 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalise for Fairness: A Simple Normalisation Technique for Fairness in Regression Machine Learning Problems
Feb 02, 2022



Algorithms and Machine Learning (ML) are increasingly affecting everyday life and several decision-making processes, where ML has an advantage due to scalability or superior performance. Fairness in such applications is crucial, where models should not discriminate their results based on race, gender, or other protected groups. This is especially crucial for models affecting very sensitive topics, like interview hiring or recidivism prediction. Fairness is not commonly studied for regression problems compared to binary classification problems; hence, we present a simple, yet effective method based on normalisation (FaiReg), which minimises the impact of unfairness in regression problems, especially due to labelling bias. We present a theoretical analysis of the method, in addition to an empirical comparison against two standard methods for fairness, namely data balancing and adversarial training. We also include a hybrid formulation (FaiRegH), merging the presented method with data balancing, in an attempt to face labelling and sample biases simultaneously. The experiments are conducted on the multimodal dataset First Impressions (FI) with various labels, namely personality prediction and interview screening score. The results show the superior performance of diminishing the effects of unfairness better than data balancing, also without deteriorating the performance of the original problem as much as adversarial training.
Automated Human Cell Classification in Sparse Datasets using Few-Shot Learning
Jul 27, 2021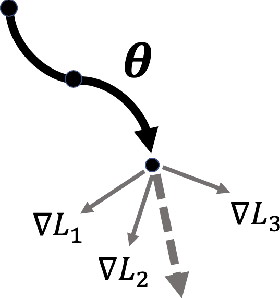
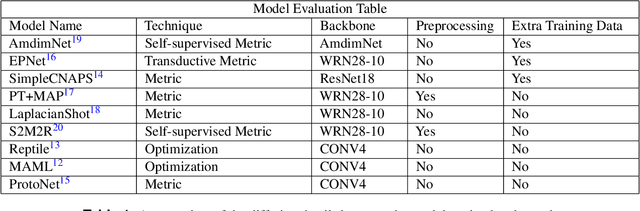
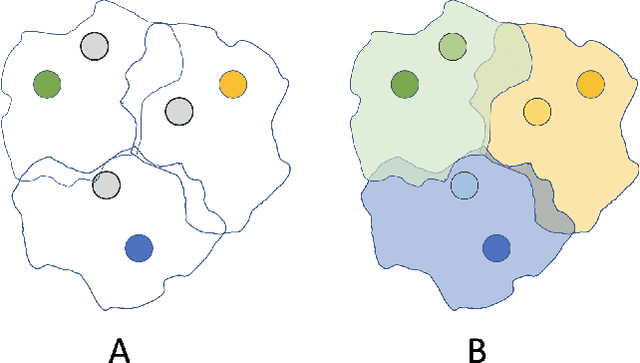
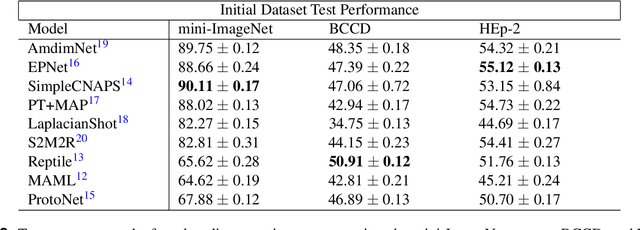
Classifying and analyzing human cells is a lengthy procedure, often involving a trained professional. In an attempt to expedite this process, an active area of research involves automating cell classification through use of deep learning-based techniques. In practice, a large amount of data is required to accurately train these deep learning models. However, due to the sparse human cell datasets currently available, the performance of these models is typically low. This study investigates the feasibility of using few-shot learning-based techniques to mitigate the data requirements for accurate training. The study is comprised of three parts: First, current state-of-the-art few-shot learning techniques are evaluated on human cell classification. The selected techniques are trained on a non-medical dataset and then tested on two out-of-domain, human cell datasets. The results indicate that, overall, the test accuracy of state-of-the-art techniques decreased by at least 30% when transitioning from a non-medical dataset to a medical dataset. Second, this study evaluates the potential benefits, if any, to varying the backbone architecture and training schemes in current state-of-the-art few-shot learning techniques when used in human cell classification. Even with these variations, the overall test accuracy decreased from 88.66% on non-medical datasets to 44.13% at best on the medical datasets. Third, this study presents future directions for using few-shot learning in human cell classification. In general, few-shot learning in its current state performs poorly on human cell classification. The study proves that attempts to modify existing network architectures are not effective and concludes that future research effort should be focused on improving robustness towards out-of-domain testing using optimization-based or self-supervised few-shot learning techniques.
