 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbPNN: Enhancing Deep Probabilistic Forecasting with Statistical Information
Feb 06, 2023



Probabilistic forecasts are essential for various downstream applications such as business development, traffic planning, and electrical grid balancing. Many of these probabilistic forecasts are performed on time series data that contain calendar-driven periodicities. However, existing probabilistic forecasting methods do not explicitly take these periodicities into account. Therefore, in the present paper, we introduce a deep learning-based method that considers these calendar-driven periodicities explicitly. The present paper, thus, has a twofold contribution: First, we apply statistical methods that use calendar-driven prior knowledge to create rolling statistics and combine them with neural networks to provide better probabilistic forecasts. Second, we benchmark ProbPNN with state-of-the-art benchmarks by comparing the achieved normalised continuous ranked probability score (nCRPS) and normalised Pinball Loss (nPL) on two data sets containing in total more than 1000 time series. The results of the benchmarks show that using statistical forecasting components improves the probabilistic forecast performance and that ProbPNN outperforms other deep learning forecasting methods whilst requiring less computation costs.
Creating Probabilistic Forecasts from Arbitrary Deterministic Forecasts using Conditional Invertible Neural Networks
Feb 03, 2023



In various applications, probabilistic forecasts are required to quantify the inherent uncertainty associated with the forecast. However, numerous modern forecasting methods are still designed to create deterministic forecasts. Transforming these deterministic forecasts into probabilistic forecasts is often challenging and based on numerous assumptions that may not hold in real-world situations. Therefore, the present article proposes a novel approach for creating probabilistic forecasts from arbitrary deterministic forecasts. In order to implement this approach, we use a conditional Invertible Neural Network (cINN). More specifically, we apply a cINN to learn the underlying distribution of the data and then combine the uncertainty from this distribution with an arbitrary deterministic forecast to generate accurate probabilistic forecasts. Our approach enables the simple creation of probabilistic forecasts without complicated statistical loss functions or further assumptions. Besides showing the mathematical validity of our approach, we empirically show that our approach noticeably outperforms traditional methods for including uncertainty in deterministic forecasts and generally outperforms state-of-the-art probabilistic forecasting benchmarks.
ALDI++: Automatic and parameter-less discord and outlier detection for building energy load profiles
Mar 13, 2022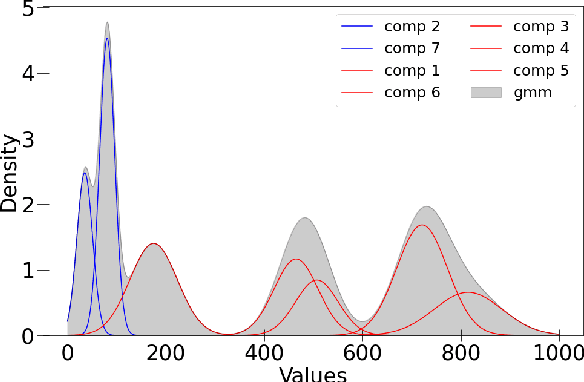
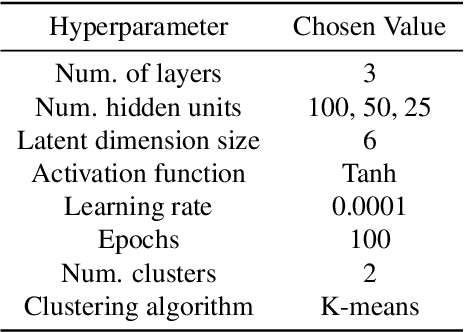
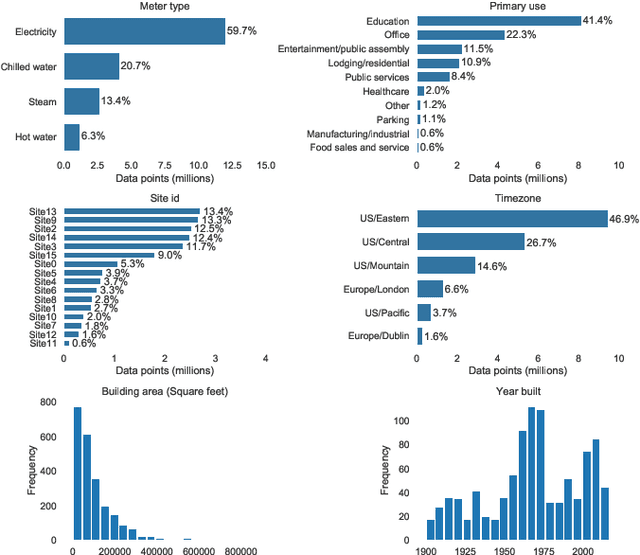
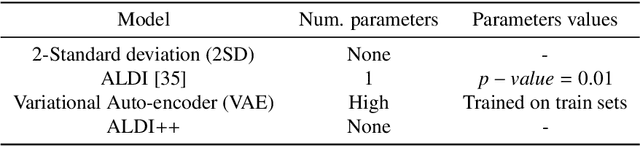
