 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Human Cell Classification in Sparse Datasets using Few-Shot Learning
Paper and Code
Jul 27, 2021
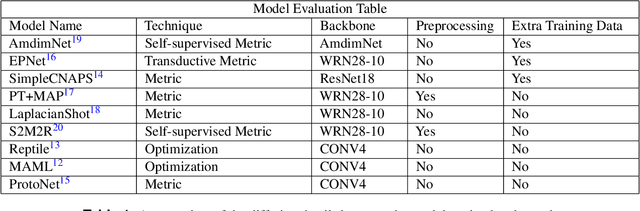
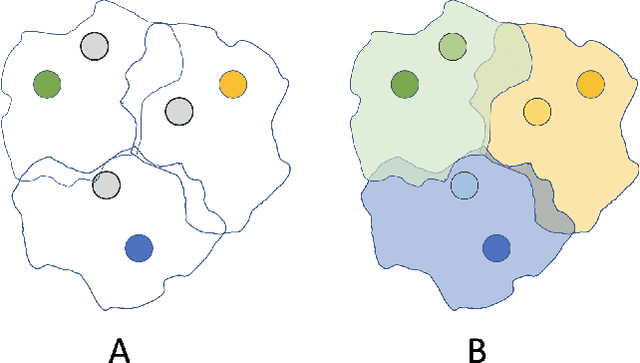
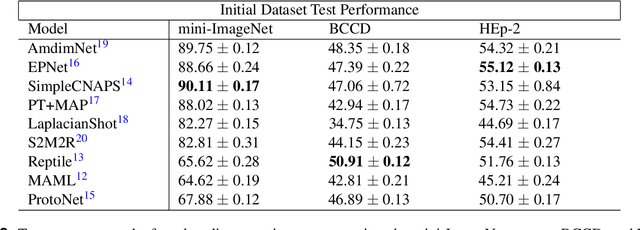
Classifying and analyzing human cells is a lengthy procedure, often involving a trained professional. In an attempt to expedite this process, an active area of research involves automating cell classification through use of deep learning-based techniques. In practice, a large amount of data is required to accurately train these deep learning models. However, due to the sparse human cell datasets currently available, the performance of these models is typically low. This study investigates the feasibility of using few-shot learning-based techniques to mitigate the data requirements for accurate training. The study is comprised of three parts: First, current state-of-the-art few-shot learning techniques are evaluated on human cell classification. The selected techniques are trained on a non-medical dataset and then tested on two out-of-domain, human cell datasets. The results indicate that, overall, the test accuracy of state-of-the-art techniques decreased by at least 30% when transitioning from a non-medical dataset to a medical dataset. Second, this study evaluates the potential benefits, if any, to varying the backbone architecture and training schemes in current state-of-the-art few-shot learning techniques when used in human cell classification. Even with these variations, the overall test accuracy decreased from 88.66% on non-medical datasets to 44.13% at best on the medical datasets. Third, this study presents future directions for using few-shot learning in human cell classification. In general, few-shot learning in its current state performs poorly on human cell classification. The study proves that attempts to modify existing network architectures are not effective and concludes that future research effort should be focused on improving robustness towards out-of-domain testing using optimization-based or self-supervised few-shot learning techniques.