 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Backpropagation: Optimization with Multi-Tangent Forward Gradients
Oct 23, 2024The gradients used to train neural networks are typically computed using backpropagation. While an efficient way to obtain exact gradients, backpropagation is computationally expensive, hinders parallelization, and is biologically implausible. Forward gradients are an approach to approximate the gradients from directional derivatives along random tangents computed by forward-mode automatic differentiation. So far, research has focused on using a single tangent per step. This paper provides an in-depth analysis of multi-tangent forward gradients and introduces an improved approach to combining the forward gradients from multiple tangents based on orthogonal projections. We demonstrate that increasing the number of tangents improves both approximation quality and optimization performance across various tasks.
AB-Training: A Communication-Efficient Approach for Distributed Low-Rank Learning
May 02, 2024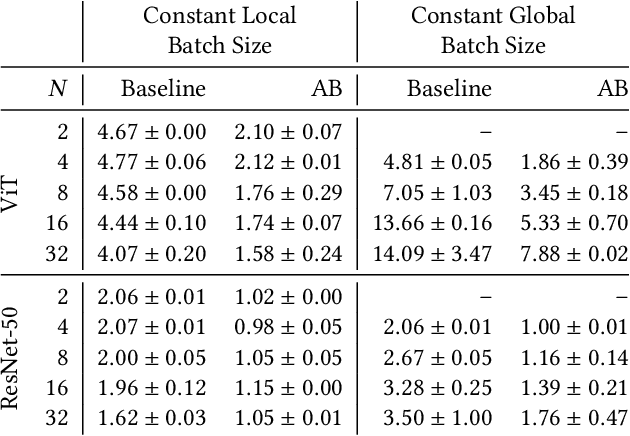
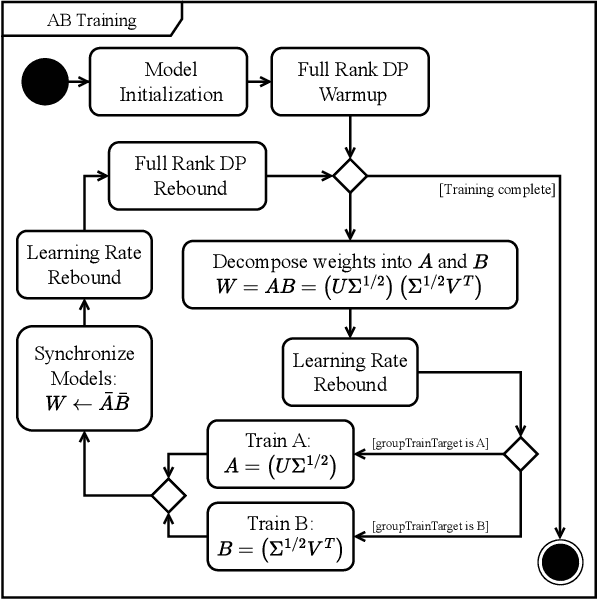
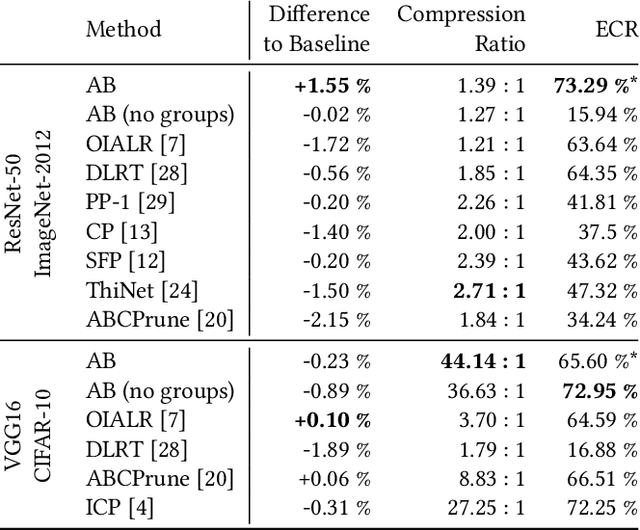
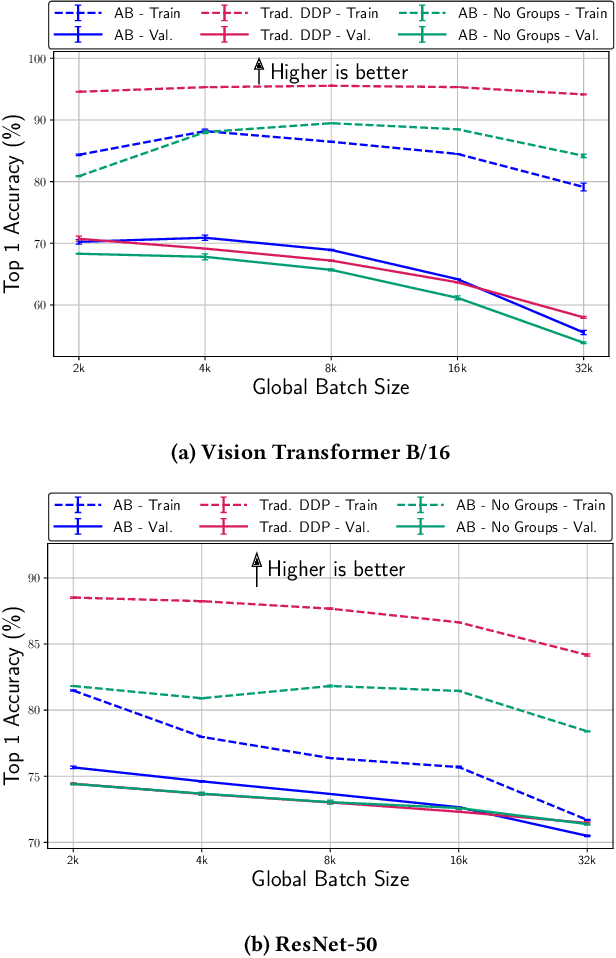
Communication bottlenecks hinder the scalability of distributed neural network training, particularly on distributed-memory computing clusters. To significantly reduce this communication overhead, we introduce AB-training, a novel data-parallel training method that decomposes weight matrices into low-rank representations and utilizes independent group-based training. This approach consistently reduces network traffic by 50% across multiple scaling scenarios, increasing the training potential on communication-constrained systems. Our method exhibits regularization effects at smaller scales, leading to improved generalization for models like VGG16, while achieving a remarkable 44.14 : 1 compression ratio during training on CIFAR-10 and maintaining competitive accuracy. Albeit promising, our experiments reveal that large batch effects remain a challenge even in low-rank training regimes.
