 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I have vxxx bxx connexxxn!": Facing Packet Loss in Deep Speech Emotion Recognition
Paper and Code
May 15, 2020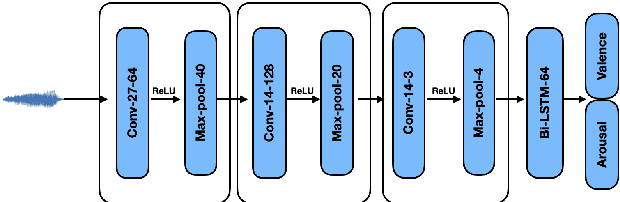

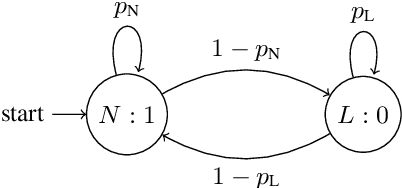
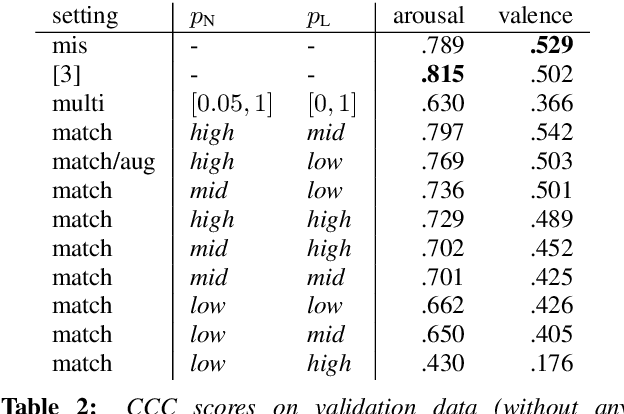
In applications that use emotion recognition via speech, frame-loss can be a severe issue given manifold applications, where the audio stream loses some data frames, for a variety of reasons like low bandwidth. In this contribution, we investigate for the first time the effects of frame-loss on the performance of emotion recognition via speech. Reproducible extensive experiments are reported on the popular RECOLA corpus using a state-of-the-art end-to-end deep neural network, which mainly consists of convolution blocks and recurrent layers. A simple environment based on a Markov Chain model is used to model the loss mechanism based on two main parameters. We explore matched, mismatched, and multi-condition training settings. As one expects, the matched setting yields the best performance, while the mismatched yields the lowest. Furthermore, frame-loss as a data augmentation technique is introduced as a general-purpose strategy to overcome the effects of frame-loss. It can be used during training, and we observed it to produce models that are more robust against frame-loss in run-time environments.