 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Arena: A Dynamic Benchmark for Operational Energy Forecasting
Apr 27, 2026Energy forecasting research faces a persistent comparability gap that makes it difficult to measure consistent progress over time. Reported accuracy gains are often not directly comparable because models are evaluated under study-specific datasets, time periods, information sets, and scoring setups, while widely used benchmarks and competition datasets are typically tied to fixed historical windows. This paper introduces the Energy-Arena, a dynamic benchmarking platform for operational energy time series forecasting that provides a continuously updated reference point as energy systems evolve. The platform operates as an open, API-based submission system and standardizes challenge definitions and submission deadlines aligned with operational constraints. Performance is reported on rolling evaluation windows via persistent leaderboards. By moving from retrospective backtesting to forward-looking benchmarking, the Energy-Arena enforces standardized ex-ante submission and ex-post evaluation, thereby improving transparency by preventing information leakage and retroactive tuning. The platform is publicly available at Energy-Arena.org.
Data Synthesis Improves 3D Myotube Instance Segmentation
Apr 16, 2026Myotubes are multinucleated muscle fibers serving as key model systems for studying muscle physiology, disease mechanisms, and drug responses. Mechanistic studies and drug screening thereby rely on quantitative morphological readouts such as diameter, length, and branching degree, which in turn require precise three-dimensional instance segmentation. Yet established pretrained biomedical segmentation models fail to generalize to this domain due to the absence of large annotated myotube datasets. We introduce a geometry-driven synthesis pipeline that models individual myotubes via polynomial centerlines, locally varying radii, branching structures, and ellipsoidal end caps derived from real microscopy observations. Synthetic volumes are rendered with realistic noise, optical artifacts, and CycleGAN-based Domain Adaptation (DA). A compact 3D U-Net with self-supervised encoder pretraining, trained exclusively on synthetic data, achieves a mean IPQ of 0.22 on real data, significantly outperforming three established zero-shot segmentation models, demonstrating that biophysics-driven synthesis enables effective instance segmentation in annotation-scarce biomedical domains.
Explainable time-series forecasting with sampling-free SHAP for Transformers
Dec 23, 2025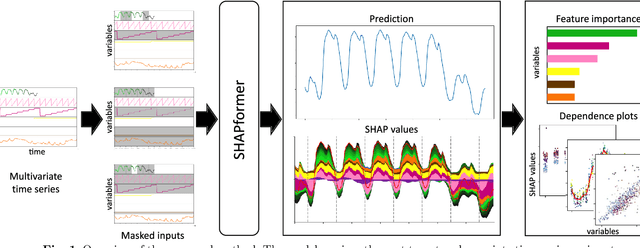
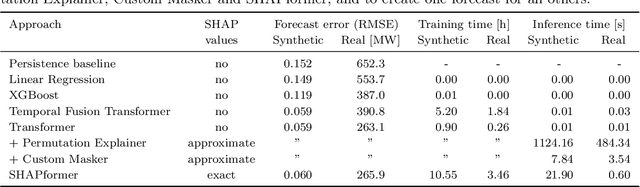
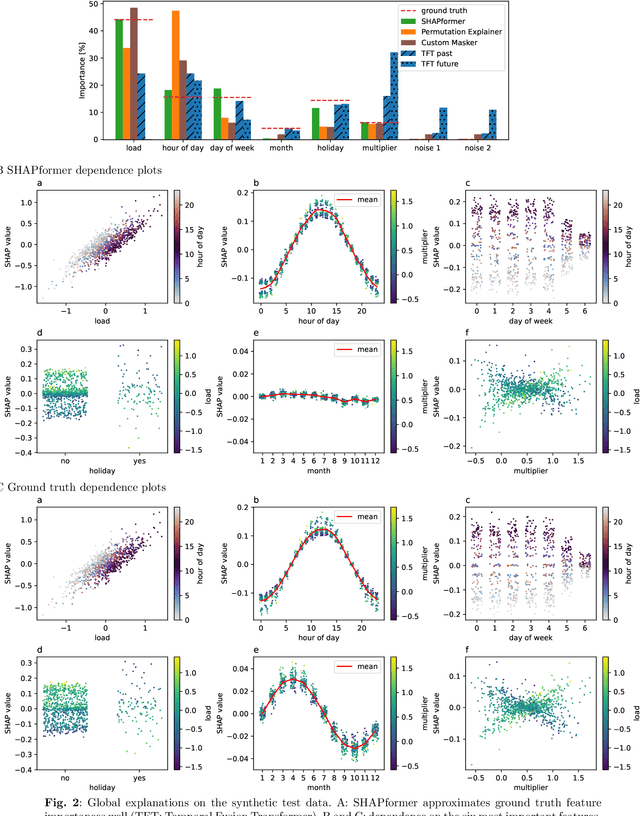
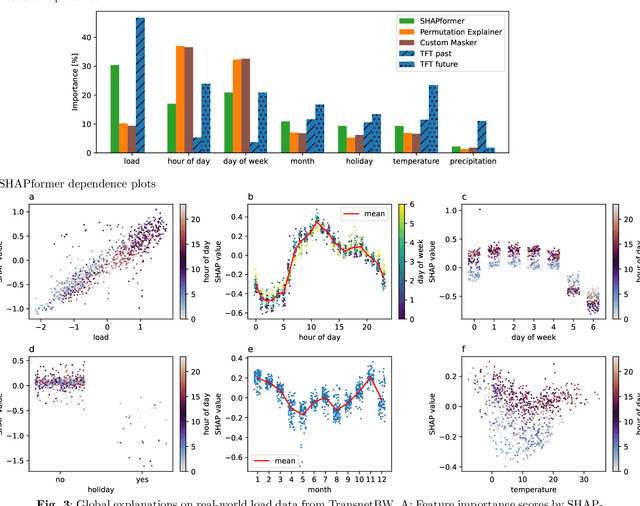
Time-series forecasts are essential for planning and decision-making in many domains. Explainability is key to building user trust and meeting transparency requirements. Shapley Additive Explanations (SHAP) is a popular explainable AI framework, but it lacks efficient implementations for time series and often assumes feature independence when sampling counterfactuals. We introduce SHAPformer, an accurate, fast and sampling-free explainable time-series forecasting model based on the Transformer architecture. It leverages attention manipulation to make predictions based on feature