 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPQ: Automating Quantile estimation from Point forecasts in the context of sustainability
Nov 30, 2024Optimizing smart grid operations relies on critical decision-making informed by uncertainty quantification, making probabilistic forecasting a vital tool. Designing such forecasting models involves three key challenges: accurate and unbiased uncertainty quantification, workload reduction for data scientists during the design process, and limitation of the environmental impact of model training. In order to address these challenges, we introduce AutoPQ, a novel method designed to automate and optimize probabilistic forecasting for smart grid applications. AutoPQ enhances forecast uncertainty quantification by generating quantile forecasts from an existing point forecast by using a conditional Invertible Neural Network (cINN). AutoPQ also automates the selection of the underlying point forecasting method and the optimization of hyperparameters, ensuring that the best model and configuration is chosen for each application. For flexible adaptation to various performance needs and available computing power, AutoPQ comes with a default and an advanced configuration, making it suitable for a wide range of smart grid applications. Additionally, AutoPQ provides transparency regarding the electricity consumption required for performance improvements. We show that AutoPQ outperforms state-of-the-art probabilistic forecasting methods while effectively limiting computational effort and hence environmental impact. Additionally and in the context of sustainability, we quantify the electricity consumption required for performance improvements.
On autoregressive deep learning models for day-ahead wind power forecasting with irregular shutdowns due to redispatching
Nov 30, 2024Renewable energies and their operation are becoming increasingly vital for the stability of electrical power grids since conventional power plants are progressively being displaced, and their contribution to redispatch interventions is thereby diminishing. In order to consider renewable energies like Wind Power (WP) for such interventions as a substitute, day-ahead forecasts are necessary to communicate their availability for redispatch planning. In this context, automated and scalable forecasting models are required for the deployment to thousands of locally-distributed onshore WP turbines. Furthermore, the irregular interventions into the WP generation capabilities due to redispatch shutdowns pose challenges in the design and operation of WP forecasting models. Since state-of-the-art forecasting methods consider past WP generation values alongside day-ahead weather forecasts, redispatch shutdowns may impact the forecast. Therefore, the present paper highlights these challenges and analyzes state-of-the-art forecasting methods on data sets with both regular and irregular shutdowns. Specifically, we compare the forecasting accuracy of three autoregressive Deep Learning (DL) methods to methods based on WP curve modeling. Interestingly, the latter achieve lower forecasting errors, have fewer requirements for data cleaning during modeling and operation while being computationally more efficient, suggesting their advantages in practical applications.
AutoPV: Automated photovoltaic forecasts with limited information using an ensemble of pre-trained models
Dec 13, 2022Accurate PhotoVoltaic (PV) power generation forecasting is vital for the efficient operation of Smart Grids. The automated design of such accurate forecasting models for individual PV plants includes two challenges: First, information about the PV mounting configuration (i.e. inclination and azimuth angles) is often missing. Second, for new PV plants, the amount of historical data available to train a forecasting model is limited (cold-start problem). We address these two challenges by proposing a new method for day-ahead PV power generation forecasts called AutoPV. AutoPV is a weighted ensemble of forecasting models that represent different PV mounting configurations. This representation is achieved by pre-training each forecasting model on a separate PV plant and by scaling the model's output with the peak power rating of the corresponding PV plant. To tackle the cold-start problem, we initially weight each forecasting model in the ensemble equally. To tackle the problem of missing information about the PV mounting configuration, we use new data that become available during operation to adapt the ensemble weights to minimize the forecasting error. AutoPV is advantageous as the unknown PV mounting configuration is implicitly reflected in the ensemble weights, and only the PV plant's peak power rating is required to re-scale the ensemble's output. AutoPV also allows to represent PV plants with panels distributed on different roofs with varying alignments, as these mounting configurations can be reflected proportionally in the weighting. Additionally, the required computing memory is decoupled when scaling AutoPV to hundreds of PV plants, which is beneficial in Smart Grids with limited computing capabilities. For a real-world data set with 11 PV plants, the accuracy of AutoPV is comparable to a model trained on two years of data and outperforms an incrementally trained model.