Harnessing Orthogonality to Train Low-Rank Neural Networks
Jan 16, 2024



This study explores the learning dynamics of neural networks by analyzing the singular value decomposition (SVD) of their weights throughout training. Our investigation reveals that an orthogonal basis within each multidimensional weight's SVD representation stabilizes during training. Building upon this, we introduce Orthogonality-Informed Adaptive Low-Rank (OIALR) training, a novel training method exploiting the intrinsic orthogonality of neural networks. OIALR seamlessly integrates into existing training workflows with minimal accuracy loss, as demonstrated by benchmarking on various datasets and well-established network architectures. With appropriate hyperparameter tuning, OIALR can surpass conventional training setups, including those of state-of-the-art models.
Feed-Forward Optimization With Delayed Feedback for Neural Networks
Apr 26, 2023Backpropagation has long been criticized for being biologically implausible, relying on concepts that are not viable in natural learning processes. This paper proposes an alternative approach to solve two core issues, i.e., weight transport and update locking, for biological plausibility and computational efficiency. We introduce Feed-Forward with delayed Feedback (F$^3$), which improves upon prior work by utilizing delayed error information as a sample-wise scaling factor to approximate gradients more accurately. We find that F$^3$ reduces the gap in predictive performance between biologically plausible training algorithms and backpropagation by up to 96%. This demonstrates the applicability of biologically plausible training and opens up promising new avenues for low-energy training and parallelization.
