 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Power-Flow Optimization
Mar 30, 2026With the rise of renewable energy sources and their high variability in generation, the management of power grids becomes increasingly complex and computationally demanding. Conventional AC-power-flow simulations, which use the Newton-Raphson (NR) method, suffer from poor scalability, making them impractical for emerging use cases such as joint transmission-distribution modeling and global grid analysis. At the same time, purely data-driven surrogate models lack physical guarantees and may violate fundamental constraints. In this work, we propose Differentiable Power-Flow (DPF), a reformulation of the AC power-flow problem as a differentiable simulation. DPF enables end-to-end gradient propagation from the physical power mismatches to the underlying simulation parameters, thereby allowing these parameters to be identified efficiently using gradient-based optimization. We demonstrate that DPF provides a scalable alternative to NR by leveraging GPU acceleration, sparse tensor representations, and batching capabilities available in modern machine-learning frameworks such as PyTorch. DPF is especially suited as a tool for time-series analyses due to its efficient reuse of previous solutions, for N-1 contingency-analyses due to its ability to process cases in batches, and as a screening tool by leveraging its speed and early stopping capability. The code is available in the authors' code repository.
Decision-Focused Fine-Tuning of Time Series Foundation Models for Dispatchable Feeder Optimization
Mar 03, 2025Time series foundation models provide a universal solution for generating forecasts to support optimization problems in energy systems. Those foundation models are typically trained in a prediction-focused manner to maximize forecast quality. In contrast, decision-focused learning directly improves the resulting value of the forecast in downstream optimization rather than merely maximizing forecasting quality. The practical integration of forecast values into forecasting models is challenging, particularly when addressing complex applications with diverse instances, such as buildings. This becomes even more complicated when instances possess specific characteristics that require instance-specific, tailored predictions to increase the forecast value. To tackle this challenge, we use decision-focused fine-tuning within time series foundation models to offer a scalable and efficient solution for decision-focused learning applied to the dispatchable feeder optimization problem. To obtain more robust predictions for scarce building data, we use Moirai as a state-of-the-art foundation model, which offers robust and generalized results with few-shot parameter-efficient fine-tuning. Comparing the decision-focused fine-tuned Moirai with a state-of-the-art classical prediction-focused fine-tuning Morai, we observe an improvement of 9.45% in average total daily costs.
AutoPQ: Automating Quantile estimation from Point forecasts in the context of sustainability
Nov 30, 2024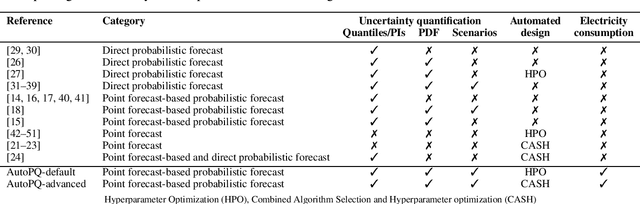
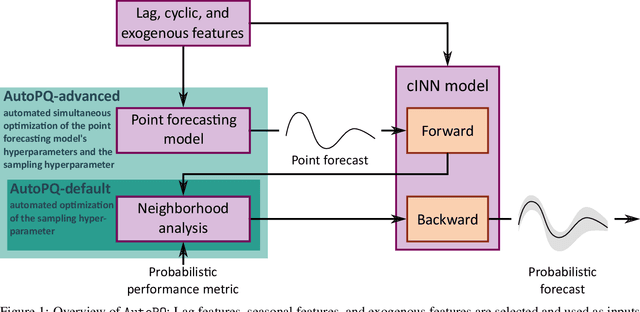
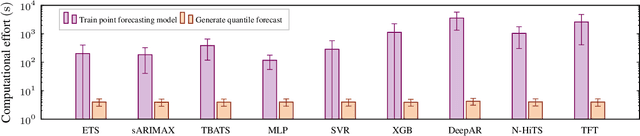
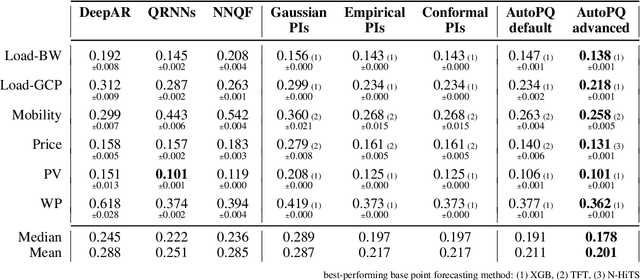
Optimizing smart grid operations relies on critical decision-making informed by uncertainty quantification, making probabilistic forecasting a vital tool. Designing such forecasting models involves three key challenges: accurate and unbiased uncertainty quantification, workload reduction for data scientists during the design process, and limitation of the environmental impact of model training. In order to address these challenges, we introduce AutoPQ, a novel method designed to automate and optimize probabilistic forecasting for smart grid applications. AutoPQ enhances forecast uncertainty quantification by generating quantile forecasts from an existing point forecast by using a conditional Invertible Neural Network (cINN). AutoPQ also automates the selection of the underlying point forecasting method and the optimization of hyperparameters, ensuring that the best model and configuration is chosen for each application. For flexible adaptation to various performance needs and available computing power, AutoPQ comes with a default and an advanced configuration, making it suitable for a wide range of smart grid applications. Additionally, AutoPQ provides transparency regarding the electricity consumption required for performance improvements. We show that AutoPQ outperforms state-of-the-art probabilistic forecasting methods while effectively limiting computational effort and hence environmental impact. Additionally and in the context of sustainability, we quantify the electricity consumption required for performance improvements.