Tokenization Repair in the Presence of Spelling Errors
Oct 15, 2020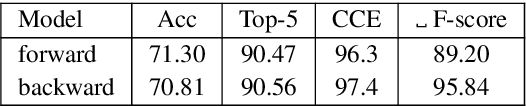

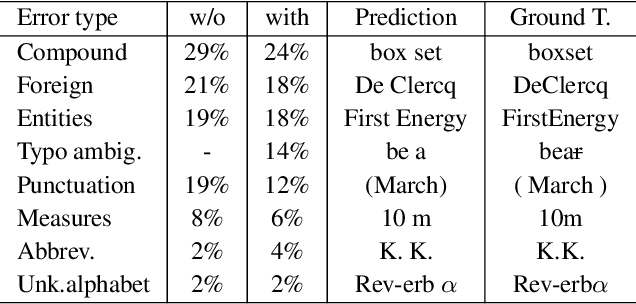
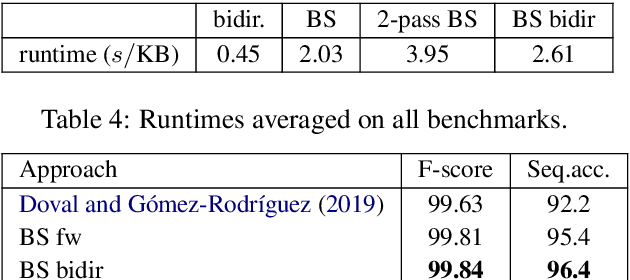
We consider the following tokenization repair problem: Given a natural language text with any combination of missing or spurious spaces, correct these. Spelling errors can be present, but it's not part of the problem to correct them. For example, given: "Tispa per isabout token izaionrep air", compute "Tis paper is about tokenizaion repair". It is tempting to think of this problem as a special case of spelling correction or to treat the two problems together. We make a case that tokenization repair and spelling correction should and can be treated as separate problems. We investigate a variety of neural models as well as a number of strong baselines. We identify three main ingredients to high-quality tokenization repair: deep language models with a bidirectional component, training the models on text with spelling errors, and making use of the space information already present. Our best methods can repair all tokenization errors on 97.5% of the correctly spelled test sentences and on 96.0% of the misspelled test sentences. With all spaces removed from the given text (the scenario from previous work), the accuracy falls to 94.5% and 90.1%, respectively. We conduct a detailed error analysis.
