 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPQ: Automating Quantile estimation from Point forecasts in the context of sustainability
Nov 30, 2024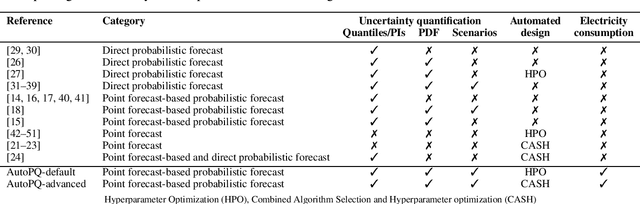
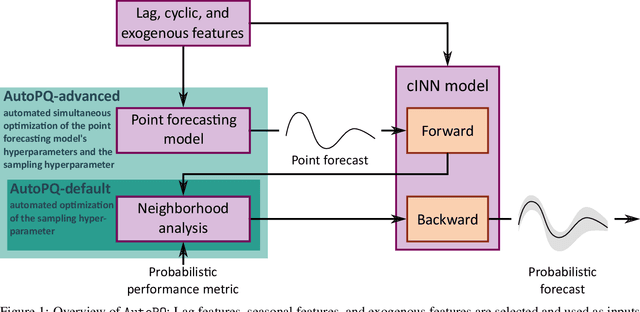
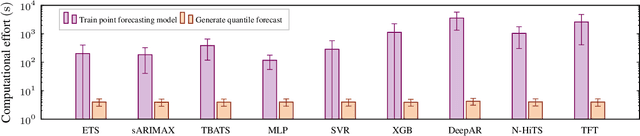
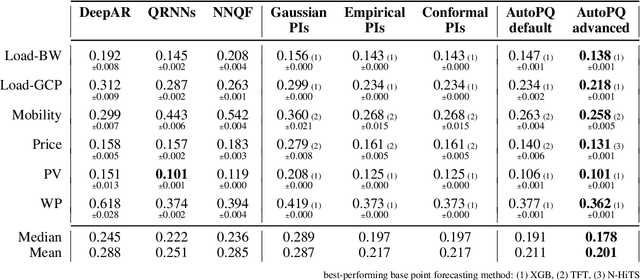
Optimizing smart grid operations relies on critical decision-making informed by uncertainty quantification, making probabilistic forecasting a vital tool. Designing such forecasting models involves three key challenges: accurate and unbiased uncertainty quantification, workload reduction for data scientists during the design process, and limitation of the environmental impact of model training. In order to address these challenges, we introduce AutoPQ, a novel method designed to automate and optimize probabilistic forecasting for smart grid applications. AutoPQ enhances forecast uncertainty quantification by generating quantile forecasts from an existing point forecast by using a conditional Invertible Neural Network (cINN). AutoPQ also automates the selection of the underlying point forecasting method and the optimization of hyperparameters, ensuring that the best model and configuration is chosen for each application. For flexible adaptation to various performance needs and available computing power, AutoPQ comes with a default and an advanced configuration, making it suitable for a wide range of smart grid applications. Additionally, AutoPQ provides transparency regarding the electricity consumption required for performance improvements. We show that AutoPQ outperforms state-of-the-art probabilistic forecasting methods while effectively limiting computational effort and hence environmental impact. Additionally and in the context of sustainability, we quantify the electricity consumption required for performance improvements.
Beyond Backpropagation: Optimization with Multi-Tangent Forward Gradients
Oct 23, 2024The gradients used to train neural networks are typically computed using backpropagation. While an efficient way to obtain exact gradients, backpropagation is computationally expensive, hinders parallelization, and is biologically implausible. Forward gradients are an approach to approximate the gradients from directional derivatives along random tangents computed by forward-mode automatic differentiation. So far, research has focused on using a single tangent per step. This paper provides an in-depth analysis of multi-tangent forward gradients and introduces an improved approach to combining the forward gradients from multiple tangents based on orthogonal projections. We demonstrate that increasing the number of tangents improves both approximation quality and optimization performance across various tasks.