subsets. SHAPformer generates explanations in under one second, several orders of magnitude faster than the SHAP Permutation Explainer. On synthetic data with ground truth explanations, SHAPformer provides explanations that are true to the data. Applied to real-world electrical load data, it achieves competitive predictive performance and delivers meaningful local and global insights, such as identifying the past load as the key predictor and revealing a distinct model behavior during the Christmas period.
Self-Supervised Learning Strategies for a Platform to Test the Toxicity of New Chemicals and Materials
Oct 09, 2025High-throughput toxicity testing offers a fast and cost-effective way to test large amounts of compounds. A key component for such systems is the automated evaluation via machine learning models. In this paper, we address critical challenges in this domain and demonstrate how representations learned via self-supervised learning can effectively identify toxicant-induced changes. We provide a proof-of-concept that utilizes the publicly available EmbryoNet dataset, which contains ten zebrafish embryo phenotypes elicited by various chemical compounds targeting different processes in early embryonic development. Our analysis shows that the learned representations using self-supervised learning are suitable for effectively distinguishing between the modes-of-action of different compounds. Finally, we discuss the integration of machine learning models in a physical toxicity testing device in the context of the TOXBOX project.
LeDiFlow: Learned Distribution-guided Flow Matching to Accelerate Image Generation
May 27, 2025Enhancing the efficiency of high-quality image generation using Diffusion Models (DMs) is a significant challenge due to the iterative nature of the process. Flow Matching (FM) is emerging as a powerful generative modeling paradigm based on a simulation-free training objective instead of a score-based one used in DMs. Typical FM approaches rely on a Gaussian distribution prior, which induces curved, conditional probability paths between the prior and target data distribution. These curved paths pose a challenge for the Ordinary Differential Equation (ODE) solver, requiring a large number of inference calls to the flow prediction network. To address this issue, we present Learned Distribution-guided Flow Matching (LeDiFlow), a novel scalable method for training FM-based image generation models using a better-suited prior distribution learned via a regression-based auxiliary model. By initializing the ODE solver with a prior closer to the target data distribution, LeDiFlow enables the learning of more computationally tractable probability paths. These paths directly translate to fewer solver steps needed for high-quality image generation at inference time. Our method utilizes a State-Of-The-Art (SOTA) transformer architecture combined with latent space sampling and can be trained on a consumer workstation. We empirically demonstrate that LeDiFlow remarkably outperforms the respective FM baselines. For instance, when operating directly on pixels, our model accelerates inference by up to 3.75x compared to the corresponding pixel-space baseline. Simultaneously, our latent FM model enhances image quality on average by 1.32x in CLIP Maximum Mean Discrepancy (CMMD) metric against its respective baseline.