Review of automated time series forecasting pipelines
Feb 03, 2022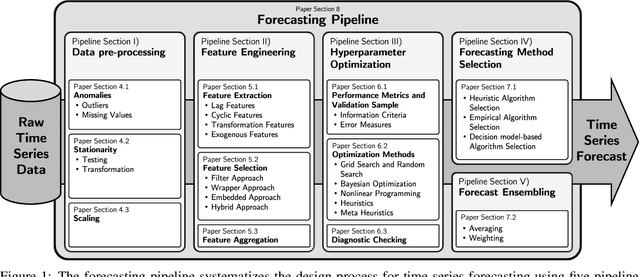

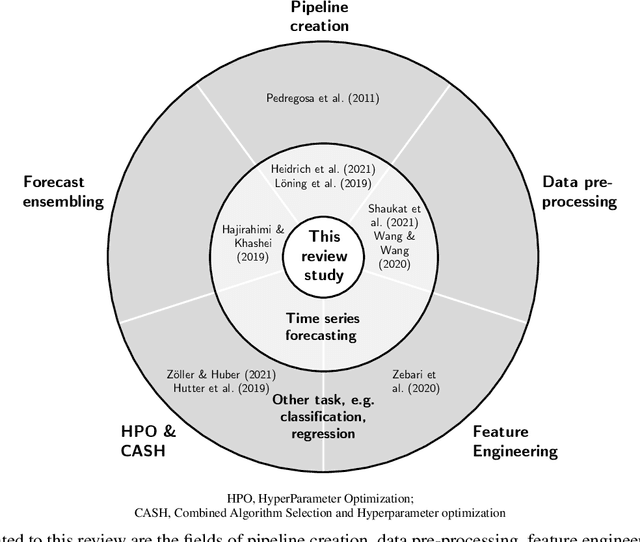
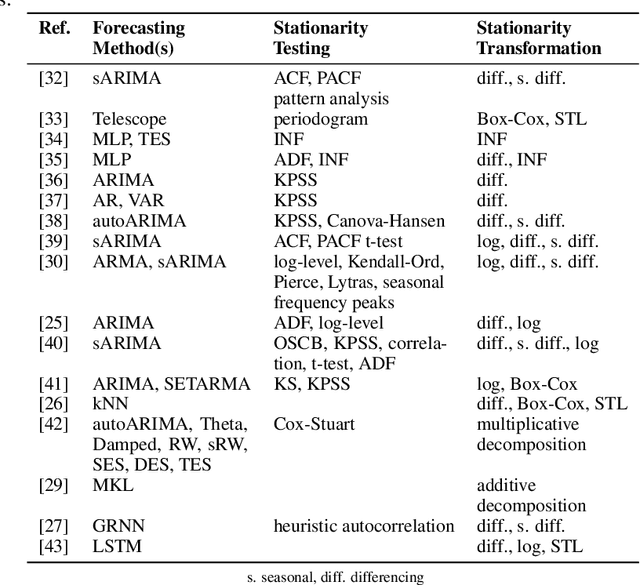
Time series forecasting is fundamental for various use cases in different domains such as energy systems and economics. Creating a forecasting model for a specific use case requires an iterative and complex design process. The typical design process includes the five sections (1) data pre-processing, (2) feature engineering, (3) hyperparameter optimization, (4) forecasting method selection, and (5) forecast ensembling, which are commonly organized in a pipeline structure. One promising approach to handle the ever-growing demand for time series forecasts is automating this design process. The present paper, thus, analyzes the existing literature on automated time series forecasting pipelines to investigate how to automate the design process of forecasting models. Thereby, we consider both Automated Machine Learning (AutoML) and automated statistical forecasting methods in a single forecasting pipeline. For this purpose, we firstly present and compare the proposed automation methods for each pipeline section. Secondly, we analyze the automation methods regarding their interaction, combination, and coverage of the five pipeline sections. For both, we discuss the literature, identify problems, give recommendations, and suggest future research. This review reveals that the majority of papers only cover two or three of the five pipeline sections. We conclude that future research has to holistically consider the automation of the forecasting pipeline to enable the large-scale application of time series forecasting.