On Deep Speech Packet Loss Concealment: A Mini-Survey
May 15, 2020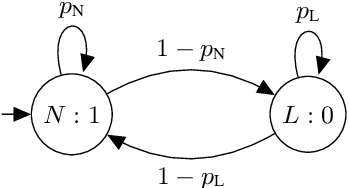

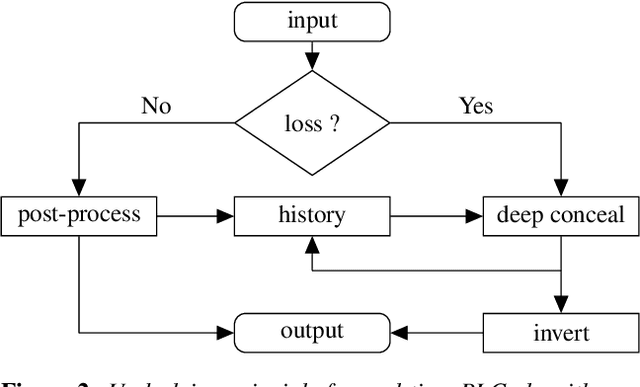
Packet-loss is a common problem in data transmission, using Voice over IP. The problem is an old problem, and there has been a variety of classical approaches that were developed to overcome this problem. However, with the rise of deep learning and generative models like Generative Adversarial Networks and Autoencoders, a new avenue has emerged for attempting to solve packet-loss using deep learning, by generating replacements for lost packets. In this mini-survey, we review all the literature we found to date, that attempt to solve the packet-loss in speech using deep learning methods. Additionally, we briefly review how the problem of packet-loss in a realistic setting is modelled, and how to evaluate Packet Loss Concealment techniques. Moreover, we review a few modern deep learning techniques in related domains that have shown promising results. These techniques shed light on future potentially better solutions for PLC and additional challenges that need to be considered simultaneously with packet-loss.
ConcealNet: An End-to-end Neural Network for Packet Loss Concealment in Deep Speech Emotion Recognition
May 15, 2020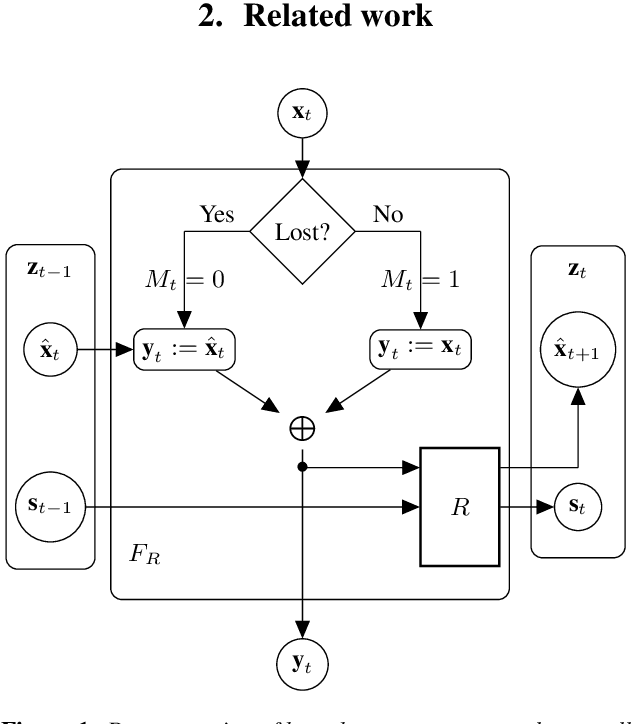


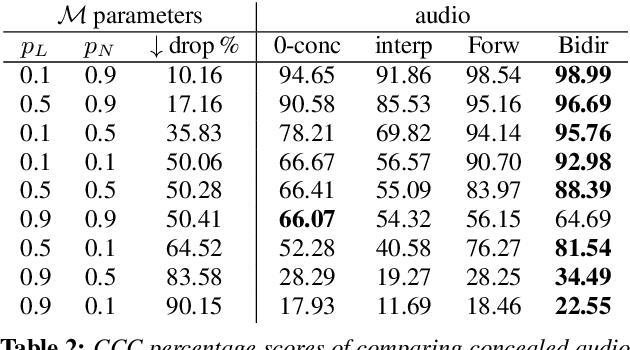
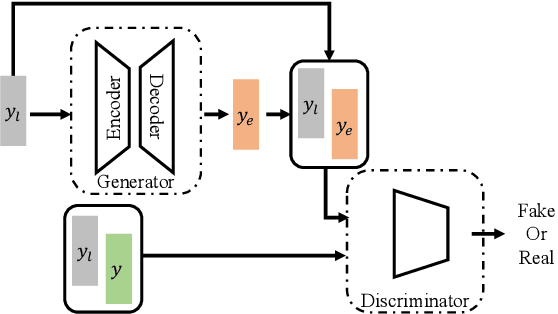
Packet loss is a common problem in data transmission, including speech data transmission. This may affect a wide range of applications that stream audio data, like streaming applications or speech emotion recognition (SER). Packet Loss Concealment (PLC) is any technique of facing packet loss. Simple PLC baselines are 0-substitution or linear interpolation. In this paper, we present a concealment wrapper, which can be used with stacked recurrent neural cells. The concealment cell can provide a recurrent neural network (ConcealNet), that performs real-time step-wise end-to-end PLC at inference time. Additionally, extending this with an end-to-end