Rapid AI-based generation of coverage paths for dispensing applications
May 06, 2025

Coverage Path Planning of Thermal Interface Materials (TIM) plays a crucial role in the design of power electronics and electronic control units. Up to now, this is done manually by experts or by using optimization approaches with a high computational effort. We propose a novel AI-based approach to generate dispense paths for TIM and similar dispensing applications. It is a drop-in replacement for optimization-based approaches. An Artificial Neural Network (ANN) receives the target cooling area as input and directly outputs the dispense path. Our proposed setup does not require labels and we show its feasibility on multiple target areas. The resulting dispense paths can be directly transferred to automated manufacturing equipment and do not exhibit air entrapments. The approach of using an ANN to predict process parameters for a desired target state in real-time could potentially be transferred to other manufacturing processes.
EAP4EMSIG -- Enhancing Event-Driven Microscopy for Microfluidic Single-Cell Analysis
Mar 30, 2025

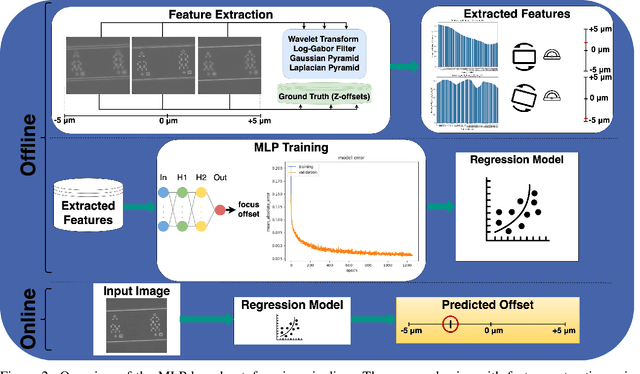

Microfluidic Live-Cell Imaging yields data on microbial cell factories. However, continuous acquisition is challenging as high-throughput experiments often lack realtime insights, delaying responses to stochastic events. We introduce three components in the Experiment Automation Pipeline for Event-Driven Microscopy to Smart Microfluidic Single-Cell Analysis: a fast, accurate Deep Learning autofocusing method predicting the focus offset, an evaluation of real-time segmentation methods and a realtime data analysis dashboard. Our autofocusing achieves a Mean Absolute Error of 0.0226\textmu m with inference times below 50~ms. Among eleven Deep Learning segmentation methods, Cellpose~3 reached a Panoptic Quality of 93.58\%, while a distance-based method is fastest (121~ms, Panoptic Quality 93.02\%). All six Deep Learning Foundation Models were unsuitable for real-time segmentation.
Decision-Focused Fine-Tuning of Time Series Foundation Models for Dispatchable Feeder Optimization
Mar 03, 2025Time series foundation models provide a universal solution for generating forecasts to support optimization problems in energy systems. Those foundation models are typically trained in a prediction-focused manner to maximize forecast quality. In contrast, decision-focused learning directly improves the resulting value of the forecast in downstream optimization rather than merely maximizing forecasting quality. The practical integration of forecast values into forecasting models is challenging, particularly when addressing complex applications with diverse instances, such as buildings. This becomes even more complicated when instances possess specific characteristics that require instance-specific, tailored predictions to increase the forecast value. To tackle this challenge, we use decision-focused fine-tuning within time series foundation models to offer a scalable and efficient solution for decision-focused learning applied to the dispatchable feeder optimization problem. To obtain more robust predictions for scarce building data, we use Moirai as a state-of-the-art foundation model, which offers robust and generalized results with few-shot parameter-efficient fine-tuning. Comparing the decision-focused fine-tuned Moirai with a state-of-the-art classical prediction-focused fine-tuning Morai, we observe an improvement of 9.45% in average total daily costs.
