 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Consumption in Parallel Neural Network Training
Aug 11, 2025The increasing demand for computational resources of training neural networks leads to a concerning growth in energy consumption. While parallelization has enabled upscaling model and dataset sizes and accelerated training, its impact on energy consumption is often overlooked. To close this research gap, we conducted scaling experiments for data-parallel training of two models, ResNet50 and FourCastNet, and evaluated the impact of parallelization parameters, i.e., GPU count, global batch size, and local batch size, on predictive performance, training time, and energy consumption. We show that energy consumption scales approximately linearly with the consumed resources, i.e., GPU hours; however, the respective scaling factor differs substantially between distinct model trainings and hardware, and is systematically influenced by the number of samples and gradient updates per GPU hour. Our results shed light on the complex interplay of scaling up neural network training and can inform future developments towards more sustainable AI research.
A Comparative Study of Pruning Methods in Transformer-based Time Series Forecasting
Dec 17, 2024The current landscape in time-series forecasting is dominated by Transformer-based models. Their high parameter count and corresponding demand in computational resources pose a challenge to real-world deployment, especially for commercial and scientific applications with low-power embedded devices. Pruning is an established approach to reduce neural network parameter count and save compute. However, the implications and benefits of pruning Transformer-based models for time series forecasting are largely unknown. To close this gap, we provide a comparative benchmark study by evaluating unstructured and structured pruning on various state-of-the-art multivariate time series models. We study the effects of these pruning strategies on model predictive performance and computational aspects like model size, operations, and inference time. Our results show that certain models can be pruned even up to high sparsity levels, outperforming their dense counterpart. However, fine-tuning pruned models is necessary. Furthermore, we demonstrate that even with corresponding hardware and software support, structured pruning is unable to provide significant time savings.
Beyond Backpropagation: Optimization with Multi-Tangent Forward Gradients
