 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Parallelism for Fast and Efficient Bayesian Learning
Apr 06, 2026Machine learning models, and deep neural networks in particular, are increasingly deployed in risk-sensitive domains such as healthcare, environmental forecasting, and finance, where reliable quantification of predictive uncertainty is essential. However, many uncertainty quantification (UQ) methods remain difficult to apply due to their substantial computational cost. Sampling-based Bayesian learning approaches, such as Bayesian neural networks (BNNs), are particularly expensive since drawing and evaluating multiple parameter samples rapidly exhausts memory and compute resources. These constraints have limited the accessibility and exploration of Bayesian techniques thus far. To address these challenges, we introduce sampling parallelism, a simple yet powerful parallelization strategy that targets the primary bottleneck of sampling-based Bayesian learning: the samples themselves. By distributing sample evaluations across multiple GPUs, our method reduces memory pressure and training time without requiring architectural changes or extensive hyperparameter tuning. We detail the methodology and evaluate its performance on a few example tasks and architectures, comparing against distributed data parallelism (DDP) as a baseline. We further demonstrate that sampling parallelism is complementary to existing strategies by implementing a hybrid approach that combines sample and data parallelism. Our experiments show near-perfect scaling when the sample number is scaled proportionally to the computational resources, confirming that sample evaluations parallelize cleanly. Although DDP achieves better raw speedups under scaling with constant workload, sampling parallelism has a notable advantage: by applying independent stochastic augmentations to the same batch on each GPU, it increases augmentation diversity and thus reduces the number of epochs required for convergence.
Inverse Design of Optical Multilayer Thin Films using Robust Masked Diffusion Models
Apr 01, 2026Inverse design of optical multilayer stacks seeks to infer layer materials, thicknesses, and ordering from a desired target spectrum. It is a long-standing challenge due to the large design space and non-unique solutions. We introduce \texttt{OptoLlama}, a masked diffusion language model for inverse thin-film design from optical spectra. Representing multilayer stacks as sequences of material-thickness tokens, \texttt{OptoLlama} conditions generation on reflectance, absorptance, and transmittance spectra and learns a probabilistic mapping from optical response to structure. Evaluated on a representative test set of 3,000 targets, \texttt{OptoLlama} reduces the mean absolute spectral error by 2.9-fold relative to a nearest-neighbor template baseline and by 3.45-fold relative to the state-of-the-art data-driven baseline, called \texttt{OptoGPT}. Case studies on designed and expert-defined targets show that the model reproduces characteristic spectral features and recovers physically meaningful stack motifs, including distributed Bragg reflectors. These results establish diffusion-based sequence modeling as a powerful framework for inverse photonic design.
Differentiable Power-Flow Optimization
Mar 30, 2026With the rise of renewable energy sources and their high variability in generation, the management of power grids becomes increasingly complex and computationally demanding. Conventional AC-power-flow simulations, which use the Newton-Raphson (NR) method, suffer from poor scalability, making them impractical for emerging use cases such as joint transmission-distribution modeling and global grid analysis. At the same time, purely data-driven surrogate models lack physical guarantees and may violate fundamental constraints. In this work, we propose Differentiable Power-Flow (DPF), a reformulation of the AC power-flow problem as a differentiable simulation. DPF enables end-to-end gradient propagation from the physical power mismatches to the underlying simulation parameters, thereby allowing these parameters to be identified efficiently using gradient-based optimization. We demonstrate that DPF provides a scalable alternative to NR by leveraging GPU acceleration, sparse tensor representations, and batching capabilities available in modern machine-learning frameworks such as PyTorch. DPF is especially suited as a tool for time-series analyses due to its efficient reuse of previous solutions, for N-1 contingency-analyses due to its ability to process cases in batches, and as a screening tool by leveraging its speed and early stopping capability. The code is available in the authors' code repository.
Energy Consumption in Parallel Neural Network Training
Aug 11, 2025The increasing demand for computational resources of training neural networks leads to a concerning growth in energy consumption. While parallelization has enabled upscaling model and dataset sizes and accelerated training, its impact on energy consumption is often overlooked. To close this research gap, we conducted scaling experiments for data-parallel training of two models, ResNet50 and FourCastNet, and evaluated the impact of parallelization parameters, i.e., GPU count, global batch size, and local batch size, on predictive performance, training time, and energy consumption. We show that energy consumption scales approximately linearly with the consumed resources, i.e., GPU hours; however, the respective scaling factor differs substantially between distinct model trainings and hardware, and is systematically influenced by the number of samples and gradient updates per GPU hour. Our results shed light on the complex interplay of scaling up neural network training and can inform future developments towards more sustainable AI research.
