 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRISP: Guided Recurrent IRI Selection over SPARQL Skeletons
Apr 22, 2026We present GRISP (Guided Recurrent IRI Selection over SPARQL Skeletons), a novel SPARQL-based question-answering method over knowledge graphs based on fine-tuning a small language model (SLM). Given a natural-language question, the method first uses the SLM to generate a natural-language SPARQL query skeleton, and then to re-rank and select knowledge graph items to iteratively replace the natural-language placeholders using knowledge graph constraints. The SLM is jointly trained on skeleton generation and list-wise re-ranking data generated from standard question-query pairs. We evaluate the method on common Wikidata and Freebase benchmarks, and achieve better results than other state-of-the-art methods in a comparable setting.
Learning to Read Where to Look: Disease-Aware Vision-Language Pretraining for 3D CT
Mar 02, 2026Recent 3D CT vision-language models align volumes with reports via contrastive pretraining, but typically rely on limited public data and provide only coarse global supervision. We train a 3D CT vision-language model on 98k report-volume pairs (50k patients) collected at a single hospital, combined with public datasets, using SigLIP-style contrastive pretraining together with prompt-based disease supervision in the shared vision-text embedding space. On CT-RATE, our model achieves state-of-the-art text-to-image retrieval (R@10 31.5 vs. 22.2) and competitive disease classification (AUC 83.8 vs. 83.8), with consistent results on Rad-ChestCT (AUC 77.0 vs. 77.3). We further observe that radiologists routinely reference specific images within their reports (e.g., ``series X, image Y''), linking textual descriptions to precise axial locations. We automatically mine 262k such snippet-slice pairs and introduce the task of intra-scan snippet localization -- predicting the axial depth referred to by a text snippet -- reducing mean absolute error to 36.3 mm at 12 mm feature resolution, compared with 67.0 mm for the best baseline. Adding this localization objective leaves retrieval and classification broadly unchanged within confidence bounds, yielding a single unified model for retrieval, classification, and intra-scan grounding.
The Wikidata Query Logs Dataset
Feb 16, 2026We present the Wikidata Query Logs (WDQL) dataset, a dataset consisting of 200k question-query pairs over the Wikidata knowledge graph. It is over 6x larger than the largest existing Wikidata datasets of similar format without relying on template-generated queries. Instead, we construct it using real-world SPARQL queries sent to the Wikidata Query Service and generate questions for them. Since these log-based queries are anonymized, and therefore often do not produce results, a significant amount of effort is needed to convert them back into meaningful SPARQL queries. To achieve this, we present an agent-based method that iteratively de-anonymizes, cleans, and verifies queries against Wikidata while also generating corresponding natural-language questions. We demonstrate the dataset's benefit for training question-answering methods. All WDQL assets, as well as the agent code, are publicly available under a permissive license.
Using Knowledge Graphs to harvest datasets for efficient CLIP model training
May 05, 2025Training high-quality CLIP models typically requires enormous datasets, which limits the development of domain-specific models -- especially in areas that even the largest CLIP models do not cover well -- and drives up training costs. This poses challenges for scientific research that needs fine-grained control over the training procedure of CLIP models. In this work, we show that by employing smart web search strategies enhanced with knowledge graphs, a robust CLIP model can be trained from scratch with considerably less data. Specifically, we demonstrate that an expert foundation model for living organisms can be built using just 10M images. Moreover, we introduce EntityNet, a dataset comprising 33M images paired with 46M text descriptions, which enables the training of a generic CLIP model in significantly reduced time.
A Fair and In-Depth Evaluation of Existing End-to-End Entity Linking Systems
May 24, 2023



Existing evaluations of entity linking systems often say little about how the system is going to perform for a particular application. There are four fundamental reasons for this: many benchmarks focus on named entities; it is hard to define which other entities to include; there are ambiguities in entity recognition and entity linking; many benchmarks have errors or artifacts that invite overfitting or lead to evaluation results of limited meaningfulness. We provide a more meaningful and fair in-depth evaluation of a variety of existing end-to-end entity linkers. We characterize the strengths and weaknesses of these linkers and how well the results from the respective publications can be reproduced. Our evaluation is based on several widely used benchmarks, which exhibit the problems mentioned above to various degrees, as well as on two new benchmarks, which address these problems.
ELEVANT: A Fully Automatic Fine-Grained Entity Linking Evaluation and Analysis Tool
Aug 15, 2022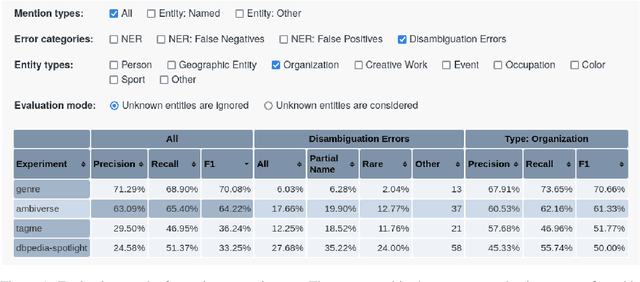