Oct 23, 2024The gradients used to train neural networks are typically computed using backpropagation. While an efficient way to obtain exact gradients, backpropagation is computationally expensive, hinders parallelization, and is biologically implausible. Forward gradients are an approach to approximate the gradients from directional derivatives along random tangents computed by forward-mode automatic differentiation. So far, research has focused on using a single tangent per step. This paper provides an in-depth analysis of multi-tangent forward gradients and introduces an improved approach to combining the forward gradients from multiple tangents based on orthogonal projections. We demonstrate that increasing the number of tangents improves both approximation quality and optimization performance across various tasks.
ReCycle: Fast and Efficient Long Time Series Forecasting with Residual Cyclic Transformers
May 06, 2024Transformers have recently gained prominence in long time series forecasting by elevating accuracies in a variety of use cases. Regrettably, in the race for better predictive performance the overhead of model architectures has grown onerous, leading to models with computational demand infeasible for most practical applications. To bridge the gap between high method complexity and realistic computational resources, we introduce the Residual Cyclic Transformer, ReCycle. ReCycle utilizes primary cycle compression to address the computational complexity of the attention mechanism in long time series. By learning residuals from refined smoothing average techniques, ReCycle surpasses state-of-the-art accuracy in a variety of application use cases. The reliable and explainable fallback behavior ensured by simple, yet robust, smoothing average techniques additionally lowers the barrier for user acceptance. At the same time, our approach reduces the run time and energy consumption by more than an order of magnitude, making both training and inference feasible on low-performance, low-power and edge computing devices. Code is available at https://github.com/Helmholtz-AI-Energy/ReCycle
AB-Training: A Communication-Efficient Approach for Distributed Low-Rank Learning
May 02, 2024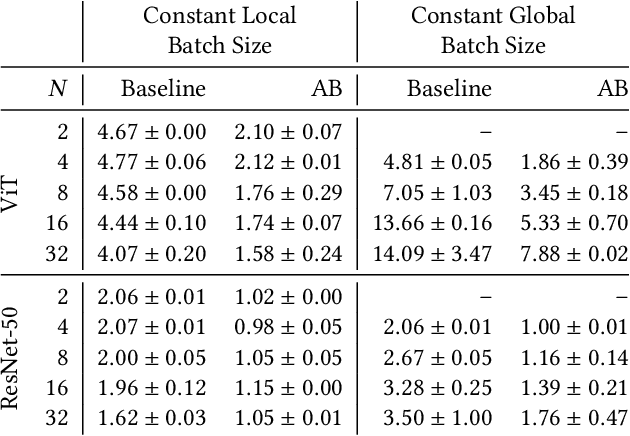
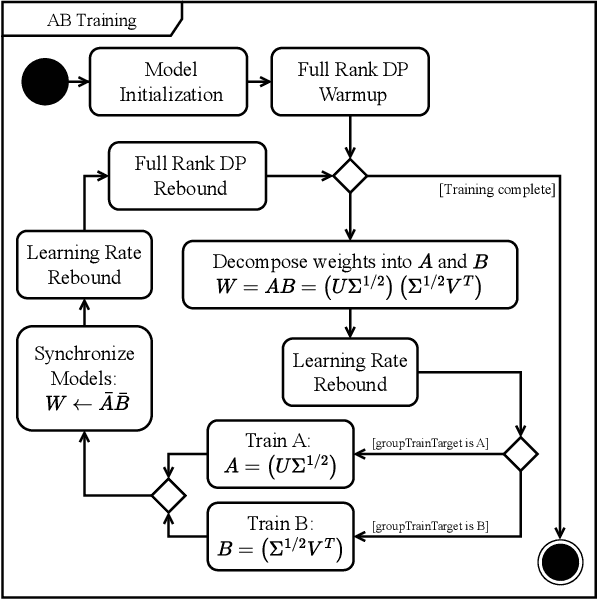
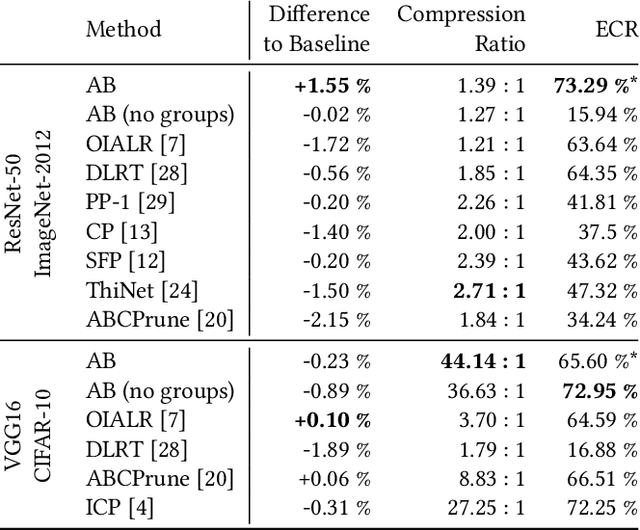
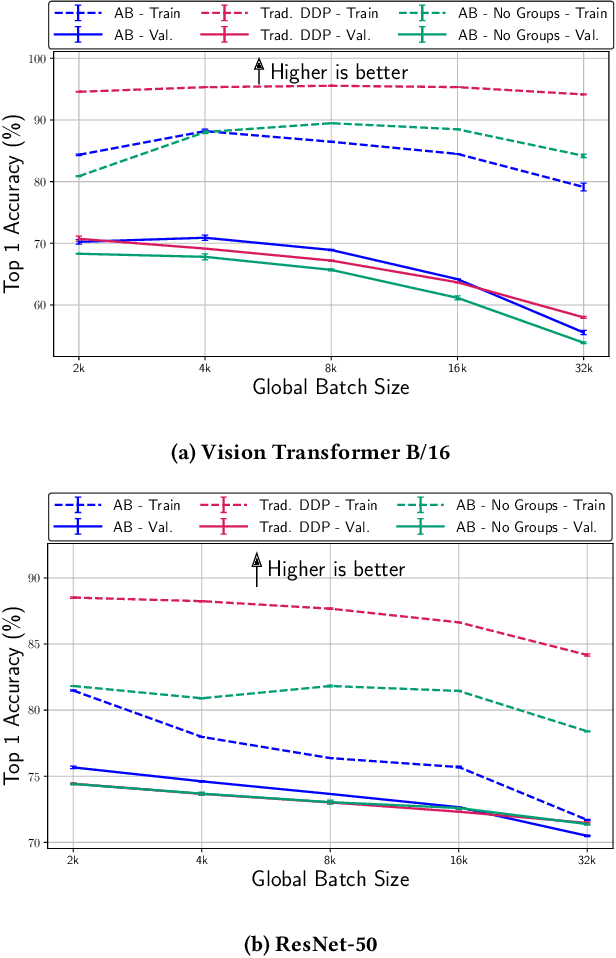