Massively Parallel Genetic Optimization through Asynchronous Propagation of Populations
Jan 20, 2023We present Propulate, an evolutionary optimization algorithm and software package for global optimization and in particular hyperparameter search. For efficient use of HPC resources, Propulate omits the synchronization after each generation as done in conventional genetic algorithms. Instead, it steers the search with the complete population present at time of breeding new individuals. We provide an MPI-based implementation of our algorithm, which features variants of selection, mutation, crossover, and migration and is easy to extend with custom functionality. We compare Propulate to the established optimization tool Optuna. We find that Propulate is up to three orders of magnitude faster without sacrificing solution accuracy, demonstrating the efficiency and efficacy of our lazy synchronization approach. Code and documentation are available at https://github.com/Helmholtz-AI-Energy/propulate
HyDe: The First Open-Source, Python-Based, GPU-Accelerated Hyperspectral Denoising Package
Apr 14, 2022
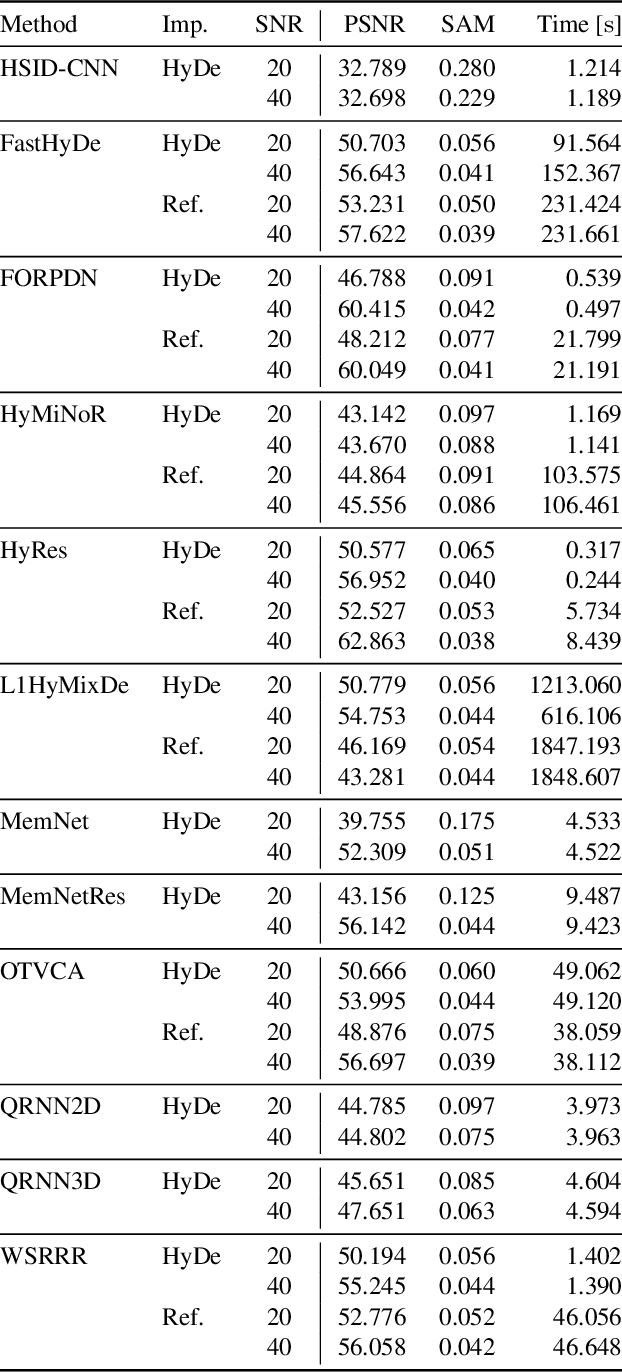
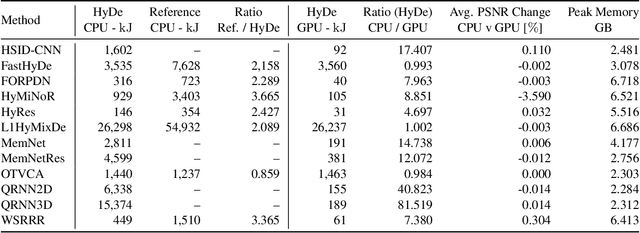
As with any physical instrument, hyperspectral cameras induce different kinds of noise in the acquired data. Therefore, Hyperspectral denoising is a crucial step for analyzing hyperspectral images (HSIs). Conventional computational methods rarely use GPUs to improve efficiency and are not fully open-source. Alternatively, deep learning-based methods are often open-source and use GPUs, but their training and utilization for real-world applications remain non-trivial for many researchers. Consequently, we propose HyDe: the first open-source, GPU-accelerated Python-based, hyperspectral image denoising toolbox, which aims to provide a large set of methods with an easy-to-use environment. HyDe includes a variety of methods ranging from low-rank wavelet-based methods to deep neural network (DNN) models. HyDe's interface