 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Human Cell Classification in Sparse Datasets using Few-Shot Learning
Jul 27, 2021
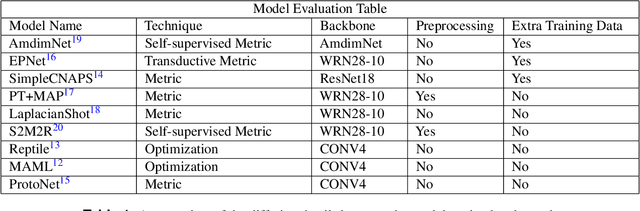
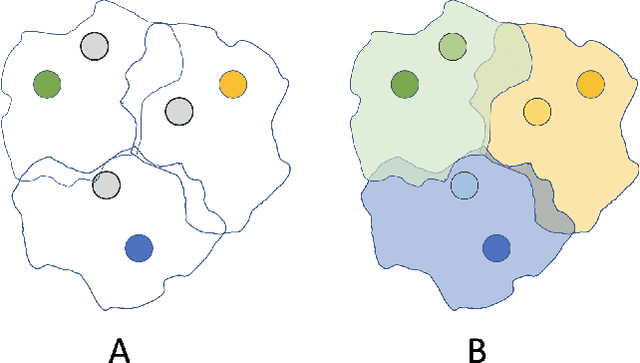
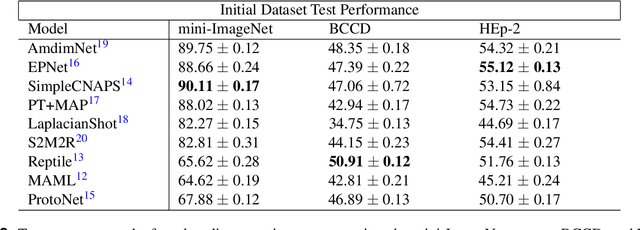
Classifying and analyzing human cells is a lengthy procedure, often involving a trained professional. In an attempt to expedite this process, an active area of research involves automating cell classification through use of deep learning-based techniques. In practice, a large amount of data is required to accurately train these deep learning models. However, due to the sparse human cell datasets currently available, the performance of these models is typically low. This study investigates the feasibility of using few-shot learning-based techniques to mitigate the data requirements for accurate training. The study is comprised of three parts: First, current state-of-the-art few-shot learning techniques are evaluated on human cell classification. The selected techniques are trained on a non-medical dataset and then tested on two out-of-domain, human cell datasets. The results indicate that, overall, the test accuracy of state-of-the-art techniques decreased by at least 30% when transitioning from a non-medical dataset to a medical dataset. Second, this study evaluates the potential benefits, if any, to varying the backbone architecture and training schemes in current state-of-the-art few-shot learning techniques when used in human cell classification. Even with these variations, the overall test accuracy decreased from 88.66% on non-medical datasets to 44.13% at best on the medical datasets. Third, this study presents future directions for using few-shot learning in human cell classification. In general, few-shot learning in its current state performs poorly on human cell classification. The study proves that attempts to modify existing network architectures are not effective and concludes that future research effort should be focused on improving robustness towards out-of-domain testing using optimization-based or self-supervised few-shot learning techniques.
NullSpaceNet: Nullspace Convoluional Neural Network with Differentiable Loss Function
Apr 25, 2020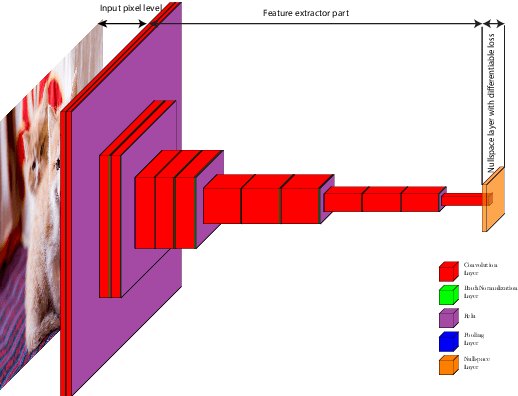

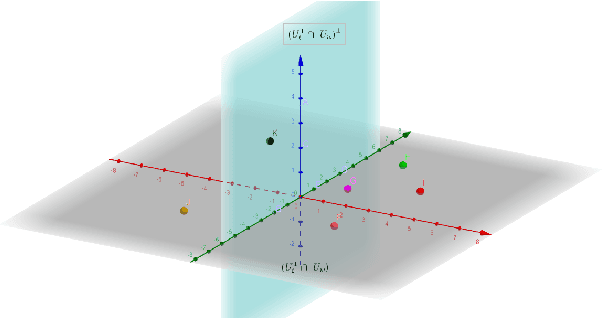
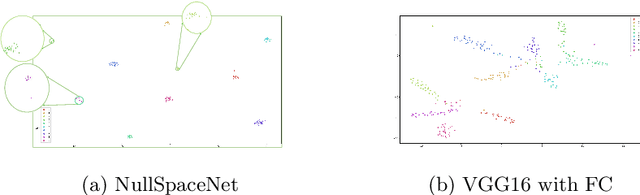
We propose NullSpaceNet, a novel network that maps from the pixel level input to a joint-nullspace (as opposed to the traditional feature space), where the newly learned joint-nullspace features have clearer interpretation and are more separable. NullSpaceNet ensures that all inputs from the same class are collapsed into one point in this new joint-nullspace, and the different classes are collapsed into different points with high separation margins. Moreover, a novel differentiable loss function is proposed that has a closed-form solution with no free-parameters. NullSpaceNet exhibits superior performance when tested against VGG16 with fully-connected layer over 4 different datasets, with accuracy gain of up to 4.55%, a reduction in learnable parameters from 135M to 19M, and reduction in inference time of 99% in favor of NullSpaceNet. This means that NullSpaceNet needs less than 1% of the time it takes a traditional CNN to classify a batch of images with better accuracy.
