 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Arena: A Dynamic Benchmark for Operational Energy Forecasting
Apr 27, 2026Energy forecasting research faces a persistent comparability gap that makes it difficult to measure consistent progress over time. Reported accuracy gains are often not directly comparable because models are evaluated under study-specific datasets, time periods, information sets, and scoring setups, while widely used benchmarks and competition datasets are typically tied to fixed historical windows. This paper introduces the Energy-Arena, a dynamic benchmarking platform for operational energy time series forecasting that provides a continuously updated reference point as energy systems evolve. The platform operates as an open, API-based submission system and standardizes challenge definitions and submission deadlines aligned with operational constraints. Performance is reported on rolling evaluation windows via persistent leaderboards. By moving from retrospective backtesting to forward-looking benchmarking, the Energy-Arena enforces standardized ex-ante submission and ex-post evaluation, thereby improving transparency by preventing information leakage and retroactive tuning. The platform is publicly available at Energy-Arena.org.
Explainable time-series forecasting with sampling-free SHAP for Transformers
Dec 23, 2025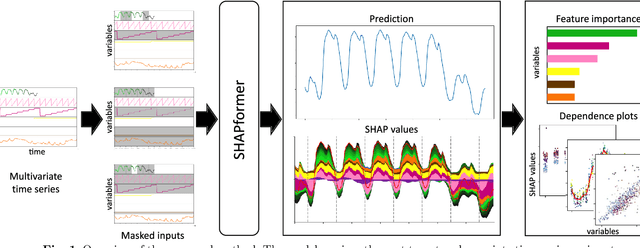
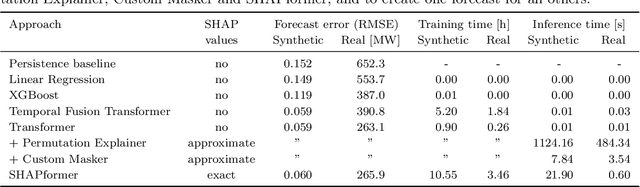
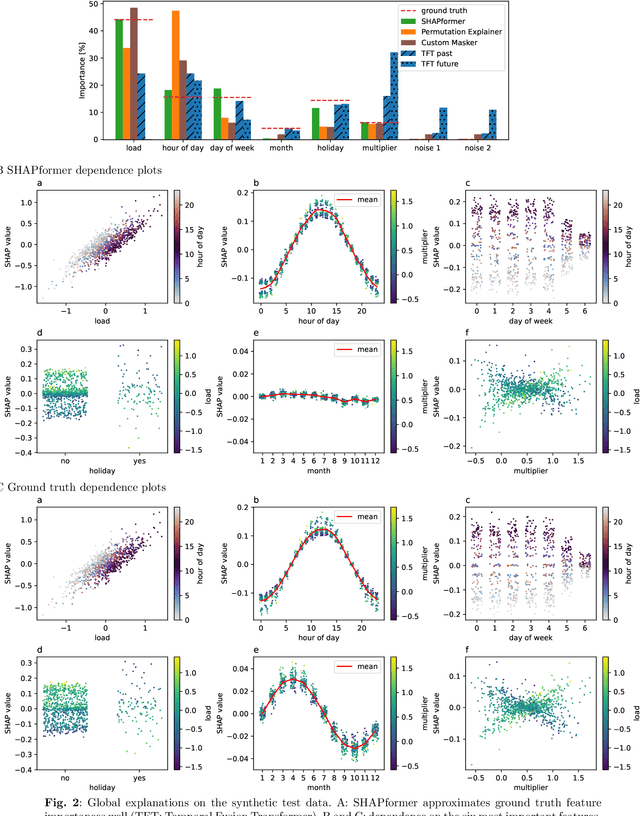
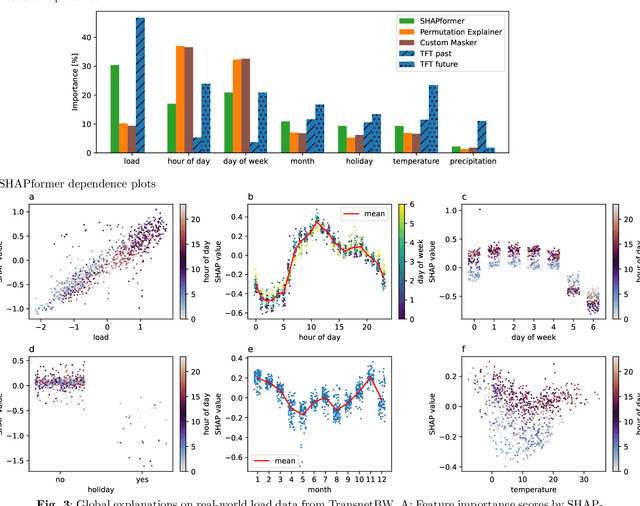
Time-series forecasts are essential for planning and decision-making in many domains. Explainability is key to building user trust and meeting transparency requirements. Shapley Additive Explanations (SHAP) is a popular explainable AI framework, but it lacks efficient implementations for time series and often assumes feature independence when sampling counterfactuals. We introduce SHAPformer, an accurate, fast and sampling-free explainable time-series forecasting model based on the Transformer architecture. It leverages attention manipulation to make predictions based on feature subsets. SHAPformer generates explanations in under one second, several orders of magnitude faster than the SHAP Permutation Explainer. On synthetic data with ground truth explanations, SHAPformer provides explanations that are true to the data. Applied to real-world electrical load data, it achieves competitive predictive performance and delivers meaningful local and global insights, such as identifying the past load as the key predictor and revealing a distinct model behavior during the Christmas period.