dramatically improves the interoperability of these methods and the performance of the underlying functions. In fact, these methods maintain similar HSI denoising performance to their original implementations while consuming nearly ten times less energy. Furthermore, we present a method for training DNNs for denoising HSIs which are not spatially related to the training dataset, i.e., training on ground-level HSIs for denoising HSIs with other perspectives including airborne, drone-borne, and space-borne. To utilize the trained DNNs, we show a sliding window method to effectively denoise HSIs which would otherwise require more than 40 GB. The package can be found at: \url{https://github.com/Helmholtz-AI-Energy/HyDe}.
Accelerating Neural Network Training with Distributed Asynchronous and Selective Optimization (DASO)
Apr 15, 2021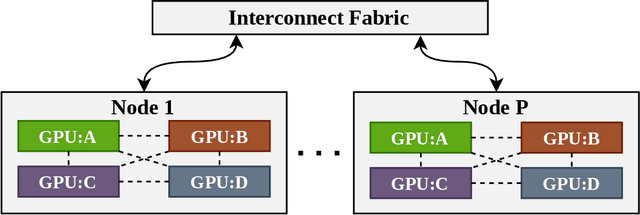
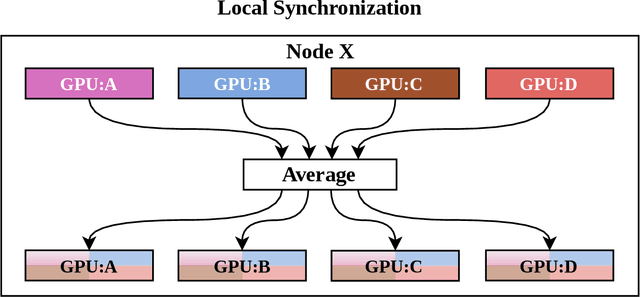

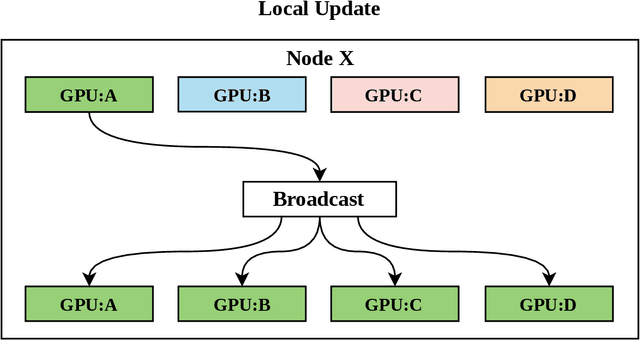
With increasing data and model complexities, the time required to train neural networks has become prohibitively large. To address the exponential rise in training time, users are turning to data parallel neural networks (DPNN) to utilize large-scale distributed resources on computer clusters. Current DPNN approaches implement the network parameter updates by synchronizing and averaging gradients across all processes with blocking communication operations. This synchronization is the central algorithmic bottleneck. To combat this, we introduce the Distributed Asynchronous and Selective Optimization (DASO) method which leverages multi-GPU compute node architectures to accelerate network training. DASO uses a hierarchical and asynchronous communication scheme comprised of node-local and global networks while adjusting the global synchronization rate during the learning process. We show that DASO yields a reduction in training time of up to 34% on classical and state-of-the-art networks, as compared to other existing data parallel training methods.
