 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Pruning Methods in Transformer-based Time Series Forecasting
Dec 17, 2024The current landscape in time-series forecasting is dominated by Transformer-based models. Their high parameter count and corresponding demand in computational resources pose a challenge to real-world deployment, especially for commercial and scientific applications with low-power embedded devices. Pruning is an established approach to reduce neural network parameter count and save compute. However, the implications and benefits of pruning Transformer-based models for time series forecasting are largely unknown. To close this gap, we provide a comparative benchmark study by evaluating unstructured and structured pruning on various state-of-the-art multivariate time series models. We study the effects of these pruning strategies on model predictive performance and computational aspects like model size, operations, and inference time. Our results show that certain models can be pruned even up to high sparsity levels, outperforming their dense counterpart. However, fine-tuning pruned models is necessary. Furthermore, we demonstrate that even with corresponding hardware and software support, structured pruning is unable to provide significant time savings.
AB-Training: A Communication-Efficient Approach for Distributed Low-Rank Learning
May 02, 2024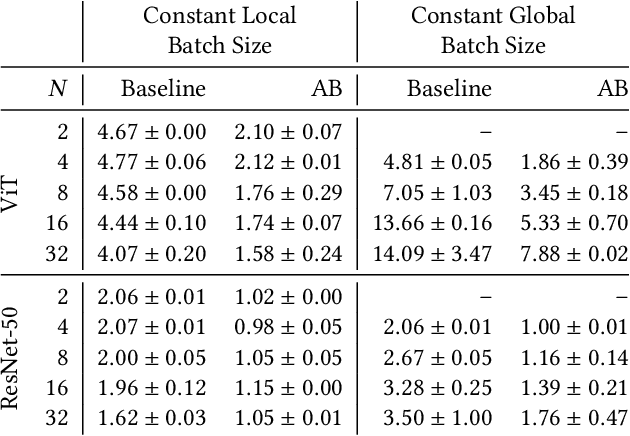
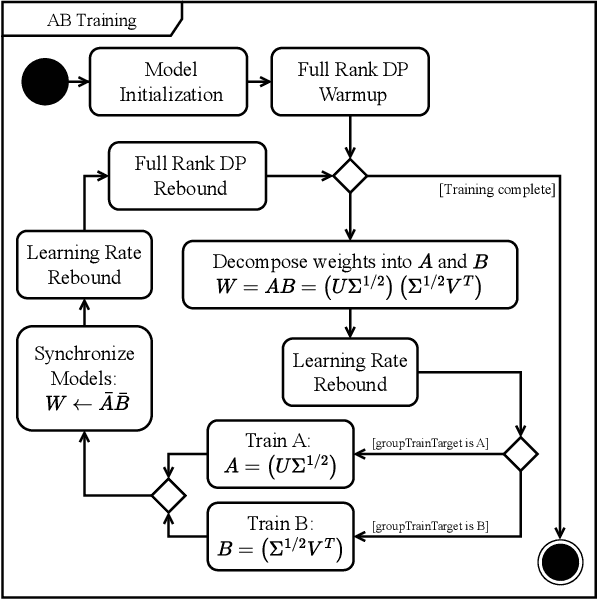
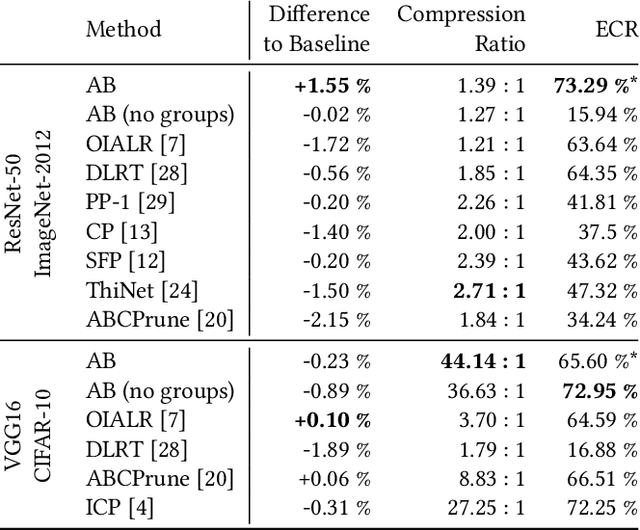
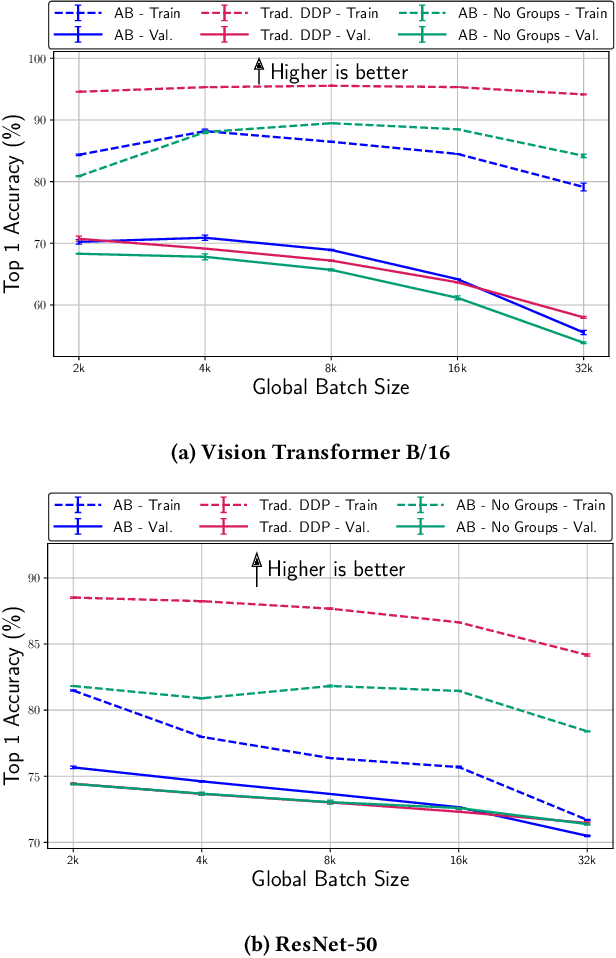
Communication bottlenecks hinder the scalability of distributed neural network training, particularly on distributed-memory computing clusters. To significantly reduce this communication overhead, we introduce AB-training, a novel data-parallel training method that decomposes weight matrices into low-rank representations and utilizes independent group-based training. This approach consistently reduces network traffic by 50% across multiple scaling scenarios, increasing the training potential on communication-constrained systems. Our method exhibits regularization effects at smaller scales, leading to improved generalization for models like VGG16, while achieving a remarkable 44.14 : 1 compression ratio during training on CIFAR-10 and maintaining competitive accuracy. Albeit promising, our experiments reveal that large batch effects remain a challenge even in low-rank training regimes.