AB-Training: A Communication-Efficient Approach for Distributed Low-Rank Learning
May 02, 2024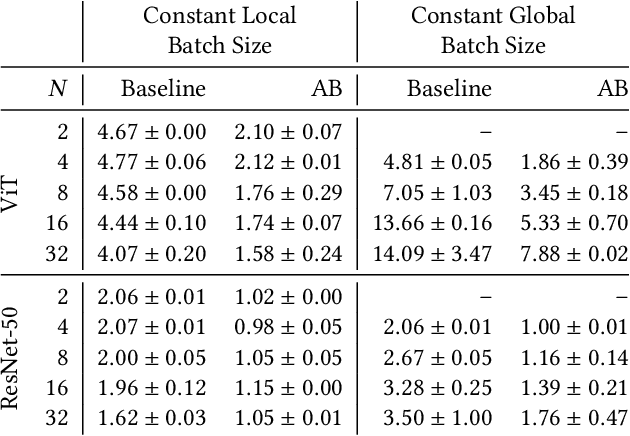
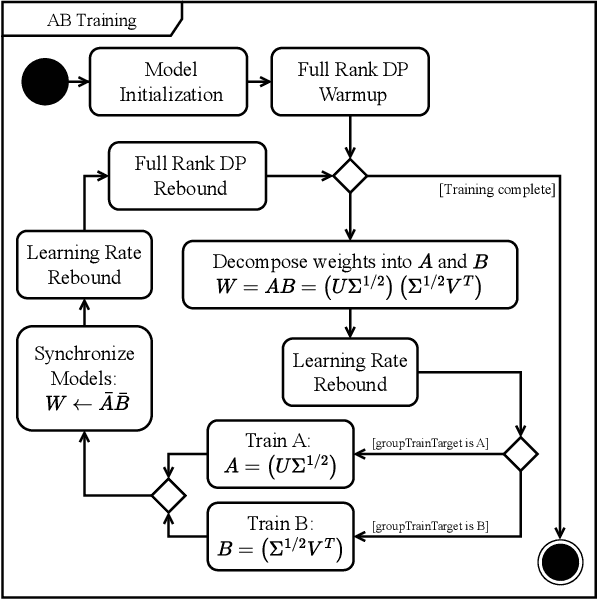
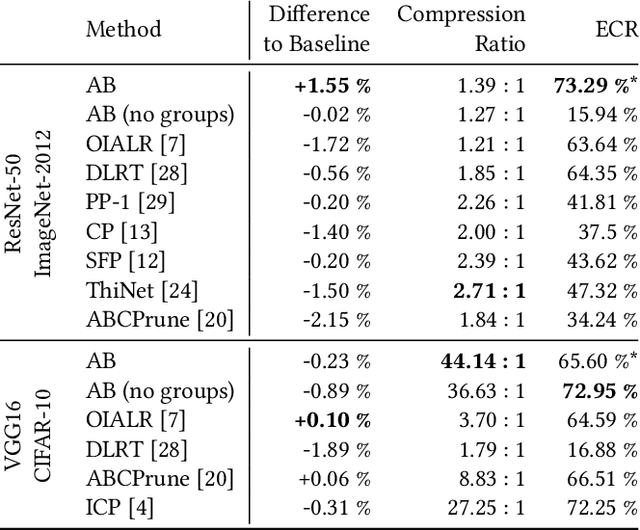
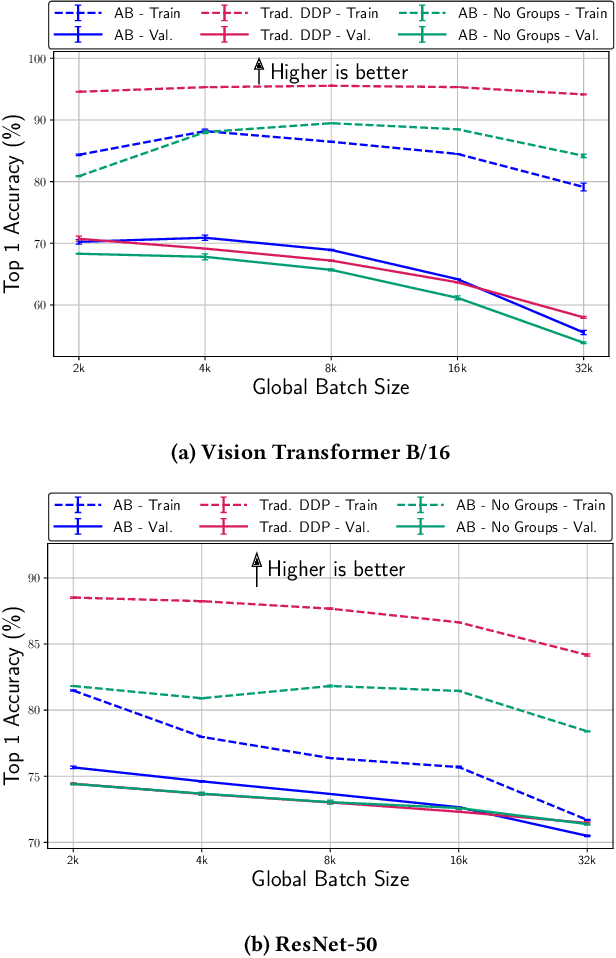
Communication bottlenecks hinder the scalability of distributed neural network training, particularly on distributed-memory computing clusters. To significantly reduce this communication overhead, we introduce AB-training, a novel data-parallel training method that decomposes weight matrices into low-rank representations and utilizes independent group-based training. This approach consistently reduces network traffic by 50% across multiple scaling scenarios, increasing the training potential on communication-constrained systems. Our method exhibits regularization effects at smaller scales, leading to improved generalization for models like VGG16, while achieving a remarkable 44.14 : 1 compression ratio during training on CIFAR-10 and maintaining competitive accuracy. Albeit promising, our experiments reveal that large batch effects remain a challenge even in low-rank training regimes.
Harnessing Orthogonality to Train Low-Rank Neural Networks
Jan 16, 2024



This study explores the learning dynamics of neural networks by analyzing the singular value decomposition (SVD) of their weights throughout training. Our investigation reveals that an orthogonal basis within each multidimensional weight's SVD representation stabilizes during training. Building upon this, we introduce Orthogonality-Informed Adaptive Low-Rank (OIALR) training, a novel training method exploiting the intrinsic orthogonality of neural networks. OIALR seamlessly integrates into existing training workflows with minimal accuracy loss, as demonstrated by benchmarking on various datasets and well-established network architectures. With appropriate hyperparameter tuning, OIALR can surpass conventional training setups, including those of state-of-the-art models.