DomainSiam: Domain-Aware Siamese Network for Visual Object Tracking
Aug 21, 2019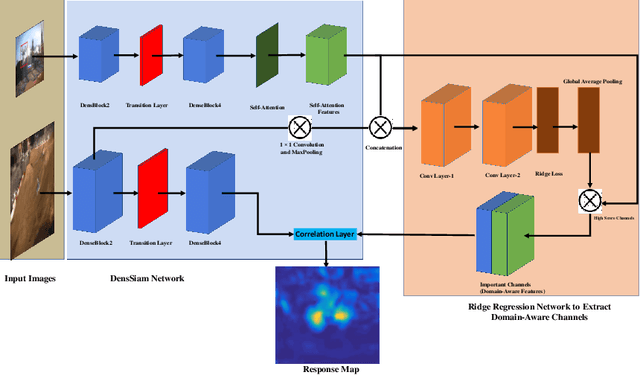
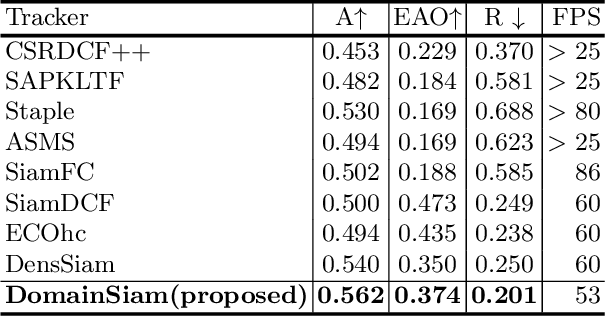
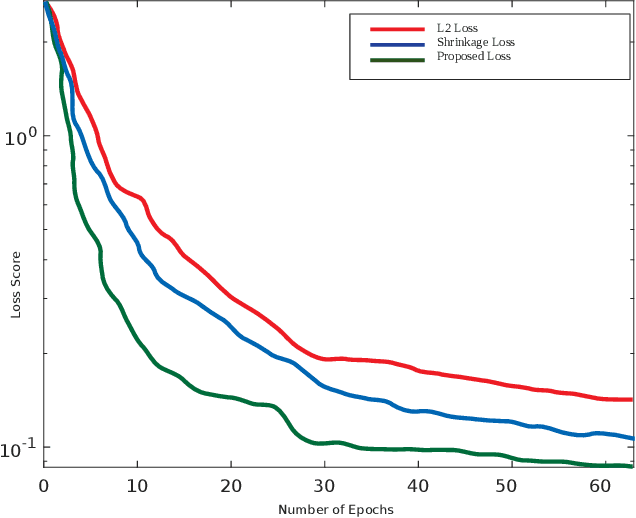
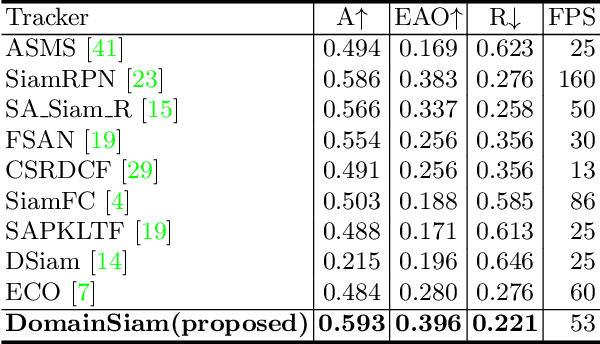
Visual object tracking is a fundamental task in the field of computer vision. Recently, Siamese trackers have achieved state-of-the-art performance on recent benchmarks. However, Siamese trackers do not fully utilize semantic and objectness information from pre-trained networks that have been trained on the image classification task. Furthermore, the pre-trained Siamese architecture is sparsely activated by the category label which leads to unnecessary calculations and overfitting. In this paper, we propose to learn a Domain-Aware, that is fully utilizing semantic and objectness information while producing a class-agnostic using a ridge regression network. Moreover, to reduce the sparsity problem, we solve the ridge regression problem with a differentiable weighted-dynamic loss function. Our tracker, dubbed DomainSiam, improves the feature learning in the training phase and generalization capability to other domains. Extensive experiments are performed on five tracking benchmarks including OTB2013 and OTB2015 for a validation set; as well as the VOT2017, VOT2018, LaSOT, TrackingNet, and GOT10k for a testing set. DomainSiam achieves state-of-the-art performance on these benchmarks while running at 53 FPS.