HeAT -- a Distributed and GPU-accelerated Tensor Framework for Data Analytics
Jul 27, 2020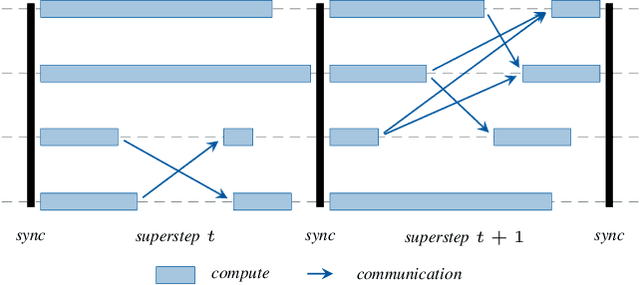
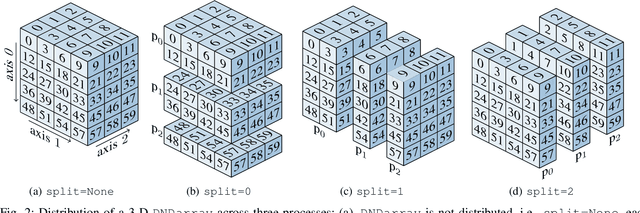
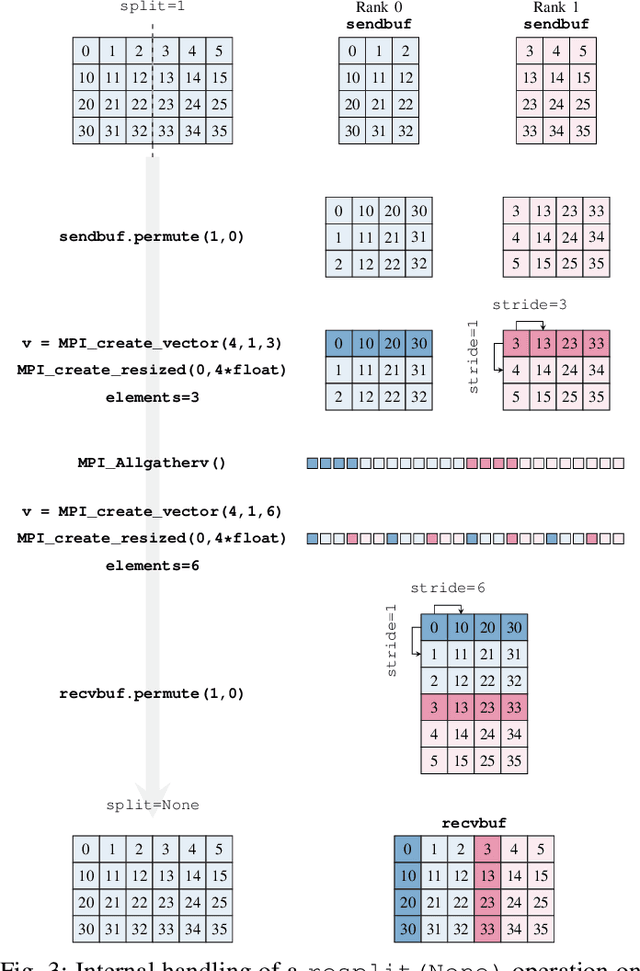

In order to cope with the exponential growth in available data, the efficiency of data analysis and machine learning libraries have recently received increased attention. Although corresponding array-based numerical kernels have been significantly improved, most are limited by the resources available on a single computational node. Consequently, kernels must exploit distributed resources, e.g., distributed memory architectures. To this end, we introduce HeAT, an array-based numerical programming framework for large-scale parallel processing with an easy-to-use NumPy-like API. HeAT utilizes PyTorch as a node-local eager execution engine and distributes the workload via MPI on arbitrarily large high-performance computing systems. It provides both low-level array-based computations, as well as assorted higher-level algorithms. With HeAT, it is possible for a NumPy user to take advantage of their available resources, significantly lowering the barrier to distributed data analysis. Compared with applications written in similar frameworks, HeAT achieves speedups of up to two orders of magnitude.