Feed-Forward Optimization With Delayed Feedback for Neural Networks
Apr 26, 2023Backpropagation has long been criticized for being biologically implausible, relying on concepts that are not viable in natural learning processes. This paper proposes an alternative approach to solve two core issues, i.e., weight transport and update locking, for biological plausibility and computational efficiency. We introduce Feed-Forward with delayed Feedback (F$^3$), which improves upon prior work by utilizing delayed error information as a sample-wise scaling factor to approximate gradients more accurately. We find that F$^3$ reduces the gap in predictive performance between biologically plausible training algorithms and backpropagation by up to 96%. This demonstrates the applicability of biologically plausible training and opens up promising new avenues for low-energy training and parallelization.
Massively Parallel Genetic Optimization through Asynchronous Propagation of Populations
Jan 20, 2023We present Propulate, an evolutionary optimization algorithm and software package for global optimization and in particular hyperparameter search. For efficient use of HPC resources, Propulate omits the synchronization after each generation as done in conventional genetic algorithms. Instead, it steers the search with the complete population present at time of breeding new individuals. We provide an MPI-based implementation of our algorithm, which features variants of selection, mutation, crossover, and migration and is easy to extend with custom functionality. We compare Propulate to the established optimization tool Optuna. We find that Propulate is up to three orders of magnitude faster without sacrificing solution accuracy, demonstrating the efficiency and efficacy of our lazy synchronization approach. Code and documentation are available at https://github.com/Helmholtz-AI-Energy/propulate