 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated generation of large-scale distribution grid models based on open data and open source software using an optimization approach
Feb 28, 2022


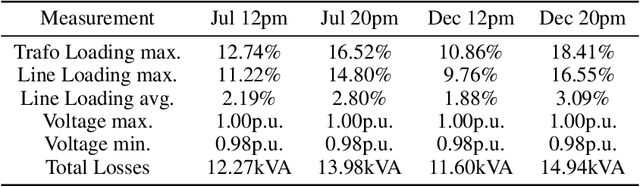
The increasing share of renewable energy sources on distribution grid level as well as the emerging active role of prosumers lead to both higher distribution grid utilization, and at the same time greater unpredictability of energy generation and consumption. This poses major problems for grid operators in view of, e.g., voltage stability and line (over)loading. Thus, detailed and comprehensive simulation models are essential for planning future distribution grid expansion in view of the expected strong electrification of society. In this context, the contribution of the present paper is a new, more refined method for automated creation of large-scale detailed distribution grid models based solely on publicly available GIS and statistical data. Utilizing the street layouts in Open Street Maps as potential cable routes, a graph representation is created and complemented by residential units that are extracted from the same data source. This graph structure is adjusted to match electrical low-voltage grid topology by solving a variation of the minimum cost flow linear optimization problem with provided data on secondary substations. In a final step, the generated grid representation is transferred to a DIgSILENT PowerFactory model with photovoltaic systems. The presented workflow uses open source software and is fully automated and scalable that allows the generation of ready-to-use distribution grid simulation models for given 20kV substation locations and additional data on residential unit properties for improved results. The performance of the developed method with respect to grid utilization is presented for a selected suburban residential area with power flow simulations for eight scenarios including current residential PV installation and a future scenario with full PV expansion. Furthermore, the suitability of the generated models for quasi-dynamic simulations is shown.
Data-Driven Copy-Paste Imputation for Energy Time Series
Jan 05, 2021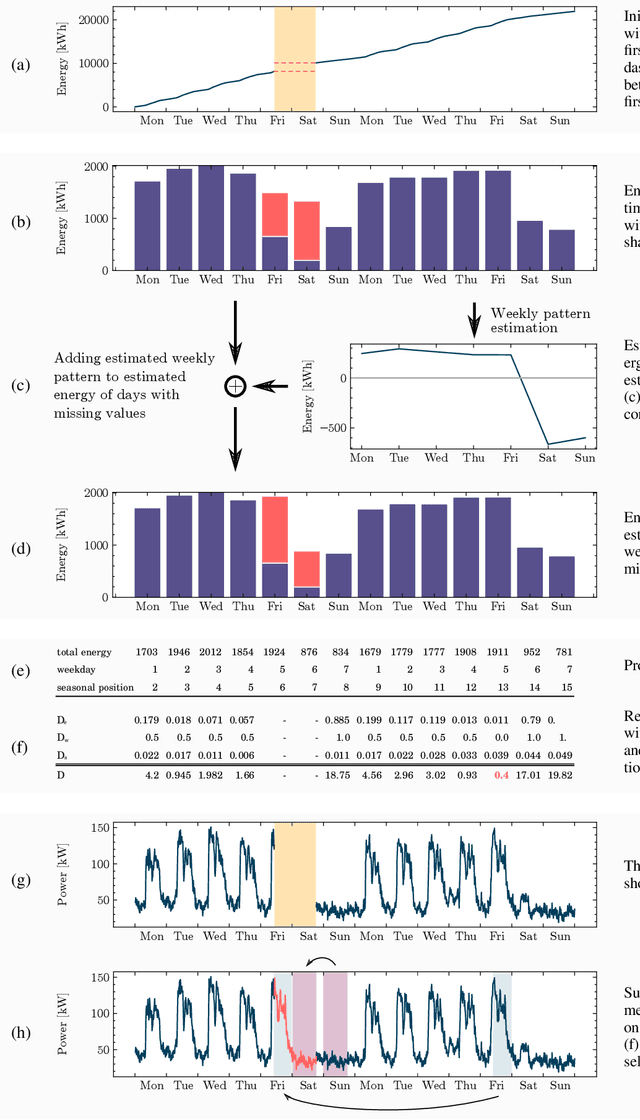
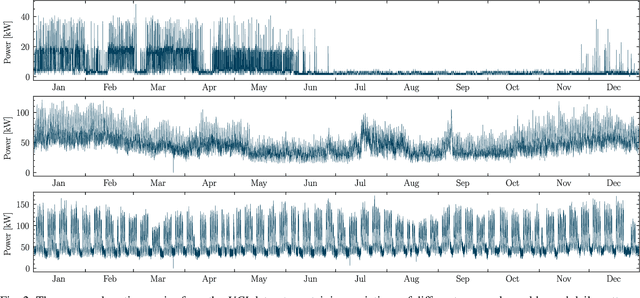
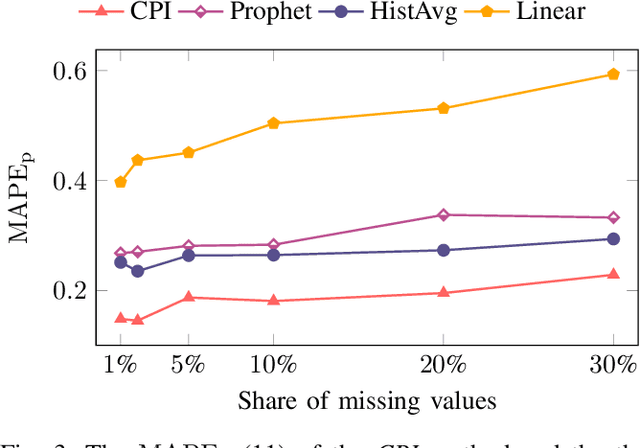
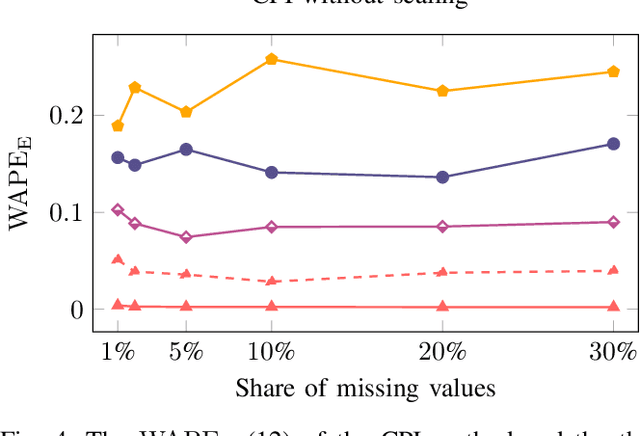
A cornerstone of the worldwide transition to smart grids are smart meters. Smart meters typically collect and provide energy time series that are vital for various applications, such as grid simulations, fault-detection, load forecasting, load analysis, and load management. Unfortunately, these time series are often characterized by missing values that must be handled before the data can be used. A common approach to handle missing values in time series is imputation. However, existing imputation methods are designed for power time series and do not take into account the total energy of gaps, resulting in jumps or constant shifts when imputing energy time series. In order to overcome these issues, the present paper introduces the new Copy-Paste Imputation (CPI) method for energy time series. The CPI method copies data blocks with similar properties and pastes them into gaps of the time series while preserving the total energy of each gap. The new method is evaluated on a real-world dataset that contains six shares of artificially inserted missing values between 1 and 30%. It outperforms by far the three benchmark imputation methods selected for comparison. The comparison furthermore shows that the CPI method uses matching patterns and preserves the total energy of each gap while requiring only a moderate run-time.