 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn autoregressive deep learning models for day-ahead wind power forecasting with irregular shutdowns due to redispatching
Nov 30, 2024



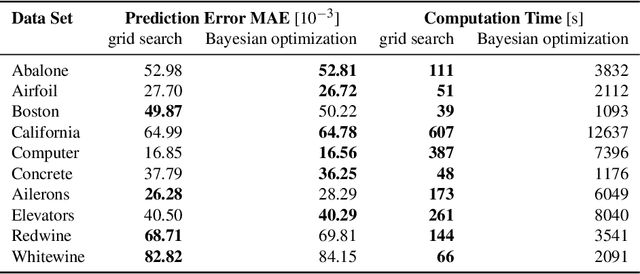
Renewable energies and their operation are becoming increasingly vital for the stability of electrical power grids since conventional power plants are progressively being displaced, and their contribution to redispatch interventions is thereby diminishing. In order to consider renewable energies like Wind Power (WP) for such interventions as a substitute, day-ahead forecasts are necessary to communicate their availability for redispatch planning. In this context, automated and scalable forecasting models are required for the deployment to thousands of locally-distributed onshore WP turbines. Furthermore, the irregular interventions into the WP generation capabilities due to redispatch shutdowns pose challenges in the design and operation of WP forecasting models. Since state-of-the-art forecasting methods consider past WP generation values alongside day-ahead weather forecasts, redispatch shutdowns may impact the forecast. Therefore, the present paper highlights these challenges and analyzes state-of-the-art forecasting methods on data sets with both regular and irregular shutdowns. Specifically, we compare the forecasting accuracy of three autoregressive Deep Learning (DL) methods to methods based on WP curve modeling. Interestingly, the latter achieve lower forecasting errors, have fewer requirements for data cleaning during modeling and operation while being computationally more efficient, suggesting their advantages in practical applications.
AutoPV: Automated photovoltaic forecasts with limited information using an ensemble of pre-trained models
Dec 13, 2022



Accurate PhotoVoltaic (PV) power generation forecasting is vital for the efficient operation of Smart Grids. The automated design of such accurate forecasting models for individual PV plants includes two challenges: First, information about the PV mounting configuration (i.e. inclination and azimuth angles) is often missing. Second, for new PV plants, the amount of historical data available to train a forecasting model is limited (cold-start problem). We address these two challenges by proposing a new method for day-ahead PV power generation forecasts called AutoPV. AutoPV is a weighted ensemble of forecasting models that represent different PV mounting configurations. This representation is achieved by pre-training each forecasting model on a separate PV plant and by scaling the model's output with the peak power rating of the corresponding PV plant. To tackle the cold-start problem, we initially weight each forecasting model in the ensemble equally. To tackle the problem of missing information about the PV mounting configuration, we use new data that become available during operation to adapt the ensemble weights to minimize the forecasting error. AutoPV is advantageous as the unknown PV mounting configuration is implicitly reflected in the ensemble weights, and only the PV plant's peak power rating is required to re-scale the ensemble's output. AutoPV also allows to represent PV plants with panels distributed on different roofs with varying alignments, as these mounting configurations can be reflected proportionally in the weighting. Additionally, the required computing memory is decoupled when scaling AutoPV to hundreds of PV plants, which is beneficial in Smart Grids with limited computing capabilities. For a real-world data set with 11 PV plants, the accuracy of AutoPV is comparable to a model trained on two years of data and outperforms an incrementally trained model.
Concepts for Automated Machine Learning in Smart Grid Applications
Oct 26, 2021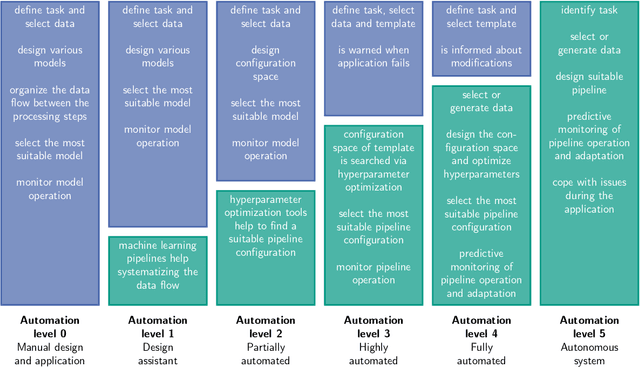
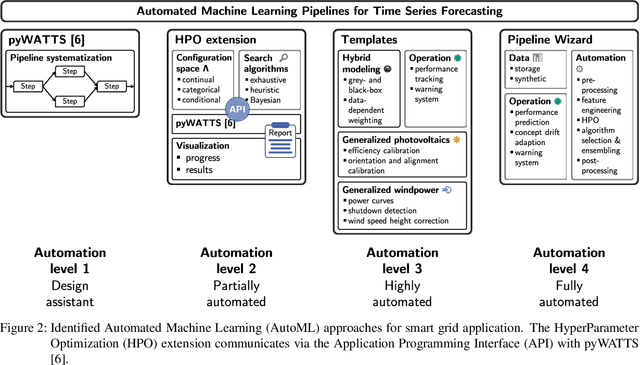
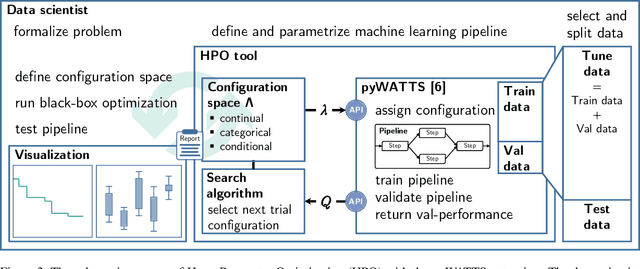
Undoubtedly, the increase of available data and competitive machine learning algorithms has boosted the popularity of data-driven modeling in energy systems. Applications are forecasts for renewable energy generation and energy consumption. Forecasts are elementary for sector coupling, where energy-consuming sectors are interconnected with the power-generating sector to address electricity storage challenges by adding flexibility to the power system. However, the large-scale application of machine learning methods in energy systems is impaired by the need for expert knowledge, which covers machine learning expertise and a profound understanding of the application's process. The process knowledge is required for the problem formalization, as well as the model validation and application. The machine learning skills include the processing steps of i) data pre-processing, ii) feature engineering, extraction, and selection, iii) algorithm selection, iv) hyperparameter optimization, and possibly v) post-processing of the model's output. Tailoring a model for a particular application requires selecting the data, designing various candidate models and organizing the data flow between the processing steps, selecting the most suitable model, and monitoring the model during operation - an iterative and time-consuming procedure. Automated design and operation of machine learning aim to reduce the human effort to address the increasing demand for data-driven models. We define five levels of automation for forecasting in alignment with the SAE standard for autonomous vehicles, where manual design and application reflect Automation level 0.