emotion prediction neural network provides a network that performs SER from audio with lost frames, end-to-end. The proposed model is compared against the fore-mentioned baselines. Additionally, a bidirectional variant with better performance is utilised. For evaluation, we chose the public RECOLA dataset given its long audio tracks with continuous emotion labels. ConcealNet is evaluated on the reconstruction of the audio and the quality of corresponding emotions predicted after that. The proposed ConcealNet model has shown considerable improvement, for both audio reconstruction and the corresponding emotion prediction, in environments that do not have losses with long duration, even when the losses occur frequently.
"I have vxxx bxx connexxxn!": Facing Packet Loss in Deep Speech Emotion Recognition
May 15, 2020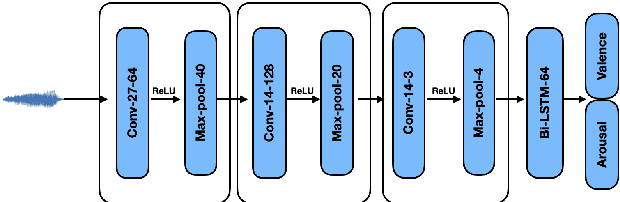

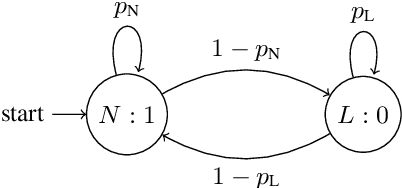
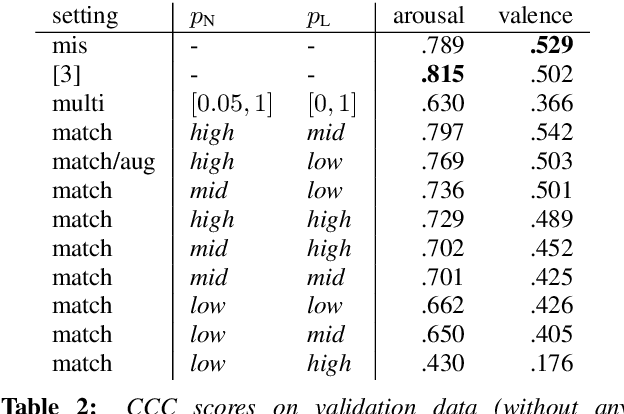
In applications that use emotion recognition via speech, frame-loss can be a severe issue given manifold applications, where the audio stream loses some data frames, for a variety of reasons like low bandwidth. In this contribution, we investigate for the first time the effects of frame-loss on the performance of emotion recognition via speech. Reproducible extensive experiments are reported on the popular RECOLA corpus using a state-of-the-art end-to-end deep neural network, which mainly consists of convolution blocks and recurrent layers. A simple environment based on a Markov Chain model is used to model the loss mechanism based on two main parameters. We explore matched, mismatched, and multi-condition training settings. As one expects, the matched setting yields the best performance, while the mismatched yields the lowest. Furthermore, frame-loss as a data augmentation technique is introduced as a general-purpose strategy to overcome the effects of frame-loss. It can be used during training, and we observed it to produce models that are more robust against frame-loss in run-time environments.