Concepts for Automated Machine Learning in Smart Grid Applications
Oct 26, 2021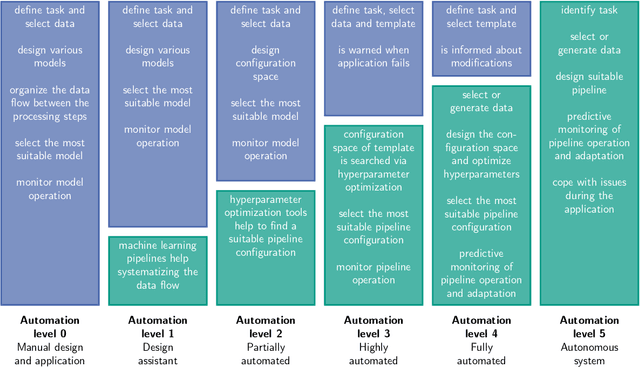
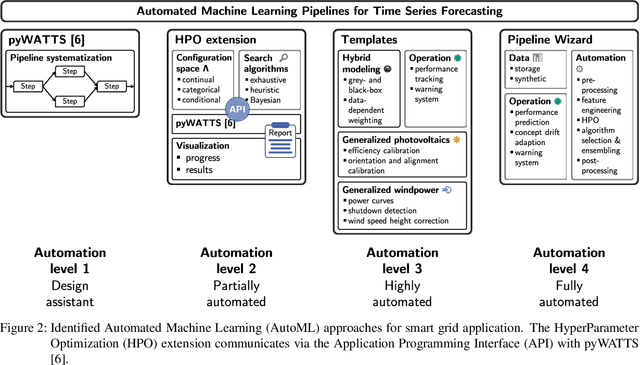
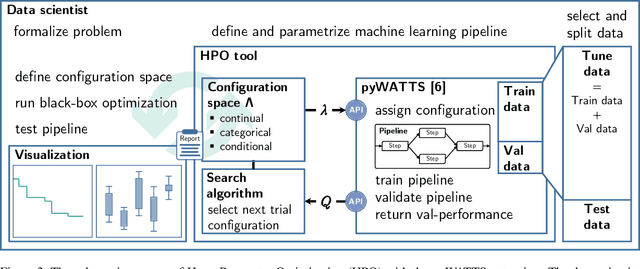
Undoubtedly, the increase of available data and competitive machine learning algorithms has boosted the popularity of data-driven modeling in energy systems. Applications are forecasts for renewable energy generation and energy consumption. Forecasts are elementary for sector coupling, where energy-consuming sectors are interconnected with the power-generating sector to address electricity storage challenges by adding flexibility to the power system. However, the large-scale application of machine learning methods in energy systems is impaired by the need for expert knowledge, which covers machine learning expertise and a profound understanding of the application's process. The process knowledge is required for the problem formalization, as well as the model validation and application. The machine learning skills include the processing steps of i) data pre-processing, ii) feature engineering, extraction, and selection, iii) algorithm selection, iv) hyperparameter optimization, and possibly v) post-processing of the model's output. Tailoring a model for a particular application requires selecting the data, designing various candidate models and organizing the data flow between the processing steps, selecting the most suitable model, and monitoring the model during operation - an iterative and time-consuming procedure. Automated design and operation of machine learning aim to reduce the human effort to address the increasing demand for data-driven models. We define five levels of automation for forecasting in alignment with the SAE standard for autonomous vehicles, where manual design and application reflect Automation level 0.
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021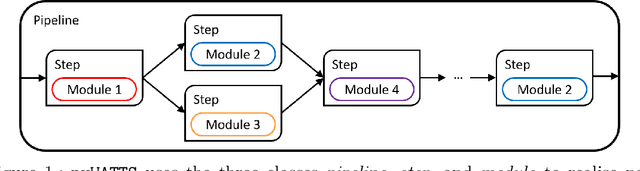
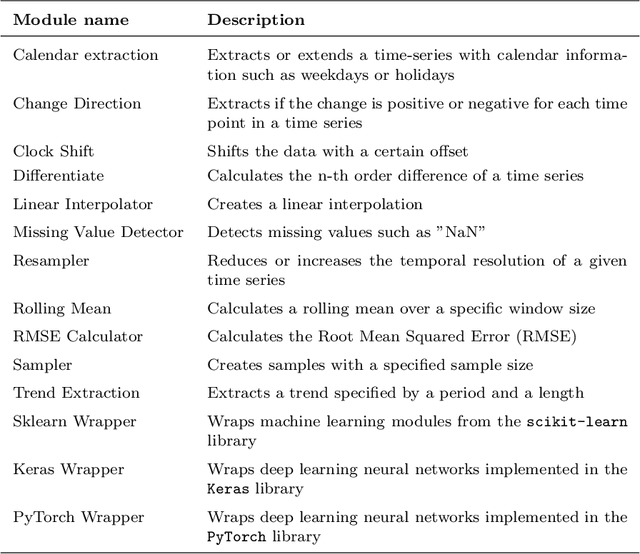
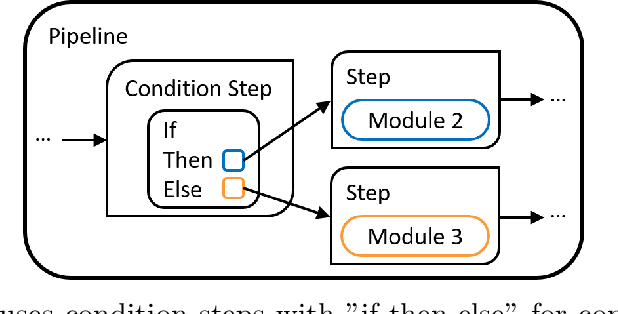
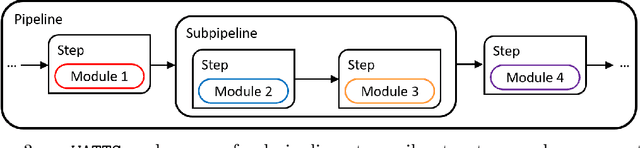
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.