* 13 pages
DensSiam: End-to-End Densely-Siamese Network with Self-Attention Model for Object Tracking
Sep 07, 2018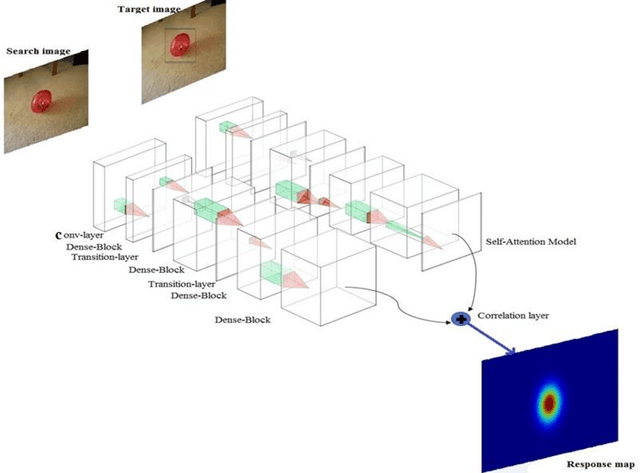
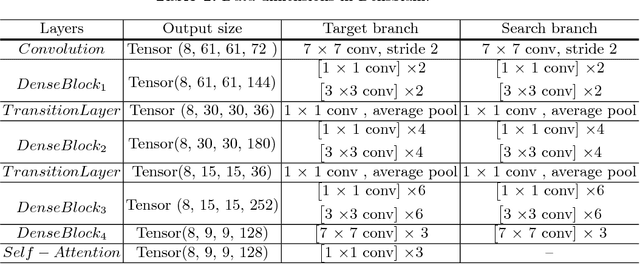
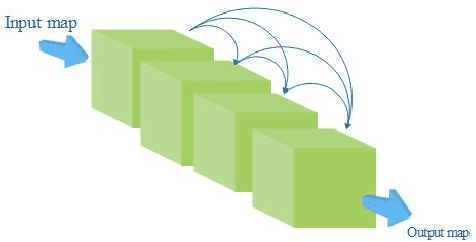
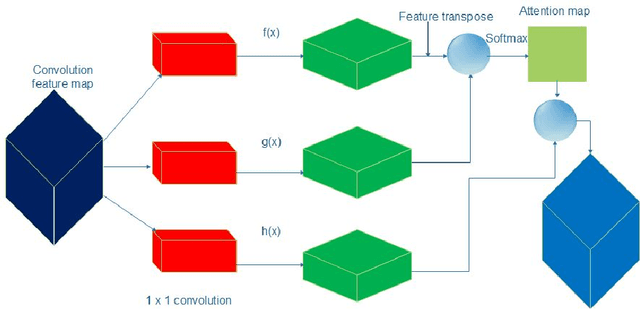
Convolutional Siamese neural networks have been recently used to track objects using deep features. Siamese architecture can achieve real time speed, however it is still difficult to find a Siamese architecture that maintains the generalization capability, high accuracy and speed while decreasing the number of shared parameters especially when it is very deep. Furthermore, a conventional Siamese architecture usually processes one local neighborhood at a time, which makes the appearance model local and non-robust to appearance changes. To overcome these two problems, this paper proposes DensSiam, a novel convolutional Siamese architecture, which uses the concept of dense layers and connects each dense layer to all layers in a feed-forward fashion with a similarity-learning function. DensSiam also includes a Self-Attention mechanism to force the network to pay more attention to the non-local features during offline training. Extensive experiments are performed on four tracking benchmarks: OTB2013 and OTB2015 for validation set; and VOT2015, VOT2016 and VOT2017 for testing set. The obtained results show that DensSiam achieves superior results on these benchmarks compared to other current state-of-the-art methods.