Data-driven building energy prediction is an integral part of the process for measurement and verification, building benchmarking, and building-to-grid interaction. The ASHRAE Great Energy Predictor III (GEPIII) machine learning competition used an extensive meter data set to crowdsource the most accurate machine learning workflow for whole building energy prediction. A significant component of the winning solutions was the pre-processing phase to remove anomalous training data. Contemporary pre-processing methods focus on filtering statistical threshold values or deep learning methods requiring training data and multiple hyper-parameters. A recent method named ALDI (Automated Load profile Discord Identification) managed to identify these discords using matrix profile, but the technique still requires user-defined parameters. We develop ALDI++, a method based on the previous work that bypasses user-defined parameters and takes advantage of discord similarity. We evaluate ALDI++ against a statistical threshold, variational auto-encoder, and the original ALDI as baselines in classifying discords and energy forecasting scenarios. Our results demonstrate that while the classification performance improvement over the original method is marginal, ALDI++ helps achieve the best forecasting error improving 6% over the winning's team approach with six times less computation time.
Review of automated time series forecasting pipelines
Feb 03, 2022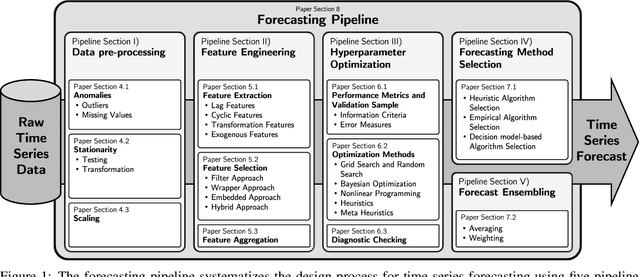

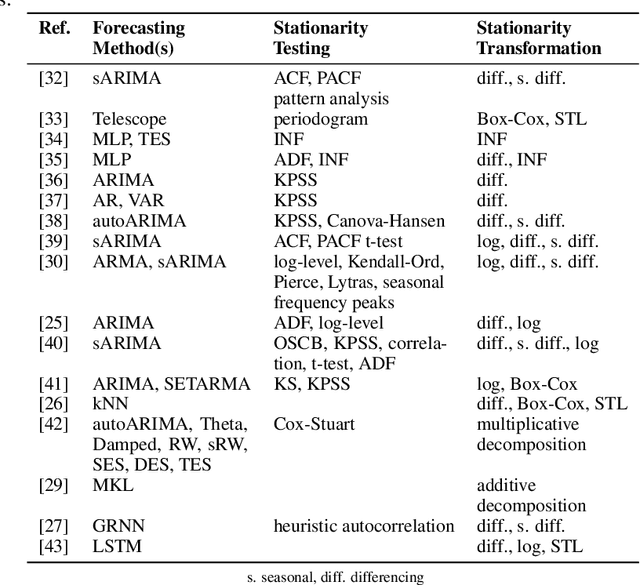
Time series forecasting is fundamental for various use cases in different domains such as energy systems and economics. Creating a forecasting model for a specific use case requires an iterative and complex design process. The typical design process includes the five sections (1) data pre-processing, (2) feature engineering, (3) hyperparameter optimization, (4) forecasting method selection, and (5) forecast ensembling, which are commonly organized in a pipeline structure. One promising approach to handle the ever-growing demand for time series forecasts is automating this design process. The present paper, thus, analyzes the existing literature on automated time series forecasting pipelines to investigate how to automate the design process of forecasting models. Thereby, we consider both Automated Machine Learning (AutoML) and automated statistical forecasting methods in a single forecasting pipeline. For this purpose, we firstly present and compare the proposed automation methods for each pipeline section. Secondly, we analyze the automation methods regarding their interaction, combination, and coverage of the five pipeline sections. For both, we discuss the literature, identify problems, give recommendations, and suggest future research. This review reveals that the majority of papers only cover two or three of the five pipeline sections. We conclude that future research has to holistically consider the automation of the forecasting pipeline to enable the large-scale application of time series forecasting.
