that can be utilized to augment special tasks in human activity recognition is water flow detection, which can, e.g., be used to aid wearable hand washing detection. We created a new label called tap water for the recently released HD-Epic data set, creating 717 hand-labeled annotations of tap water flow, based on existing annotations of the water class. We analyzed the relation of tap water and water in the dataset and additionally trained and evaluated two lightweight classifiers to evaluate the newly added label class, showing that the new class can be learned more easily.
Label Leakage in Federated Inertial-based Human Activity Recognition
May 27, 2025



While prior work has shown that Federated Learning updates can leak sensitive information, label reconstruction attacks, which aim to recover input labels from shared gradients, have not yet been examined in the context of Human Activity Recognition (HAR). Given the sensitive nature of activity labels, this study evaluates the effectiveness of state-of-the-art gradient-based label leakage attacks on HAR benchmark datasets. Our findings show that the number of activity classes, sampling strategy, and class imbalance are critical factors influencing the extent of label leakage, with reconstruction accuracies reaching up to 90% on two benchmark datasets, even for trained models. Moreover, we find that Local Differential Privacy techniques such as gradient noise and clipping offer only limited protection, as certain attacks still reliably infer both majority and minority class labels. We conclude by offering practical recommendations for the privacy-aware deployment of federated HAR systems and identify open challenges for future research. Code to reproduce our experiments is publicly available via github.com/mariusbock/leakage_har.
DeepConvContext: A Multi-Scale Approach to Timeseries Classification in Human Activity Recognition
May 27, 2025Despite recognized limitations in modeling long-range temporal dependencies, Human Activity Recognition (HAR) has traditionally relied on a sliding window approach to segment labeled datasets. Deep learning models like the DeepConvLSTM typically classify each window independently, thereby restricting learnable temporal context to within-window information. To address this constraint, we propose DeepConvContext, a multi-scale time series classification framework for HAR. Drawing inspiration from the vision-based Temporal Action Localization community, DeepConvContext models both intra- and inter-window temporal patterns by processing sequences of time-ordered windows. Unlike recent HAR models that incorporate attention mechanisms, DeepConvContext relies solely on LSTMs -- with ablation studies demonstrating the superior performance of LSTMs over attention-based variants for modeling inertial sensor data. Across six widely-used HAR benchmarks, DeepConvContext achieves an average 10% improvement in F1-score over the classic DeepConvLSTM, with gains of up to 21%. Code to reproduce our experiments is publicly available via github.com/mariusbock/context_har.
A Comprehensive Data Description for LoRaWAN Path Loss Measurements in an Indoor Office Setting: Effects of Environmental Factors
May 09, 2025This paper presents a comprehensive dataset of LoRaWAN technology path loss measurements collected in an indoor office environment, focusing on quantifying the effects of environmental factors on signal propagation. Utilizing a network of six strategically placed LoRaWAN end devices (EDs) and a single indoor gateway (GW) at the University of Siegen, City of Siegen, Germany, we systematically measured signal strength indicators such as the Received Signal Strength Indicator (RSSI) and the Signal-to-Noise Ratio (SNR) under various environmental conditions, including temperature, relative humidity, carbon dioxide (CO$_2$) concentration, barometric pressure, and particulate matter levels (PM$_{2.5}$). Our empirical analysis confirms that transient phenomena such as reflections, scattering, interference, occupancy patterns (induced by environmental parameter variations), and furniture rearrangements can alter signal attenuation by as much as 10.58 dB, highlighting the dynamic nature of indoor propagation. As an example of how this dataset can be utilized, we tested and evaluated a refined Log-Distance Path Loss and Shadowing Model that integrates both structural obstructions (Multiple Walls) and Environmental Parameters (LDPLSM-MW-EP). Compared to a baseline model that considers only Multiple Walls (LDPLSM-MW), the enhanced approach reduced the root mean square error (RMSE) from 10.58 dB to 8.04 dB and increased the coefficient of determination (R$^2$) from 0.6917 to 0.8222. By capturing the extra effects of environmental conditions and occupancy dynamics, this improved model provides valuable insights for optimizing power usage and prolonging device battery life, enhancing network reliability in indoor Internet of Things (IoT) deployments, among other applications. This dataset offers a solid foundation for future research and development in indoor wireless communication.