On autoregressive deep learning models for day-ahead wind power forecasting with irregular shutdowns due to redispatching
Nov 30, 2024



Renewable energies and their operation are becoming increasingly vital for the stability of electrical power grids since conventional power plants are progressively being displaced, and their contribution to redispatch interventions is thereby diminishing. In order to consider renewable energies like Wind Power (WP) for such interventions as a substitute, day-ahead forecasts are necessary to communicate their availability for redispatch planning. In this context, automated and scalable forecasting models are required for the deployment to thousands of locally-distributed onshore WP turbines. Furthermore, the irregular interventions into the WP generation capabilities due to redispatch shutdowns pose challenges in the design and operation of WP forecasting models. Since state-of-the-art forecasting methods consider past WP generation values alongside day-ahead weather forecasts, redispatch shutdowns may impact the forecast. Therefore, the present paper highlights these challenges and analyzes state-of-the-art forecasting methods on data sets with both regular and irregular shutdowns. Specifically, we compare the forecasting accuracy of three autoregressive Deep Learning (DL) methods to methods based on WP curve modeling. Interestingly, the latter achieve lower forecasting errors, have fewer requirements for data cleaning during modeling and operation while being computationally more efficient, suggesting their advantages in practical applications.
AutoPQ: Automating Quantile estimation from Point forecasts in the context of sustainability
Nov 30, 2024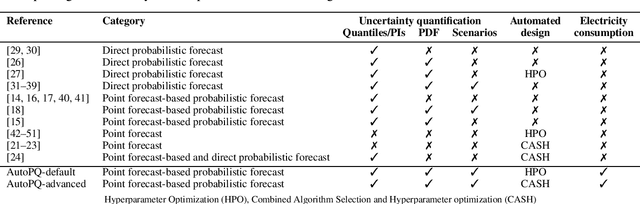
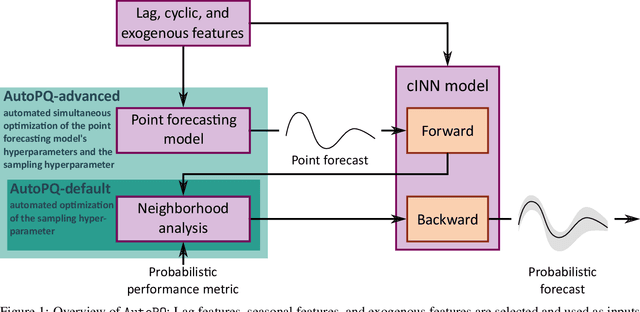
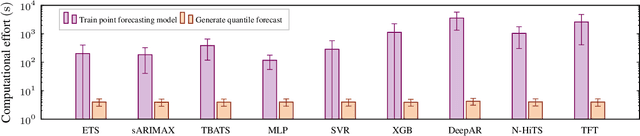
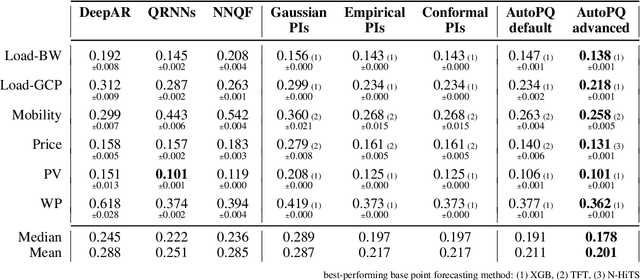
Optimizing smart grid operations relies on critical decision-making informed by uncertainty quantification, making probabilistic forecasting a vital tool. Designing such forecasting models involves three key challenges: accurate and unbiased uncertainty quantification, workload reduction for data scientists during the design process, and limitation of the environmental impact of model training. In order to address these challenges, we introduce AutoPQ, a novel method designed to automate and optimize probabilistic forecasting for smart grid applications. AutoPQ enhances forecast uncertainty quantification by generating quantile forecasts from an existing point forecast by using a conditional Invertible Neural Network (cINN). AutoPQ also automates the selection of the underlying point forecasting method and the optimization of hyperparameters, ensuring that the best model and configuration is chosen for each application. For flexible adaptation to various performance needs and available computing power, AutoPQ comes with a default and an advanced configuration, making it suitable for a wide range of smart grid applications. Additionally, AutoPQ provides transparency regarding the electricity consumption required for performance improvements. We show that AutoPQ outperforms state-of-the-art probabilistic forecasting methods while effectively limiting computational effort and hence environmental impact. Additionally and in the context of sustainability, we quantify the electricity consumption required for performance improvements.