PETNet -- Coincident Particle Event Detection using Spiking Neural Networks
Apr 09, 2025Spiking neural networks (SNN) hold the promise of being a more biologically plausible, low-energy alternative to conventional artificial neural networks. Their time-variant nature makes them particularly suitable for processing time-resolved, sparse binary data. In this paper, we investigate the potential of leveraging SNNs for the detection of photon coincidences in positron emission tomography (PET) data. PET is a medical imaging technique based on injecting a patient with a radioactive tracer and detecting the emitted photons. One central post-processing task for inferring an image of the tracer distribution is the filtering of invalid hits occurring due to e.g. absorption or scattering processes. Our approach, coined PETNet, interprets the detector hits as a binary-valued spike train and learns to identify photon coincidence pairs in a supervised manner. We introduce a dedicated multi-objective loss function and demonstrate the effects of explicitly modeling the detector geometry on simulation data for two use-cases. Our results show that PETNet can outperform the state-of-the-art classical algorithm with a maximal coincidence detection $F_1$ of 95.2%. At the same time, PETNet is able to predict photon coincidences up to 36 times faster than the classical approach, highlighting the great potential of SNNs in particle physics applications.
A Comparative Study of Pruning Methods in Transformer-based Time Series Forecasting
Dec 17, 2024



The current landscape in time-series forecasting is dominated by Transformer-based models. Their high parameter count and corresponding demand in computational resources pose a challenge to real-world deployment, especially for commercial and scientific applications with low-power embedded devices. Pruning is an established approach to reduce neural network parameter count and save compute. However, the implications and benefits of pruning Transformer-based models for time series forecasting are largely unknown. To close this gap, we provide a comparative benchmark study by evaluating unstructured and structured pruning on various state-of-the-art multivariate time series models. We study the effects of these pruning strategies on model predictive performance and computational aspects like model size, operations, and inference time. Our results show that certain models can be pruned even up to high sparsity levels, outperforming their dense counterpart. However, fine-tuning pruned models is necessary. Furthermore, we demonstrate that even with corresponding hardware and software support, structured pruning is unable to provide significant time savings.
AutoPQ: Automating Quantile estimation from Point forecasts in the context of sustainability
Nov 30, 2024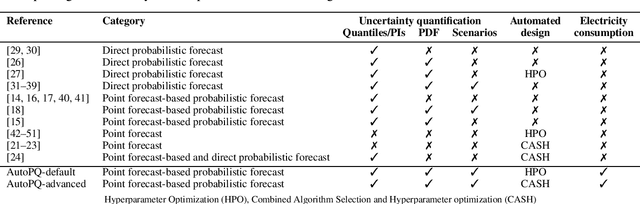
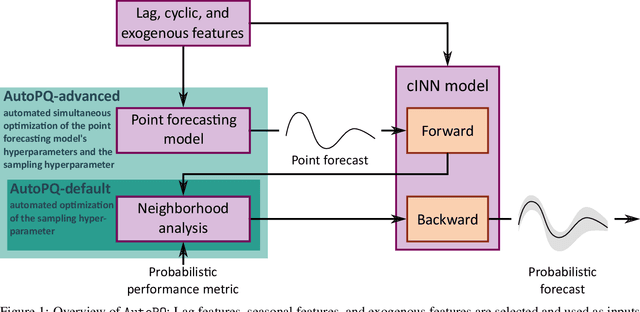
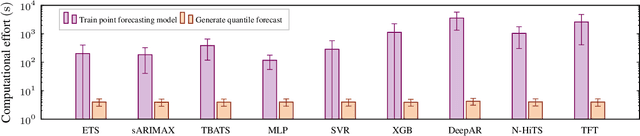
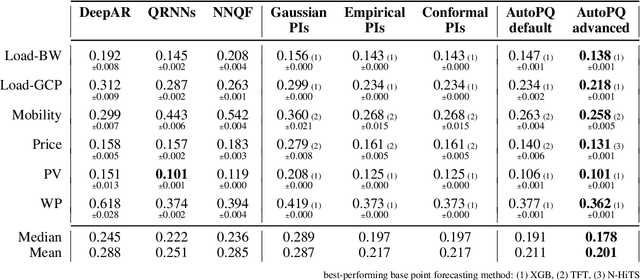
Optimizing smart grid operations relies on critical decision-making informed by uncertainty quantification, making probabilistic forecasting a vital tool. Designing such forecasting models involves three key challenges: accurate and unbiased uncertainty quantification, workload reduction for data scientists during the design process, and limitation of the environmental impact of model training. In order to address these challenges, we introduce AutoPQ, a novel method designed to automate and optimize probabilistic forecasting for smart grid applications. AutoPQ enhances forecast uncertainty quantification by generating quantile forecasts from an existing point forecast by using a conditional Invertible Neural Network (cINN). AutoPQ also automates the selection of the underlying point forecasting method and the optimization of hyperparameters, ensuring that the best model and configuration is chosen for each application. For flexible adaptation to various performance needs and available computing power, AutoPQ comes with a default and an advanced configuration, making it suitable for a wide range of smart grid applications. Additionally, AutoPQ provides transparency regarding the electricity consumption required for performance improvements. We show that AutoPQ outperforms state-of-the-art probabilistic forecasting methods while effectively limiting computational effort and hence environmental impact. Additionally and in the context of sustainability, we quantify the electricity consumption required for performance improvements.