ProbPNN: Enhancing Deep Probabilistic Forecasting with Statistical Information
Feb 06, 2023



Probabilistic forecasts are essential for various downstream applications such as business development, traffic planning, and electrical grid balancing. Many of these probabilistic forecasts are performed on time series data that contain calendar-driven periodicities. However, existing probabilistic forecasting methods do not explicitly take these periodicities into account. Therefore, in the present paper, we introduce a deep learning-based method that considers these calendar-driven periodicities explicitly. The present paper, thus, has a twofold contribution: First, we apply statistical methods that use calendar-driven prior knowledge to create rolling statistics and combine them with neural networks to provide better probabilistic forecasts. Second, we benchmark ProbPNN with state-of-the-art benchmarks by comparing the achieved normalised continuous ranked probability score (nCRPS) and normalised Pinball Loss (nPL) on two data sets containing in total more than 1000 time series. The results of the benchmarks show that using statistical forecasting components improves the probabilistic forecast performance and that ProbPNN outperforms other deep learning forecasting methods whilst requiring less computation costs.
Creating Probabilistic Forecasts from Arbitrary Deterministic Forecasts using Conditional Invertible Neural Networks
Feb 03, 2023



In various applications, probabilistic forecasts are required to quantify the inherent uncertainty associated with the forecast. However, numerous modern forecasting methods are still designed to create deterministic forecasts. Transforming these deterministic forecasts into probabilistic forecasts is often challenging and based on numerous assumptions that may not hold in real-world situations. Therefore, the present article proposes a novel approach for creating probabilistic forecasts from arbitrary deterministic forecasts. In order to implement this approach, we use a conditional Invertible Neural Network (cINN). More specifically, we apply a cINN to learn the underlying distribution of the data and then combine the uncertainty from this distribution with an arbitrary deterministic forecast to generate accurate probabilistic forecasts. Our approach enables the simple creation of probabilistic forecasts without complicated statistical loss functions or further assumptions. Besides showing the mathematical validity of our approach, we empirically show that our approach noticeably outperforms traditional methods for including uncertainty in deterministic forecasts and generally outperforms state-of-the-art probabilistic forecasting benchmarks.
