 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Training with Distributed Asynchronous and Selective Optimization (DASO)
Apr 15, 2021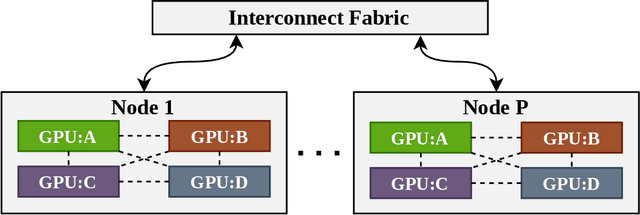
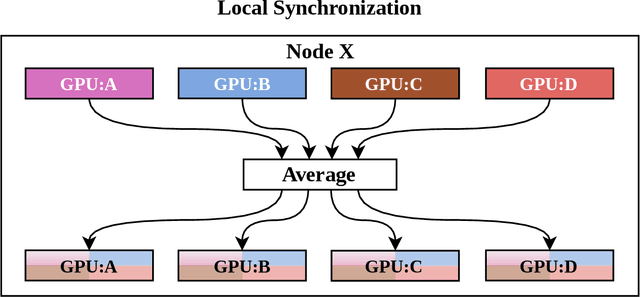

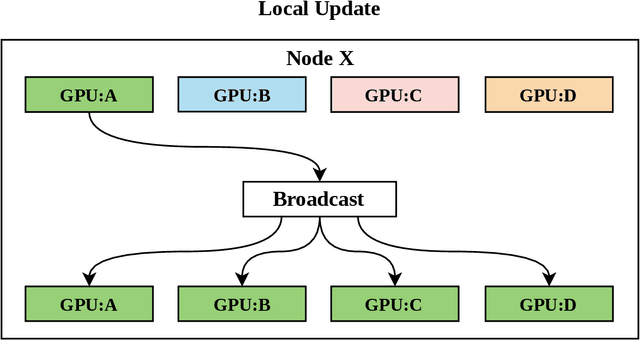
With increasing data and model complexities, the time required to train neural networks has become prohibitively large. To address the exponential rise in training time, users are turning to data parallel neural networks (DPNN) to utilize large-scale distributed resources on computer clusters. Current DPNN approaches implement the network parameter updates by synchronizing and averaging gradients across all processes with blocking communication operations. This synchronization is the central algorithmic bottleneck. To combat this, we introduce the Distributed Asynchronous and Selective Optimization (DASO) method which leverages multi-GPU compute node architectures to accelerate network training. DASO uses a hierarchical and asynchronous communication scheme comprised of node-local and global networks while adjusting the global synchronization rate during the learning process. We show that DASO yields a reduction in training time of up to 34% on classical and state-of-the-art networks, as compared to other existing data parallel training methods.