Communication bottlenecks hinder the scalability of distributed neural network training, particularly on distributed-memory computing clusters. To significantly reduce this communication overhead, we introduce AB-training, a novel data-parallel training method that decomposes weight matrices into low-rank representations and utilizes independent group-based training. This approach consistently reduces network traffic by 50% across multiple scaling scenarios, increasing the training potential on communication-constrained systems. Our method exhibits regularization effects at smaller scales, leading to improved generalization for models like VGG16, while achieving a remarkable 44.14 : 1 compression ratio during training on CIFAR-10 and maintaining competitive accuracy. Albeit promising, our experiments reveal that large batch effects remain a challenge even in low-rank training regimes.
Harnessing Orthogonality to Train Low-Rank Neural Networks
Jan 16, 2024



This study explores the learning dynamics of neural networks by analyzing the singular value decomposition (SVD) of their weights throughout training. Our investigation reveals that an orthogonal basis within each multidimensional weight's SVD representation stabilizes during training. Building upon this, we introduce Orthogonality-Informed Adaptive Low-Rank (OIALR) training, a novel training method exploiting the intrinsic orthogonality of neural networks. OIALR seamlessly integrates into existing training workflows with minimal accuracy loss, as demonstrated by benchmarking on various datasets and well-established network architectures. With appropriate hyperparameter tuning, OIALR can surpass conventional training setups, including those of state-of-the-art models.
Feed-Forward Optimization With Delayed Feedback for Neural Networks
Apr 26, 2023Backpropagation has long been criticized for being biologically implausible, relying on concepts that are not viable in natural learning processes. This paper proposes an alternative approach to solve two core issues, i.e., weight transport and update locking, for biological plausibility and computational efficiency. We introduce Feed-Forward with delayed Feedback (F$^3$), which improves upon prior work by utilizing delayed error information as a sample-wise scaling factor to approximate gradients more accurately. We find that F$^3$ reduces the gap in predictive performance between biologically plausible training algorithms and backpropagation by up to 96%. This demonstrates the applicability of biologically plausible training and opens up promising new avenues for low-energy training and parallelization.