Smart Data Representations: Impact on the Accuracy of Deep Neural Networks
Nov 17, 2021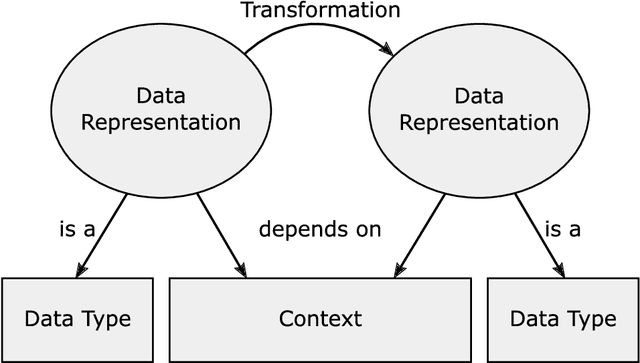


Deep Neural Networks are able to solve many complex tasks with less engineering effort and better performance. However, these networks often use data for training and evaluation without investigating its representation, i.e.~the form of the used data. In the present paper, we analyze the impact of data representations on the performance of Deep Neural Networks using energy time series forecasting. Based on an overview of exemplary data representations, we select four exemplary data representations and evaluate them using two different Deep Neural Network architectures and three forecasting horizons on real-world energy time series. The results show that, depending on the forecast horizon, the same data representations can have a positive or negative impact on the accuracy of Deep Neural Networks.
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021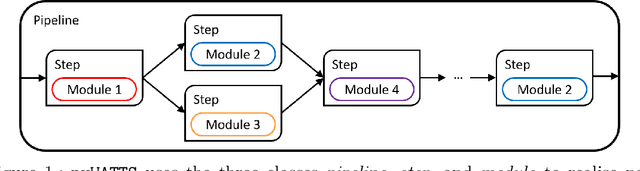
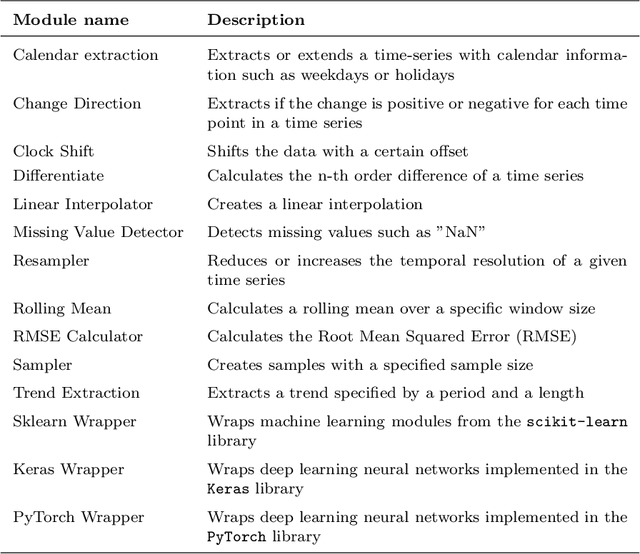
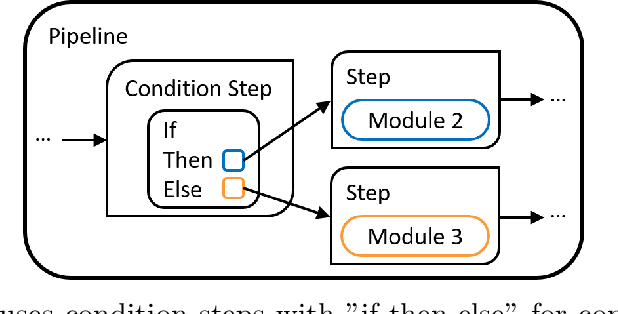
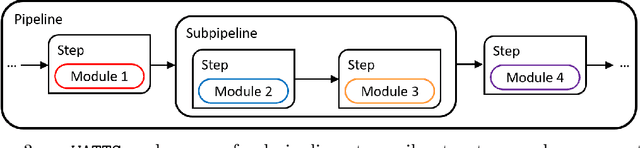
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.