Beyond Backpropagation: Optimization with Multi-Tangent Forward Gradients
Oct 23, 2024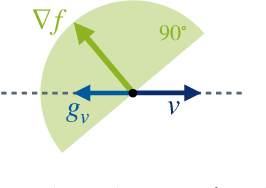
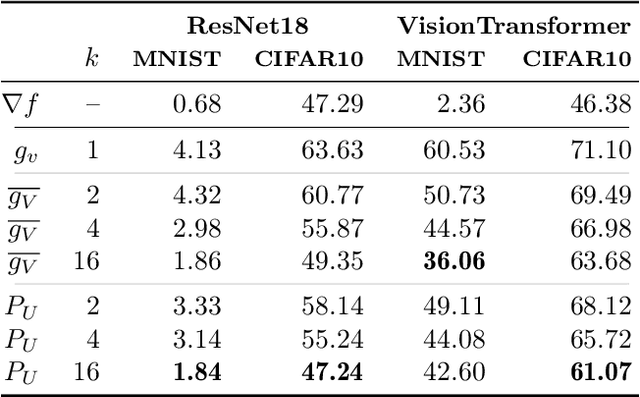

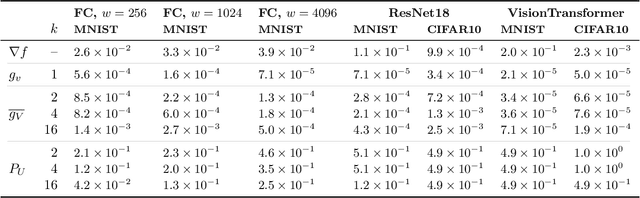
The gradients used to train neural networks are typically computed using backpropagation. While an efficient way to obtain exact gradients, backpropagation is computationally expensive, hinders parallelization, and is biologically implausible. Forward gradients are an approach to approximate the gradients from directional derivatives along random tangents computed by forward-mode automatic differentiation. So far, research has focused on using a single tangent per step. This paper provides an in-depth analysis of multi-tangent forward gradients and introduces an improved approach to combining the forward gradients from multiple tangents based on orthogonal projections. We demonstrate that increasing the number of tangents improves both approximation quality and optimization performance across various tasks.
ReCycle: Fast and Efficient Long Time Series Forecasting with Residual Cyclic Transformers
May 06, 2024Transformers have recently gained prominence in long time series forecasting by elevating accuracies in a variety of use cases. Regrettably, in the race for better predictive performance the overhead of model architectures has grown onerous, leading to models with computational demand infeasible for most practical applications. To bridge the gap between high method complexity and realistic computational resources, we introduce the Residual Cyclic Transformer, ReCycle. ReCycle utilizes primary cycle compression to address the computational complexity of the attention mechanism in long time series. By