Generating peak-aware pseudo-measurements for low-voltage feeders using metadata of distribution system operators
Sep 29, 2024


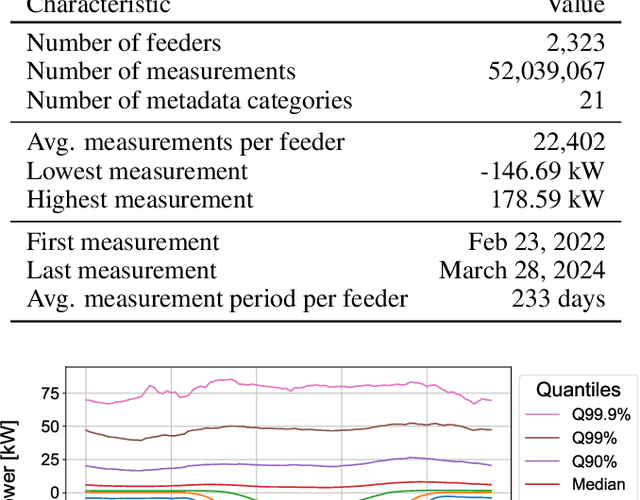
Distribution system operators (DSOs) must cope with new challenges such as the reconstruction of distribution grids along climate neutrality pathways or the ability to manage and control consumption and generation in the grid. In order to meet the challenges, measurements within the distribution grid often form the basis for DSOs. Hence, it is an urgent problem that measurement devices are not installed in many low-voltage (LV) grids. In order to overcome this problem, we present an approach to estimate pseudo-measurements for non-measured LV feeders based on the metadata of the respective feeder using regression models. The feeder metadata comprise information about the number of grid connection points, the installed power of consumers and producers, and billing data in the downstream LV grid. Additionally, we use weather data, calendar data and timestamp information as model features. The existing measurements are used as model target. We extensively evaluate the estimated pseudo-measurements on a large real-world dataset with 2,323 LV feeders characterized by both consumption and feed-in. For this purpose, we introduce peak metrics inspired by the BigDEAL challenge for the peak magnitude, timing and shape for both consumption and feed-in. As regression models, we use XGBoost, a multilayer perceptron (MLP) and a linear regression (LR). We observe that XGBoost and MLP outperform the LR. Furthermore, the results show that the approach adapts to different weather, calendar and timestamp conditions and produces realistic load curves based on the feeder metadata. In the future, the approach can be adapted to other grid levels like substation transformers and can supplement research fields like load modeling, state estimation and LV load forecasting.
Transformer Training Strategies for Forecasting Multiple Load Time Series
Jun 19, 2023Recent work uses Transformers for load forecasting, which are the state of the art for sequence modeling tasks in data-rich domains. In the smart grid of the future, accurate load forecasts must be provided on the level of individual clients of an energy supplier. While the total amount of electrical load data available to an energy supplier will increase with the ongoing smart meter rollout, the amount of data per client will always be limited. We test whether the Transformer benefits from a transfer learning strategy, where a global model is trained on the load time series data from multiple clients. We find that the global model is superior to two other training strategies commonly used in related work: multivariate models and local models. A comparison to linear models and multi-layer perceptrons shows that Transformers are effective for electrical load forecasting when they are trained with the right strategy.