Massively Parallel Genetic Optimization through Asynchronous Propagation of Populations
Jan 20, 2023We present Propulate, an evolutionary optimization algorithm and software package for global optimization and in particular hyperparameter search. For efficient use of HPC resources, Propulate omits the synchronization after each generation as done in conventional genetic algorithms. Instead, it steers the search with the complete population present at time of breeding new individuals. We provide an MPI-based implementation of our algorithm, which features variants of selection, mutation, crossover, and migration and is easy to extend with custom functionality. We compare Propulate to the established optimization tool Optuna. We find that Propulate is up to three orders of magnitude faster without sacrificing solution accuracy, demonstrating the efficiency and efficacy of our lazy synchronization approach. Code and documentation are available at https://github.com/Helmholtz-AI-Energy/propulate
Learning Tree Structures from Leaves For Particle Decay Reconstruction
Sep 01, 2022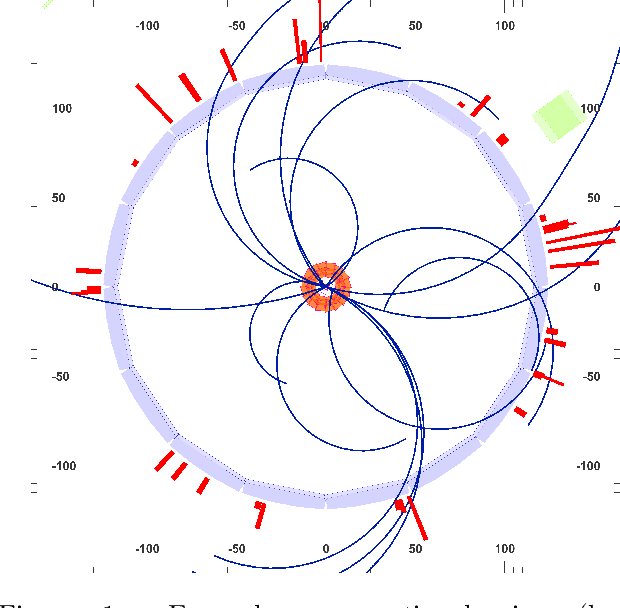
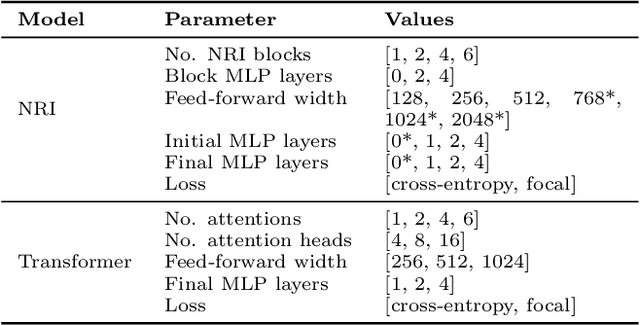
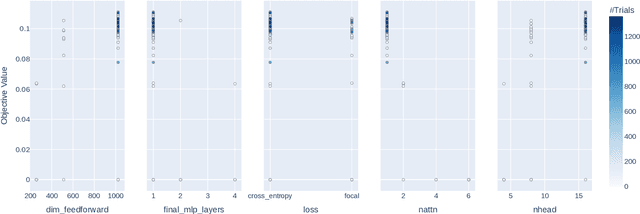

In this work, we present a neural approach to reconstructing rooted tree graphs describing hierarchical interactions, using a novel representation we term the Lowest Common Ancestor Generations (LCAG) matrix. This compact formulation is equivalent to the adjacency matrix, but enables learning a tree's structure from its leaves alone without the prior assumptions required if using the adjacency matrix directly. Employing the LCAG therefore enables the first end-to-end trainable solution which learns the hierarchical structure of varying tree sizes directly, using only the terminal tree leaves to do so. In the case of high-energy particle physics, a particle decay forms a hierarchical tree structure of which only the final products can be observed experimentally, and the large combinatorial space of possible trees makes an analytic solution intractable. We demonstrate the use of the LCAG as a target in the task of predicting simulated particle physics decay structures using both a Transformer encoder and a Neural Relational Inference encoder Graph Neural Network. With this approach, we are able to correctly predict the LCAG purely from leaf features for a maximum tree-depth of $8$ in $92.5\%$ of cases for trees up to $6$ leaves (including) and $59.7\%$ for trees up to $10$ in our simulated dataset.