Review of automated time series forecasting pipelines
Feb 03, 2022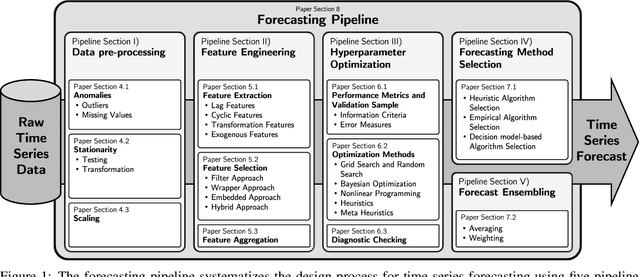

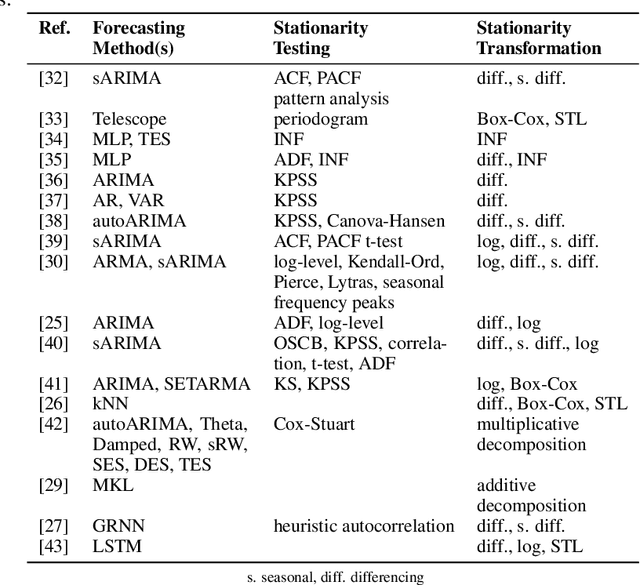
Time series forecasting is fundamental for various use cases in different domains such as energy systems and economics. Creating a forecasting model for a specific use case requires an iterative and complex design process. The typical design process includes the five sections (1) data pre-processing, (2) feature engineering, (3) hyperparameter optimization, (4) forecasting method selection, and (5) forecast ensembling, which are commonly organized in a pipeline structure. One promising approach to handle the ever-growing demand for time series forecasts is automating this design process. The present paper, thus, analyzes the existing literature on automated time series forecasting pipelines to investigate how to automate the design process of forecasting models. Thereby, we consider both Automated Machine Learning (AutoML) and automated statistical forecasting methods in a single forecasting pipeline. For this purpose, we firstly present and compare the proposed automation methods for each pipeline section. Secondly, we analyze the automation methods regarding their interaction, combination, and coverage of the five pipeline sections. For both, we discuss the literature, identify problems, give recommendations, and suggest future research. This review reveals that the majority of papers only cover two or three of the five pipeline sections. We conclude that future research has to holistically consider the automation of the forecasting pipeline to enable the large-scale application of time series forecasting.
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021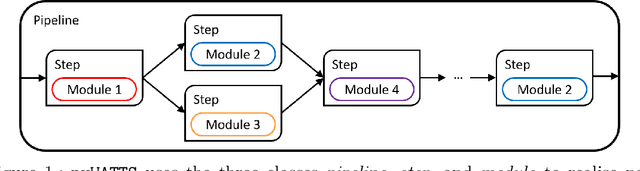
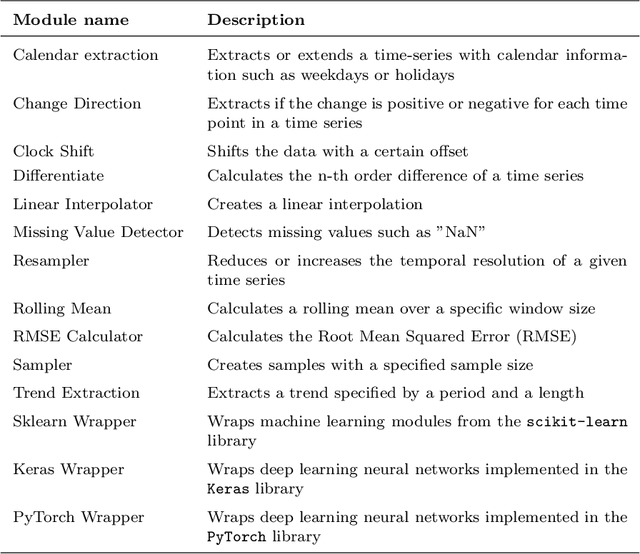
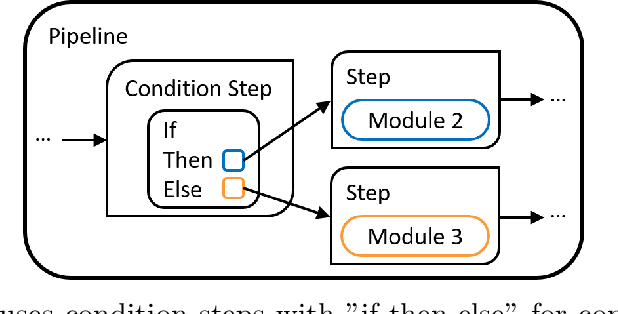
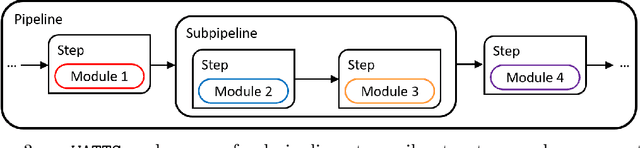
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.