A Fair and In-Depth Evaluation of Existing End-to-End Entity Linking Systems
May 24, 2023



Existing evaluations of entity linking systems often say little about how the system is going to perform for a particular application. There are four fundamental reasons for this: many benchmarks focus on named entities; it is hard to define which other entities to include; there are ambiguities in entity recognition and entity linking; many benchmarks have errors or artifacts that invite overfitting or lead to evaluation results of limited meaningfulness. We provide a more meaningful and fair in-depth evaluation of a variety of existing end-to-end entity linkers. We characterize the strengths and weaknesses of these linkers and how well the results from the respective publications can be reproduced. Our evaluation is based on several widely used benchmarks, which exhibit the problems mentioned above to various degrees, as well as on two new benchmarks, which address these problems.
ELEVANT: A Fully Automatic Fine-Grained Entity Linking Evaluation and Analysis Tool
Aug 15, 2022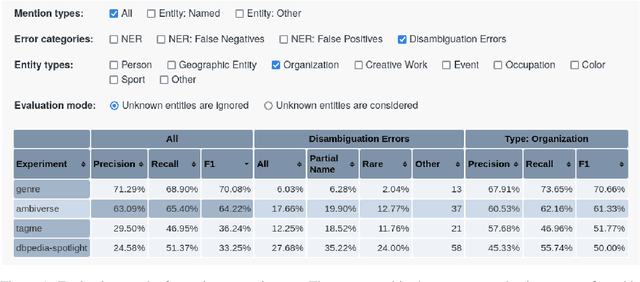

We present Elevant, a tool for the fully automatic fine-grained evaluation of a set of entity linkers on a set of benchmarks. Elevant provides an automatic breakdown of the performance by various error categories and by entity type. Elevant also provides a rich and compact, yet very intuitive and self-explanatory visualization of the results of a linker on a benchmark in comparison to the ground truth. A live demo, the link to the complete code base on GitHub and a link to a demo video are provided under https://elevant.cs.uni-freiburg.de .
Tokenization Repair in the Presence of Spelling Errors
Oct 15, 2020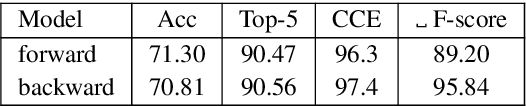

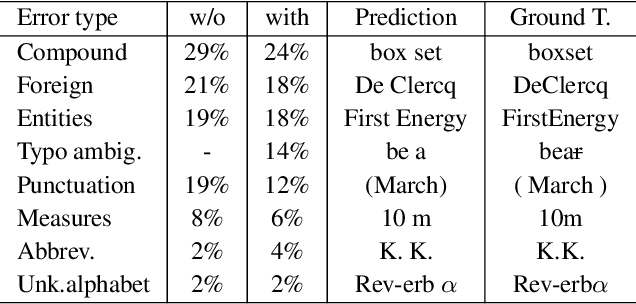
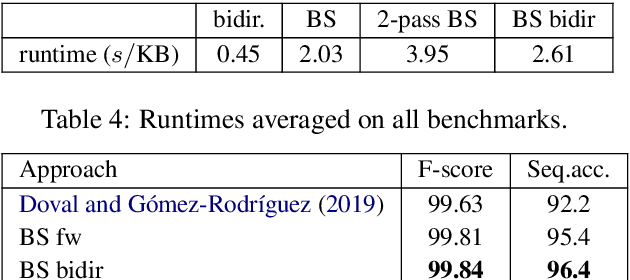
We consider the following tokenization repair problem: Given a natural language text with any combination of missing or spurious spaces, correct these. Spelling errors can be present, but it's not part of the problem to correct them. For example, given: "Tispa per isabout token izaionrep air", compute "Tis paper is about tokenizaion repair". It is tempting to think of this problem as a special case of spelling correction or to treat the two problems together. We make a case that tokenization repair and spelling correction should and can be treated as separate problems. We investigate a variety of neural models as well as a number of strong baselines. We identify three main ingredients to high-quality tokenization repair: deep language models with a bidirectional component, training the models on text with spelling errors, and making use of the space information already present. Our best methods can repair all tokenization errors on 97.5% of the correctly spelled test sentences and on 96.0% of the misspelled test sentences. With all spaces removed from the given text (the scenario from previous work), the accuracy falls to 94.5% and 90.1%, respectively. We conduct a detailed error analysis.