learning residuals from refined smoothing average techniques, ReCycle surpasses state-of-the-art accuracy in a variety of application use cases. The reliable and explainable fallback behavior ensured by simple, yet robust, smoothing average techniques additionally lowers the barrier for user acceptance. At the same time, our approach reduces the run time and energy consumption by more than an order of magnitude, making both training and inference feasible on low-performance, low-power and edge computing devices. Code is available at https://github.com/Helmholtz-AI-Energy/ReCycle
AB-Training: A Communication-Efficient Approach for Distributed Low-Rank Learning
May 02, 2024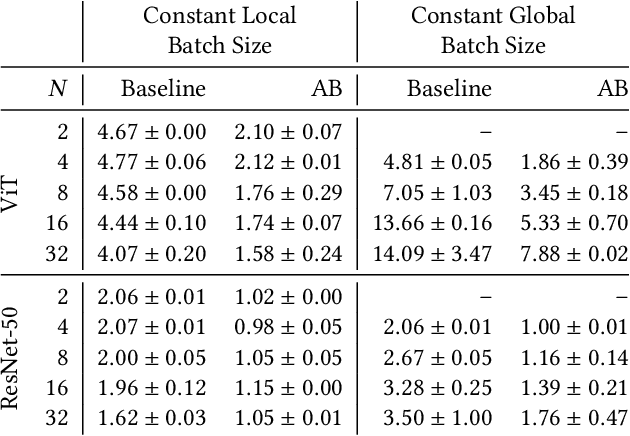
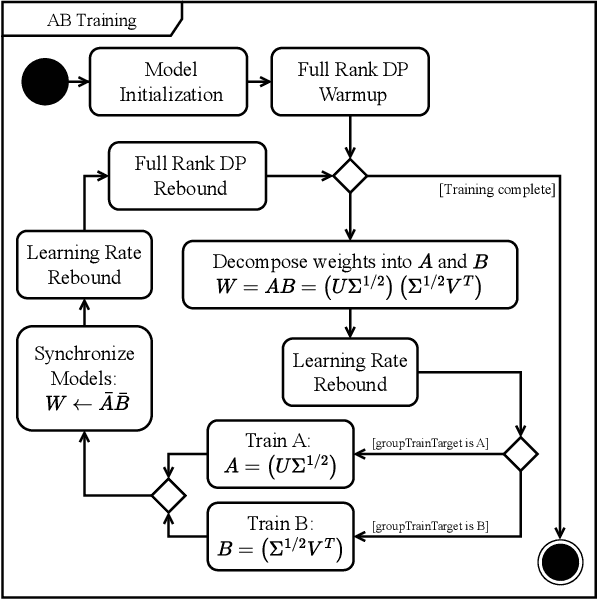
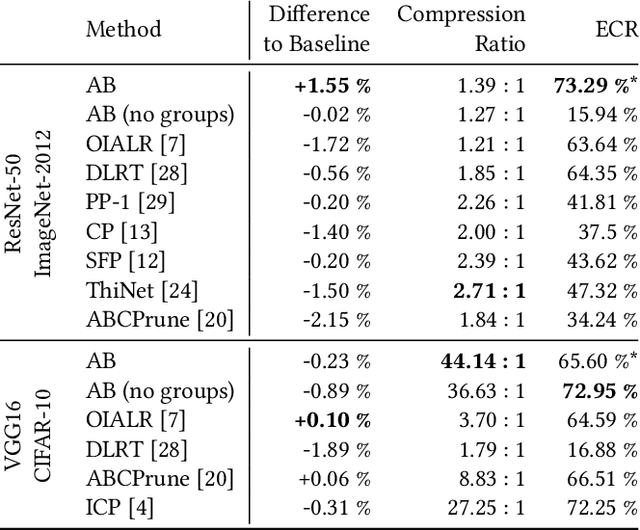
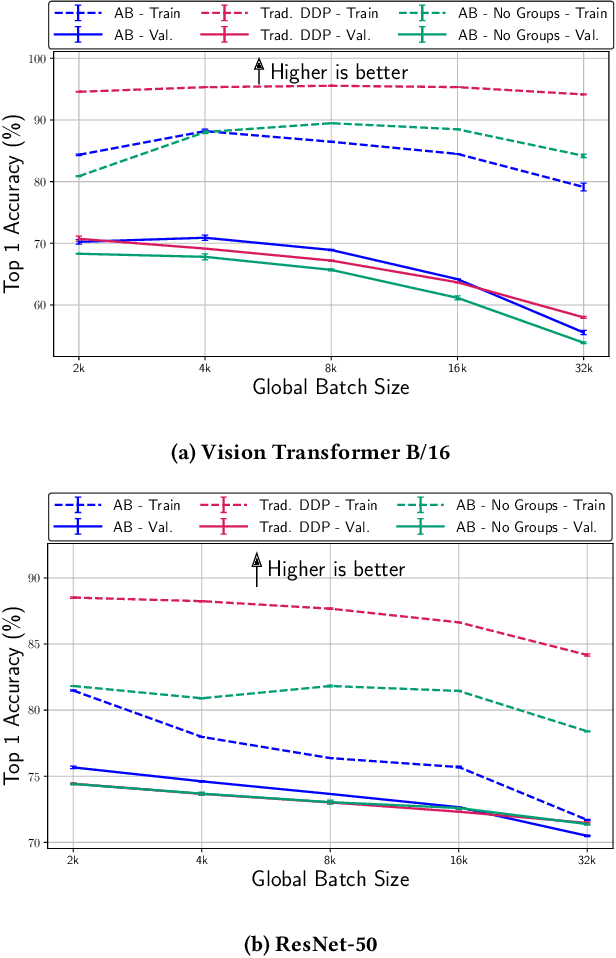
Communication bottlenecks hinder the scalability of distributed neural network training, particularly on distributed-memory computing clusters. To significantly reduce this communication overhead, we introduce AB-training, a novel data-parallel training method that decomposes weight matrices into low-rank representations and utilizes independent group-based training. This approach consistently reduces network traffic by 50% across multiple scaling scenarios, increasing the training potential on communication-constrained systems. Our method exhibits regularization effects at smaller scales, leading to improved generalization for models like VGG16, while achieving a remarkable 44.14 : 1 compression ratio during training on CIFAR-10 and maintaining competitive accuracy. Albeit promising, our experiments reveal that large batch effects remain a challenge even in low-rank training regimes.