 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcealNet: An End-to-end Neural Network for Packet Loss Concealment in Deep Speech Emotion Recognition
Paper and Code
May 15, 2020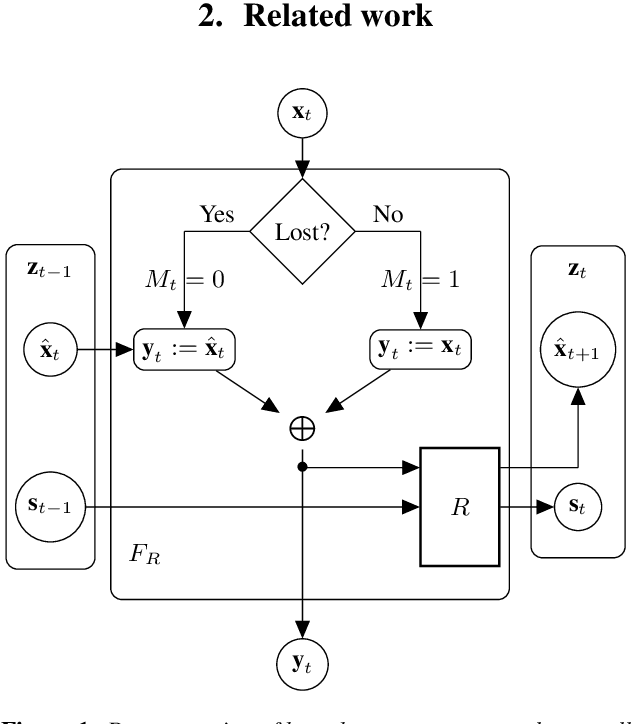


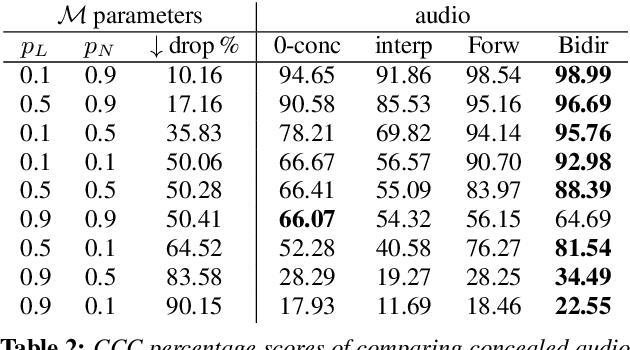
Packet loss is a common problem in data transmission, including speech data transmission. This may affect a wide range of applications that stream audio data, like streaming applications or speech emotion recognition (SER). Packet Loss Concealment (PLC) is any technique of facing packet loss. Simple PLC baselines are 0-substitution or linear interpolation. In this paper, we present a concealment wrapper, which can be used with stacked recurrent neural cells. The concealment cell can provide a recurrent neural network (ConcealNet), that performs real-time step-wise end-to-end PLC at inference time. Additionally, extending this with an end-to-end emotion prediction neural network provides a network that performs SER from audio with lost frames, end-to-end. The proposed model is compared against the fore-mentioned baselines. Additionally, a bidirectional variant with better performance is utilised. For evaluation, we chose the public RECOLA dataset given its long audio tracks with continuous emotion labels. ConcealNet is evaluated on the reconstruction of the audio and the quality of corresponding emotions predicted after that. The proposed ConcealNet model has shown considerable improvement, for both audio reconstruction and the corresponding emotion prediction, in environments that do not have losses with long duration, even when the losses occur frequently.