HyDe: The First Open-Source, Python-Based, GPU-Accelerated Hyperspectral Denoising Package
Apr 14, 2022
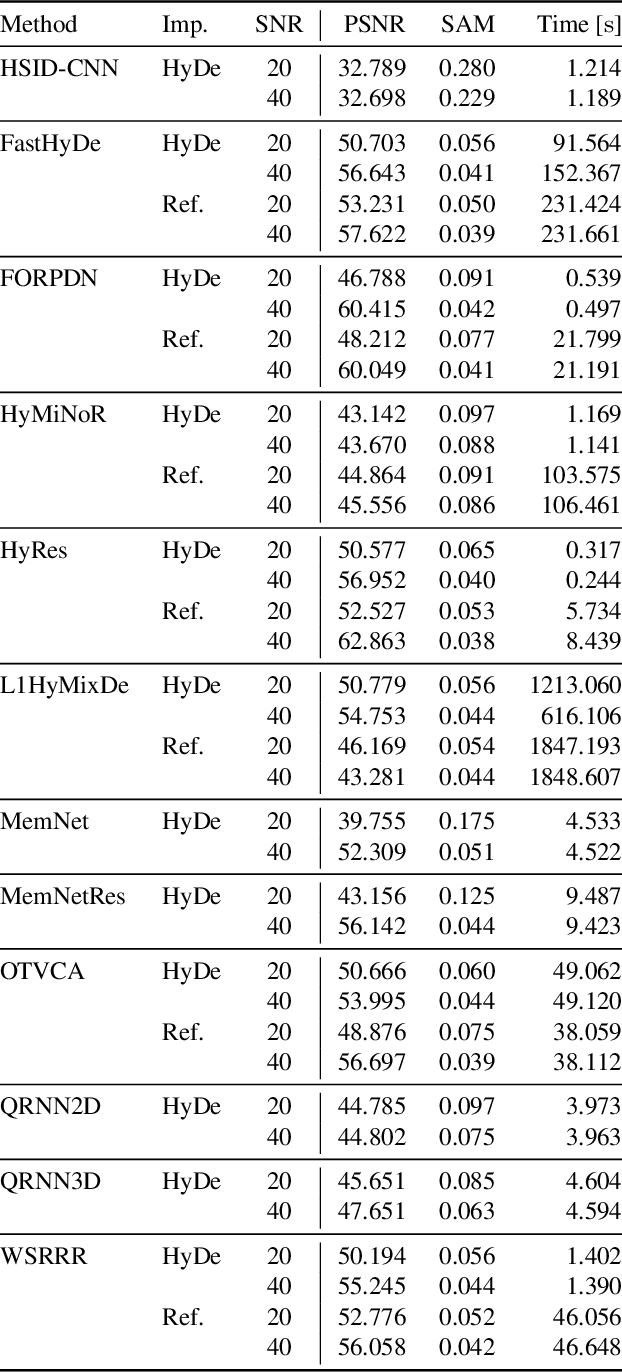
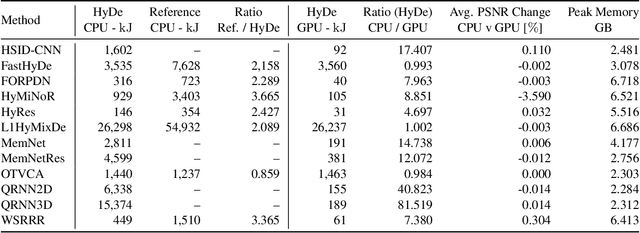
As with any physical instrument, hyperspectral cameras induce different kinds of noise in the acquired data. Therefore, Hyperspectral denoising is a crucial step for analyzing hyperspectral images (HSIs). Conventional computational methods rarely use GPUs to improve efficiency and are not fully open-source. Alternatively, deep learning-based methods are often open-source and use GPUs, but their training and utilization for real-world applications remain non-trivial for many researchers. Consequently, we propose HyDe: the first open-source, GPU-accelerated Python-based, hyperspectral image denoising toolbox, which aims to provide a large set of methods with an easy-to-use environment. HyDe includes a variety of methods ranging from low-rank wavelet-based methods to deep neural network (DNN) models. HyDe's interface dramatically improves the interoperability of these methods and the performance of the underlying functions. In fact, these methods maintain similar HSI denoising performance to their original implementations while consuming nearly ten times less energy. Furthermore, we present a method for training DNNs for denoising HSIs which are not spatially related to the training dataset, i.e., training on ground-level HSIs for denoising HSIs with other perspectives including airborne, drone-borne, and space-borne. To utilize the trained DNNs, we show a sliding window method to effectively denoise HSIs which would otherwise require more than 40 GB. The package can be found at: \url{https://github.com/Helmholtz-AI-Energy/HyDe}.