DensSiam: End-to-End Densely-Siamese Network with Self-Attention Model for Object Tracking
Sep 07, 2018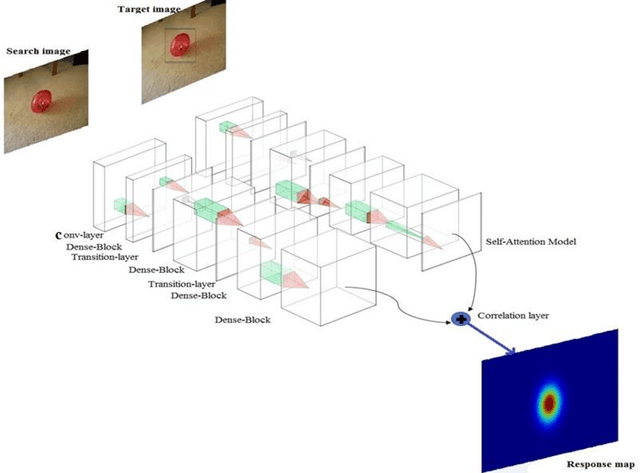
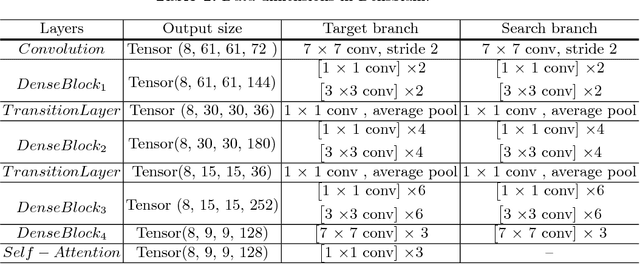
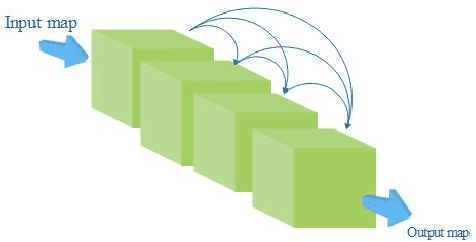
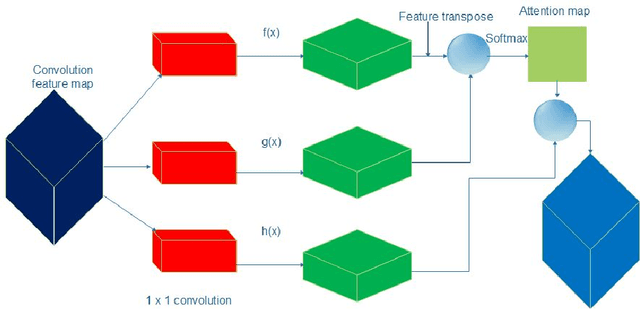
Convolutional Siamese neural networks have been recently used to track objects using deep features. Siamese architecture can achieve real time speed, however it is still difficult to find a Siamese architecture that maintains the generalization capability, high accuracy and speed while decreasing the number of shared parameters especially when it is very deep. Furthermore, a conventional Siamese architecture usually processes one local neighborhood at a time, which makes the appearance model local and non-robust to appearance changes. To overcome these two problems, this paper proposes DensSiam, a novel convolutional Siamese architecture, which uses the concept of dense layers and connects each dense layer to all layers in a feed-forward fashion with a similarity-learning function. DensSiam also includes a Self-Attention mechanism to force the network to pay more attention to the non-local features during offline training. Extensive experiments are performed on four tracking benchmarks: OTB2013 and OTB2015 for validation set; and VOT2015, VOT2016 and VOT2017 for testing set. The obtained results show that DensSiam achieves superior results on these benchmarks compared to other current state-of-the-art methods.