We present Elevant, a tool for the fully automatic fine-grained evaluation of a set of entity linkers on a set of benchmarks. Elevant provides an automatic breakdown of the performance by various error categories and by entity type. Elevant also provides a rich and compact, yet very intuitive and self-explanatory visualization of the results of a linker on a benchmark in comparison to the ground truth. A live demo, the link to the complete code base on GitHub and a link to a demo video are provided under https://elevant.cs.uni-freiburg.de .
Efficient SPARQL Autocompletion via SPARQL
Apr 29, 2021

We show how to achieve fast autocompletion for SPARQL queries on very large knowledge bases. At any position in the body of a SPARQL query, the autocompletion suggests matching subjects, predicates, or objects. The suggestions are context-sensitive in the sense that they lead to a non-empty result and are ranked by their relevance to the part of the query already typed. The suggestions can be narrowed down by prefix search on the names and aliases of the desired subject, predicate, or object. All suggestions are themselves obtained via SPARQL queries, which we call autocompletion queries. For existing SPARQL engines, these queries are impractically slow on large knowledge bases. We present various algorithmic and engineering improvements of an existing SPARQL engine such that these autocompletion queries are executed efficiently. We provide an extensive evaluation of a variety of suggestion methods on three large knowledge bases, including Wikidata (6.9B triples). We explore the trade-off between the relevance of the suggestions and the processing time of the autocompletion queries. We compare our results with two widely used SPARQL engines, Virtuoso and Blazegraph. On Wikidata, we achieve fully sensitive suggestions with sub-second response times for over 90% of a large and diverse set of thousands of autocompletion queries. Materials for full reproducibility, an interactive evaluation web app, and a demo are available on: https://ad.informatik.uni-freiburg.de/publications .
Similarity Classification of Public Transit Stations
Dec 30, 2020



We study the following problem: given two public transit station identifiers A and B, each with a label and a geographic coordinate, decide whether A and B describe the same station. For example, for "St Pancras International" at (51.5306, -0.1253) and "London St Pancras" at (51.5319, -0.1269), the answer would be "Yes". This problem frequently arises in areas where public transit data is used, for example in geographic information systems, schedule merging, route planning, or map matching. We consider several baseline methods based on geographic distance and simple string similarity measures. We also experiment with more elaborate string similarity measures and manually created normalization rules. Our experiments show that these baseline methods produce good, but not fully satisfactory results. We therefore develop an approach based on a random forest classifier which is trained on matching trigrams between two stations, their distance, and their position on an interwoven grid. All approaches are evaluated on extensive ground truth datasets we generated from OpenStreetMap (OSM) data: (1) The union of Great Britain and Ireland and (2) the union of Germany, Switzerland, and Austria. On all datasets, our learning-based approach achieves an F1 score of over 99%, while even the most elaborate baseline approach (based on TFIDF scores and the geographic distance) achieves an F1 score of at most 94%, and a naive approach of using a geographical distance threshold achieves an F1 score of only 75%. Both our training and testing datasets are publicly available.
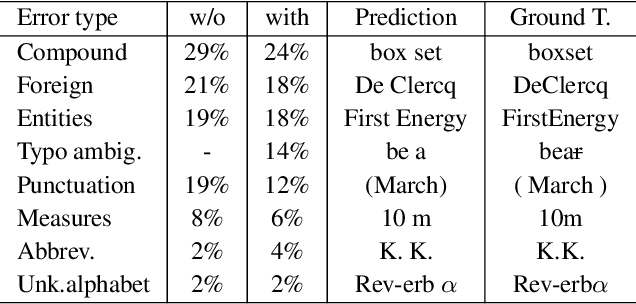
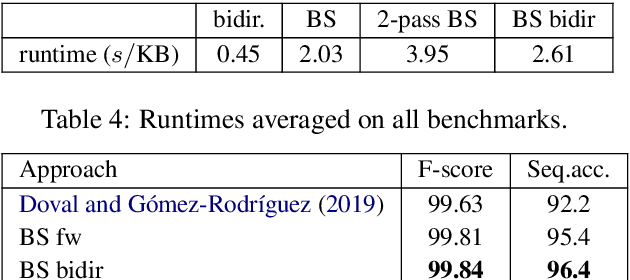
Tokenization Repair in the Presence of Spelling Errors
Oct 15, 2020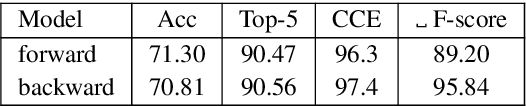

We consider the following tokenization repair problem: Given a natural language text with any combination of missing or spurious spaces, correct these. Spelling errors can be present, but it's not part of the problem to correct them. For example, given: "Tispa per isabout token izaionrep air", compute "Tis paper is about tokenizaion repair". It is tempting to think of this problem as a special case of spelling correction or to treat the two problems together. We make a case that tokenization repair and spelling correction should and can be treated as separate problems. We investigate a variety of neural models as well as a number of strong baselines. We identify three main ingredients to high-quality tokenization repair: deep language models with a bidirectional component, training the models on text with spelling errors, and making use of the space information already present. Our best methods can repair all tokenization errors on 97.5% of the correctly spelled test sentences and on 96.0% of the misspelled test sentences. With all spaces removed from the given text (the scenario from previous work), the accuracy falls to 94.5% and 90.1%, respectively. We conduct a detailed error analysis.