Data-Driven Copy-Paste Imputation for Energy Time Series
Jan 05, 2021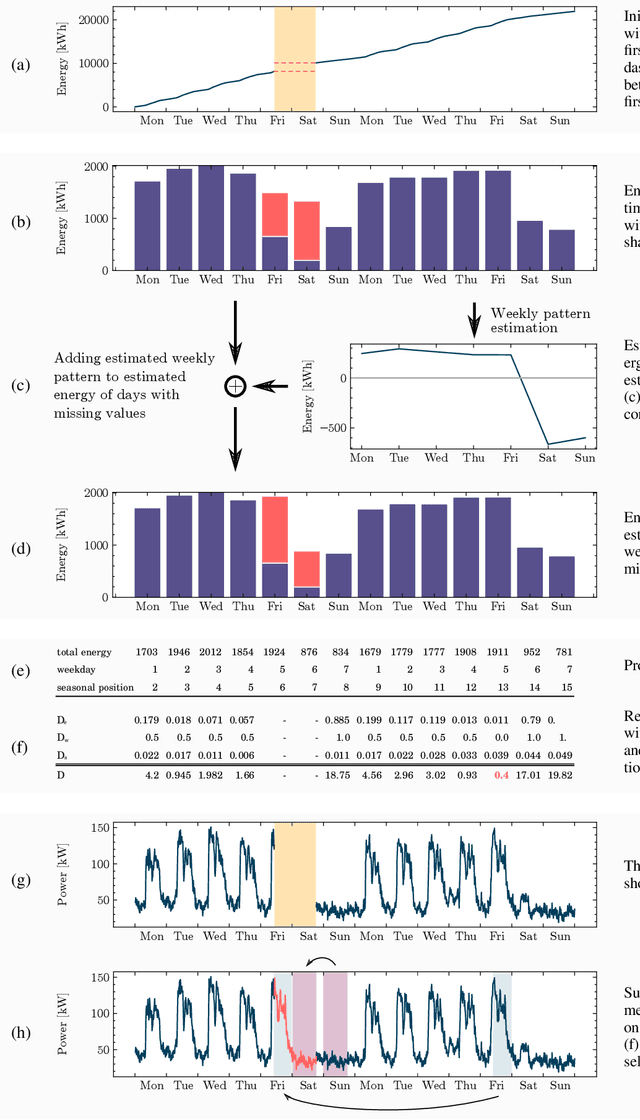
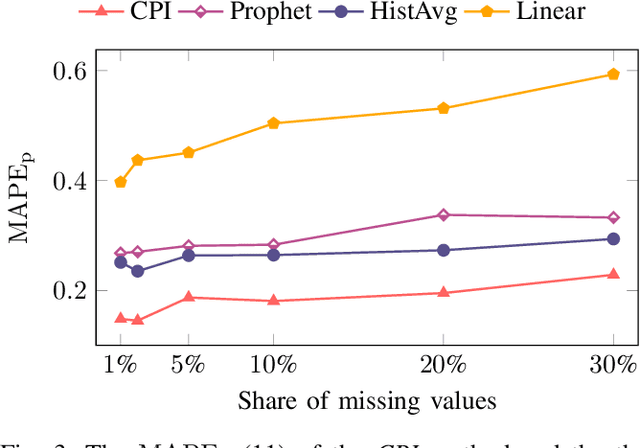
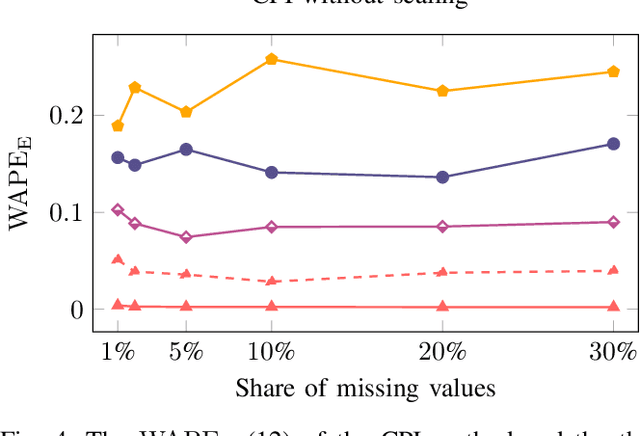
A cornerstone of the worldwide transition to smart grids are smart meters. Smart meters typically collect and provide energy time series that are vital for various applications, such as grid simulations, fault-detection, load forecasting, load analysis, and load management. Unfortunately, these time series are often characterized by missing values that must be handled before the data can be used. A common approach to handle missing values in time series is imputation. However, existing imputation methods are designed for power time series and do not take into account the total energy of gaps, resulting in jumps or constant shifts when imputing energy time series. In order to overcome these issues, the present paper introduces the new Copy-Paste Imputation (CPI) method for energy time series. The CPI method copies data blocks with similar properties and pastes them into gaps of the time series while preserving the total energy of each gap. The new method is evaluated on a real-world dataset that contains six shares of artificially inserted missing values between 1 and 30%. It outperforms by far the three benchmark imputation methods selected for comparison. The comparison furthermore shows that the CPI method uses matching patterns and preserves the total energy of each gap while requiring only a moderate run-time.